From Language Models to Models of Mind
Apr 14, 2024 by Shuo-Fu "Michael" Chen
Since OpenAI’s release of ChatGPT[1] (GPT-3.5) and GPT-4[13], evaluations of language models have shifted from using traditional linguistic metrics, such as syntactic correctness, semantic coherence, fluency, etc., to using tasks and metrics far beyond language, such as reasoning and logic, math and arithmetic, SAT and GRE, bias and discrimination, ethics and morality, wit and humor, etc. Large language models (LLMs) have acquired diverse human-like abilities with performance comparable to an average human adult, which is referred to as artificial general intelligence (AGI). This raises the questions of what constitutes general intelligence, how is general intelligence formed, and how can AGI be measured? If AGI can simply be grown out of the scale of a model and the size of the training data, it will eventually surpass human intelligence. If AGI can exceed human intelligence, how can human design an encompassing metric to evaluate an AGI that is superior to human intelligence? In hope to answer these questions, this survey reviews recent progress in building and using LLMs, with focus on key methodological advancements in three areas: (1) foundation models, (2) fine-tuning strategies, and (3) prompting strategies.
Foundation Models. Foundation model[104] refers to any model that is trained on massive, diverse datasets and can be applied to a wide range of downstream tasks; examples include BERT and GPT-3. The most consequential advancement in foundation models is the drastic scaling-up of model sizes to trillions of parameters that took thousands of GPU/TPU running continuously for a number of weeks to train. The exact sizes of commercially deployed AGI models have been withheld as trade secrets by both OpenAI and Google. Various parallelism techniques have enabled training very large neural networks over thousands of GPU/TPU, including data parallelism, pipeline parallelism, tensor parallelism, and mixture-of-experts. In addition, many memory efficient strategies, such as selective activation recomputation, mixed precision training, offloading unused data, memory efficient optimizers, and compression, have also significantly accelerated training. While training a large neural network is done by a single program, a multi-tenant capability has been developed in a large scale TPU orchestration system[24] that enables time-multiplex TPUs between concurrent programs submitted by different clients (e.g. several researchers concurrently fine-tuning a foundation model for different tasks, using the same TPUs to hold the fixed foundation model layers). Scaling law studies[14][15][13] have shown that final training loss of a foundation model follows a power relation to parameter size, number of training tokens, and training compute. For a given compute budget, the optimal token-to-parameter ratio is shown to be approximately 20, and the number of training tokens and the model size should be scaled up equally for compute-optimal training[30]. Higher training data quality also plays an important role in achieving higher performance, compared to much larger models trained with unfiltered data[44]. In addition to the drastic scaling-up, mixture of pre-training objectives (UL2 objective), from T5-like span corruption objective to GPT-like standard causal language modeling and some others in between, have been shown to significantly improve model performance[33]. When UL2 objective is used to continue training a state-of-the-art large language model for a few more steps, the scaling properties of the large language model improves substantially[60]. Large language models (LLMs) have been shown to acquire emergent abilities that are not present in smaller models[105], such as few-shot prompting, multi-step reasoning, instruction following (without few-shot exemplars), computer programs execution, and model calibration (ability to predict which questions the model will be able to answer correctly). The number of model parameters at which the abilities emerge ranges from tens of billions to hundreds of billions, dependent upon the model and the ability. On the other hand, it has been shown that publicly deployed foundation models (e.g., GPT-3.5 and GPT-4) exhibit unstable quality within a relatively short amount of time[152], where improving the models’ performance on some tasks can have unexpected side effects on their behavior in other tasks.
Fine-tuning Strategies. Unlike self-supervised learning in pre-training, fine-tuning involves supervised learning on specific tasks using small amount of data, typically < 1% of the pre-training data size and amount of compute[35]. Three fine-tuning strategies have played crucial roles in building LMs that are more suitable for public deployment: instruction tuning, reinforcement learning from human feedback (RLHF), and tool usage learning. Instruction tuning[5] refers to finetuning LMs on a mixture of large variety of (> 60) NLP tasks described via natural language instructions. The LMs learn to follow users’ instructions to perform corresponding tasks (including unseen tasks) at inference time in zero-shot scenarios (without exemplars). The performance improvement from instruction tuning is dramatically increased by increasing the number of tasks and the size of the model, as well as adding chain-of-thought datasets into the finetuning mixture[35]. However, human-written instruction-following data are costly and often limited in quantity, diversity, and creativity. These issues can be alleviated by Self-Instruct method[51], where an LLM (e.g. GPT-3) is prompted with some demonstrations of instruction-following data, sampled randomly from a small seed set of tasks, to generate new instructions and corresponding instances (inputs and outputs), with invalid and similar ones filtered out. The LLM fine-tuned by the new instruction-following data generated by itself has been shown to gain substantial performance improvement. Later studies have used stronger LLMs, such as GPT-3.5[106] and GPT-4[107], to generate instruction tuning datasets for finetuning weaker LLMs, such as LLaMA. For a general-purpose, text-based AI model to be deployed to public, its behavior needs to be aligned with (non-expert) human preferences and values (helpful, honest, and harmless) so that its negative societal impacts are alleviated[108]. Human preferences are collected from human-labeled comparisons between pairs of LM outputs, which are then used to train a separate preference model, a.k.a. reward model (RM). The RM is in turn used as a reward function in reinforcement learning[2][109] via proximal policy optimization[3] to finetune the LM to act as helpful and harmless assistants. Another important fine-tuning strategy is to train a foundation model to use specialized tools[148][78][150][153] (such as an information retrieval system, a language translator, a calculator, etc.) to improve factual groundedness, accuracy, efficiency, and automation in problem-solving.
Prompting Strategies. Prompting simply refers to using text input, at inference time, to a pretrained LM as a form of task specification[110]. The LM is conditioned on the prompt that is a natural language instruction and/or a few demonstrations of the task (a.k.a. few-shot) and is then expected to complete further instances of the task simply by predicting what comes next. The term “in-context learning” refers to developing a broad set of skills and pattern recognition abilities within the parameters of the model during pre-training and then using these abilities at inference time to rapidly adapt to or recognize the desired task specified in a prompt[110]. The “in-context learning” does not involve any parameter update (i.e. “learning”) at inference time; it is a learned ability to reason by analogy. Many human-like abilities of “in-context learning” have been discovered by complex prompting strategies that can be grouped into 5 categories:
(1) Prompting for Reasoning and Thought. A chain of thought refers to a series of intermediate reasoning steps, and chain-of-thought (CoT) prompting[29] refers to using a few chain of thought demonstrations as exemplars in prompts. CoT prompting reveals that complex arithmetic and symbolic reasoning abilities emerge naturally in sufficiently large LMs. CoT prompting uses naive greedy decoding, which may miss valid reasoning path. Self-consistency[36] decoding strategy first samples a diverse set of reasoning paths, and then selects the most consistent answer by marginalizing out the sampled reasoning paths. Self-consistency boosts the performance of chain-of-thought prompting with a striking margin on a range of popular arithmetic and commonsense reasoning benchmarks. CoT prompting tends to perform poorly on the tasks that requires solving problems harder than the exemplars shown in the prompts. To overcome the challenge of easy-to-hard generalization, least-to-most prompting strategy[111] breaks down a complex problem into a series of simpler subproblems and then solve them in sequence. Solving each subproblem is facilitated by the answers to previously solved subproblems. Least-to-most prompting has been shown to be capable of generalizing to more difficult problems than those seen in the prompts. Although original CoT prompting uses few-shot exemplars, reasoning abilities can also be elicited by simply adding “Let’s think step by step” before each answer without any examples in the prompt, which is termed Zero-shot-CoT[68]. Prompts that encourage open-ended answers are found to be more effective than prompts that restrict the model output to particular tokens[112]. This property is exploited to transform task inputs to the effective, yet imperfect, open-ended question-answering-formatted prompts by recursively using the LLM itself. The Ask Me Anything (AMA) Prompting[112] strategy applies these prompts to collect several noisy answers and then uses weak supervision to combine the several noisy answers to produce the final answer. In compositional reasoning tasks, the overall solution depends on correctly composing the answers to subquestions. The fraction of questions for which the model correctly answers individual subquestions but not the compositional question is termed the compositionality gap. To narrow the compositionality gap, self-ask prompting[113] improves upon CoT prompting by asking the model to explicitly state the next follow-up question it wants to ask before answering it, as well as inserting scaffolds like “Follow up:”. Decomposed Prompting[114] is designed to solve complex tasks by decomposing them (via prompting) into simpler sub-tasks and delegating the sub-tasks to sub-task specific LLMs, with both the decomposer and the sub-task LLMs having their own few-shot prompts. To eliminate manual efforts of hand-crafting task-specific exemplars in CoT prompting, an automatic CoT (Auto-CoT) prompting[115] method first partitions questions of a given dataset into a few clusters, and then selects a representative question from each cluster to generate reasoning chains for demonstrations one by one using Zero-Shot-CoT. To improve performance of numerical/arithmetic reasoning, program-of-thoughts (PoT) prompting[116] uses language models (mainly Codex, code-davinci-002) to express reasoning steps in programming language statements (Python programs) that can be executed by a Python interpreter, thus decoupling complex computation from reasoning and language understanding. LMs are confined to token-level, left-to-right decision-making processes during inference and can fall short in tasks that require exploration or strategic lookahead. Tree of Thoughts (ToT)[117] actively maintains a tree of thoughts, where each thought is a coherent language sequence that serves as an intermediate step toward problem solving; thus, it enables consideration of multiple different reasoning paths, evaluations of choices to decide the next action, and looking ahead or backtracking when necessary to make global choices. ToT significantly enhances language models’ problem-solving abilities on tasks requiring non-trivial planning or search. The sequential decoding of LLMs is one of the major causes of the high inference generation latency. To reduce the latency, Skeleton-of-Thought (SoT)[118] first guides LLMs to generate the skeleton of the answer, and then conducts parallel API calls or batched decoding to complete the contents of each skeleton point in parallel. To improve upon CoT and ToT, Graph of Thoughts (GoT)[119] considers the information generated by an LLM as an arbitrary graph, where units of information (“LLM thoughts”) are vertices, and edges correspond to dependencies between these vertices. GoT enables combining arbitrary LLM thoughts into synergistic outcomes, distilling the essence of whole networks of thoughts, or enhancing thoughts using feedback loops.
(2) Prompting for Iterative Self-Feedback and Refinement. To reduce the cost of manually generating intermediate reasoning (“rationales”) for CoT, the Self-Taught Reasoner (STaR)[120] iteratively bootstraps the ability of a LLM to generate high-quality rationales by first few-shot prompting the LLM to self-generate rationales and then using those rationales that lead to correct answers (and re-generated rationales from a hint of the correct answer when the model failed to reach correct answer initially) to fine-tune the LLM. STaR significantly improves performance on multiple datasets compared to a model fine-tuned to directly predict final answers, indicating that a model can improve itself by learning from its own generated reasoning. Similar self-improving capability is shown in coding LMs[121], where coding LMs are used to generate new programming puzzles and solutions and then fine-tuned by python-interpreter-verified puzzle-solution pairs. In experiments on publicly-available coding LMs, test accuracy of models fine-tuned on verified synthetic puzzles more than doubles. To generate longer stories (> 2,000 words) with better plot coherence and premise relevance, a Recursive Reprompting and Revision framework (Re\(^3\))[122] was developed by prompting a LM to construct a structured overarching plan, and generating story passages by repeatedly injecting contextual information from both the plan and current story state into a language model prompt. Different continuations are then reranked for plot coherence and premise relevance, and the best continuation is edited by an Edit module for factual consistency. Iterative refinement approach has also been applied to LLMs different from the generator, such as Self-Correction[123] approach that uses a separate corrector to iteratively correct imperfect sequence generations. To enable LLMs to learn from trial-and-error, a verbal reinforcement learning system, named Reflexion[88], is developed, which includes three distinct models: an Actor that generates text and actions; an Evaluator model that scores the outputs produced by the Actor; and a Self-Reflection model that generates verbal reinforcement cues (maintained in an episodic memory buffer) to assist the Actor in self-improvement. Reflexion obtains significant improvements over a baseline agent across diverse tasks (sequential decision-making, coding, language reasoning). It has been shown that LLMs can be fine-tuned to acquire self-critiquing ability[124] that can find errors in their own output. The self-critiquing ability has been exploited in the RCI (Recursive Criticism and Improvement)[125] prompting scheme that works by first having the LLM generate an output based on zero-shot prompting, then prompting the LLM to identify problems with the given output, and finally prompting the LLM to generate an updated output. RCI prompting outperforms CoT prompting with external feedback on a suite of reasoning tasks and RCI combined with CoT performs better than either separately. To improve the reliability of intermediate representations (inference rules, explanations, or reasoning steps) of multi-step reasoning tasks, a REFINER framework[126] has been developed, which includes two models: a generator learns to solve the task by first generating the intermediate reasoning steps, and a critic provides structured feedback to the generator about errors in the intermediate steps. The critic is independently trained with pairs of incorrect intermediate representations and structured feedback on fine-grained reasoning errors. The critic interacts with the generator LM, offering fine-grained feedback both during the training of the generator and during inference. Refiner shows significant improvements over baseline LMs of comparable scale on three diverse reasoning tasks. In SELF-DEBUGGING approach[127], a coding LLM is taught to debug its predicted program via few-shot prompting. At each debugging step, the model first generates new code, then the code is executed with unit tests, and the model explains the code. The code explanation and the execution results (when unit tests are available) constitute the feedback message, which is then sent back to the model to perform more debugging steps. The model is able to identify its mistakes by explaining the generated code in natural language and achieves the state-of-the-art performance on several code generation benchmarks. A generate-and-edit approach, named Self-Edit[128], has been developed for coding LLMs on competitive programming tasks. For a problem description in the Self-Edit, the program generated by the coding LLM is executed on an example test case and the execution results is used to construct the supplementary comments. Then, a fault-aware code editor model is trained to refine/edit the code based on the problem description, generated code, and supplementary comment. A verify-then-correct approach, named CRITIC[129], allows LLMs to verify their outputs by interacting with external tools to generate critiques and to self-correct their outputs based on the received critiques. CRITIC consistently enhances the performance of LLMs on free-form question answering, mathematical program synthesis, and toxicity reduction, highlighting the importance of external feedback in promoting self-improvement. A single coding LLM can play dual roles in a two-step code generation-refinement pipeline, as in SelfEvolve[130], where LLMs first play the role of a knowledge provider and generate corresponding knowledge from input prompts, then generate intermediate code conditioned on the knowledge; and then LLMs play the role of a self-reflective programmer to perform revision for the generated code based on the feedback (error message) thrown by the interpreter. A “scaffolding” program refers to a program (typically written by humans in a programming language such as Python) that makes multiple, structured calls to a language model to generate better outputs/solutions for some algorithmic tasks. A Self-Taught Optimizer (STOP) method[131] is developed to recursively self-improve a scaffolding program to solve problems, where the code of a seed improver program is iteratively optimized using language model calls and how well the improver’s code is optimized for downstream tasks is evaluated by a meta-utility function. With GPT-4, but not GPT-3.5, STOP improves mean downstream performance from iterations of self-improvement.
(3) Prompting for Role-Playing and Collaboration. The fact that LLMs already capture a large variety of social behaviors in their training data has been exploited in building social simulacra[133], where prompt chains[132] for the design of a social space as input to GPT-3 are used to generate a large number of member personas and a wide range of social interactions between them. To study autonomous corporation among multiple communicative agents (e.g., LLMs) for complex task-solving, a Cooperative Role-playing Communication (CAMEL)[134] framework is developed, where a role-playing session is instantiated from an idea and selected roles by humans; a task-specifier agent will provide a detailed description to make the idea specific; an AI assistant role and an AI user role will be assigned to the assistant agent and the user agent correspondingly; finally, the AI user is responsible for providing instructions, and the AI assistant is expected to respond with a solution that fulfills the instructions. An Inception Prompting is introduced, where human-crafted prompting occurs solely at the beginning of role-playing, for task specification and role assignment; then, once the conversation phase commences, the AI assistant and AI user prompt each other automatically in a loop until termination. A similar study with 25 agents, named Generative Agents[135], supplements the powerful prompting capabilities of LLMs with a long-term memory module, a reflection module, and a planning module to simulate believable human behavior. Users of the interactive simulacra can observe and intervene as agents plan their days, share news, form relationships, and coordinate group activities. It has been shown that toxicity of ChatGPT can increase up to 6x, depending on the persona assigned to it[136]. For example, significantly more toxic language can be generated using ChatGPT by setting its system parameter (i.e., persona) to that of Adolf Hitler. A 3-agent (a buyer, a seller, a critic) negotiation game has been used to study whether multiple LLMs can autonomously improve each other[137]. The results showed that only strong and well-aligned models (like GPT-4 and Claude-v1.3) can continuously improve from iterative AI feedback. An automatic and generalized prompting method, named ExpertPrompting[138], has been developed to instruct LLMs to act like distinguished experts using automatically synthesized descriptions of the expert identity for each specific instruction. ExpertLLaMA, the LLaMA trained by ExpertPrompting-elicited instruction-following data, outperforms existing open-source opponents and achieves 96% of the original ChatGPT’s capability. In contrast to elevating individuality of LLMs by role-playing in social interactions, many studies have shown that corporation between multiple instances of LLMs results in more reliable answers than those by individual instances. ChatLLM Network[139] uses a two-layer structure (3 ChatGPT3.5 in the first layer and 1 ChatGPT3.5 in the second layer) and a novel language-based feedback mechanism to optimize the network that achieves more objective and comprehensive decision-making. Inter-inconsistency (INCON)[140] among multiple LLMs, defined as the ratio of inconsistent predictions out of a test dataset, has been used to study collaboration in debate scenarios. The results show that LLMs with comparable abilities can effectively and performantly achieve a shared goal; on the other hand, for LLMs with mismatched abilities, the superior LLMs are more likely to insist on their perspectives and dominate the debate, while weaker ones are more likely to compromise and change their viewpoints. Another multi-agent debate study[141] shows that the converged single shared answer after multiple rounds of debate significantly enhances mathematical and strategic reasoning across a number of tasks, improves factual validity, and reduces fallacious answers and hallucinations. Multi-agent debate has also been used to address the Degeneration-of-Thought (DoT) problem in self-reflection[142], which is defined as once the LLM has established confidence in its answers, it is unable to generate novel thoughts later through self-reflection even if the initial stance is incorrect, by correcting and complementing the other debater, and thus encouraging divergent thinking in LLMs. To exploit the diverse strengths and weaknesses of many open-source LLMs, an ensemble method, named LLM-Blender[143], is developed to leverage different optimal LLMs for different inputs. LLM-Blender consists of two modules: a PairRanker module that ranks the two outputs generated by a pair of LLMs and determines the top-k outputs after N(N-1) iterations for N LLMs and a GenFuser module that merge the top-k output into an enhanced output as the final response. LLM-Blender significantly outperforms individual LLMs and baseline methods across various metrics, although the pairwise ranking has \(O(n^2)\) low-efficiency. MetaGPT[166] models a multi-agent system for Python program generation as a simulated software company, where each agent plays a specific role, including product manager, architect, project manager, engineer, and QA engineer, and working in a sequential manner like standard workflow in software development. Each role is specified with a profile, goal, and constraints, and initialized with specific context and skills. The communication between agents does not use natural language, but uses structured messages with role-specific schema and format, including documents and diagrams. The messages are stored in a shared global message pool and agents publish to and subscribe from the pool based on their role profiles. MetaGPT uses an executable feedback mechanism to improve code generation quality during runtime. MetaGPT achieves state-of-the-art performance on multiple collaborative software engineering benchmarks. To emulate human thinking process in solving complex reasoning problems, Cumulative Reasoning (CR) method[144] uses three distinct types of LLMs (AI Agents): a proposer that suggests the next step based on the current context, one or more verifiers that scrutinize the accuracy of the step put forward by the proposer and add correct proposition to the context, and a reporter that decides when to stop and report the solution. The interplay among the three roles in CR allows for a more effective accumulation and verification of intermediate results, facilitating a deeper and more precise reasoning process. To simulate problem-solving process of a human group as a sequence of iterative stages, AgentVerse[145], a general multi-agent framework, splits the problem-solving process into 4 stages: (1) Expert Recruitment that determines and adjusts the agent group’s composition based on the ongoing problem-solving progression, (2) Collaborative Decision-Making that engages the selected agents in joint discussions to devise problem-solving strategies, (3) Action Execution where agents interact with their environment to implement the devised actions, (4) Evaluation that assesses the differences between the current state and desired outcomes, and gives feedback to the next iteration for further refinement when the current state is unsatisfactory. A similar multi-agent collaboration system for automated task-solving, named AutoAgents[146], divides task-solving process into two stages: (1) Drafting Stage that uses three predefined agents (Planner, Agent Observer, and Plan Observer) to generate a customized agent team and an execution plan for the given task, and (2) Execution Stage that refines the plan through inter-agent collaboration and feedback, and produces the final outcome. The execution plan comprises two actions of task execution: self-refinement by a single agent and collaborative refinement by multiple agents. A predefined Action Observer acts as the team leader to coordinate the execution plan by accessing short-term memory, long-term memory, and dynamic memory based on agent units. To design a multi-agent collaboration framework that is Task Agnostic, Efficient (in reaching consensus), and capable of automatic Agent Team Optimization, Dynamic LLM-Agent Network (DyLAN)[147] framework organizes agents into a multi-layered feed-forward network with dynamic architecture by introducing inference-time agent selection and early-stopping mechanism. DyLAN includes an automatic agent team optimization algorithm based on an unsupervised Agent Importance Score. DyLAN demonstrates high accuracy, efficiency, and stability in general reasoning, arithmetic reasoning, and code generation tasks.
(4) Prompting for Integration with External Tools and APIs. Capabilities of LLMs can be greatly enhanced by accessing external tools or APIs for information retrieval and math formula calculation, as shown by the Tool Augmented Language Models (TALM)[148] that is built by finetuning pretrained T5 models (220M~3B) in an Iterative Self-Play Algorithm. A few-shot prompt-based approach named ReAct[86] has shown that LLMs (PaLM-540B) can be used to synergize between reasoning and acting (on a simple Wikipedia API) for question answering and fact verification tasks. Both finetuning-based approach and prompt-based approach continue to be used in later studies for integrating LLMs with external tools and APIs, with the former being constrained to a small set of task-specific tools and the latter being more flexible in adapting to new tools in a plug-and-play fashion. Toolformer[78] exploits the in-context learning ability of LLMs (GPT-J-6.7B) to generate a large number of potential API calls, executes these API calls, uses a self-supervised loss to filter out unhelpful API calls, and finetunes the LLM on this API calls dataset. Toolformer includes 5 tools: a calculator, a Q&A system, a search engine, a translation system, and a calendar. TRICE (Tool leaRning wIth exeCution fEedback)[156] exploits tool execution results as training data for a two-stage (instruct-tuning and reinforcement learning) training strategy to make LLMs better at deciding when to use tools and selecting the most appropriate tools for the task at hand. ART (Automatic Reasoning and Tool-use)[149] uses InstructGPT (text-davinci-002) to automatically decompose input task instance into a sequence of sub-steps, by retrieving specifically formatted demonstrations of similar task from a task library. Some of these sub-steps contain symbols corresponding to tools in a tool library (e.g. SerpAPI for Google search, Codex model for code generation, Python environment for code execution). The task and tool libraries can be updated with new demonstrations to improve performance on any specific task or to incorporate new tools, enabling easy extensibility in ART. TaskMatrix.AI[150] focuses more on a unified API documentation schema in an API platform that enables API developers to easily register, update and delete their APIs. TaskMatrix.AI consists of the following four key components: (1) Multimodal Conversational Foundation Model (GPT-4), which understands user instructions and multimodal contexts and generates executable codes. (2) API Platform, which provides storage of APIs and allows API owners to manage their APIs. (3) API Selector, which identifies and selects the most suitable APIs from API platform. (4) API Executor, which can execute the generated action codes by calling the relevant APIs and return the intermediate and final execution results. In TaskMatrix.AI, RLHF is used to finetune the foundation model and the API selector. HuggingGPT[151] focuses more on leveraging the large number of expert AI models in the public machine learning community, Hugging Face, to cooperatively solve complicated multimodal tasks. HuggingGPT uses an LLM (e.g., ChatGPT) as the core controller and the expert models as the executors in a four-staged workflow: (1) Task Planning, in which the LLM decomposes the user request into a task list and determines the execution order and resource dependencies among tasks; (2) Model Selection, in which the LLM selects appropriate models to solve the planned tasks based on the description of expert models on Hugging Face; (3) Task Execution, in which each selected model is executed and the results are returned to the LLM; (4) Response Generation, in which the LLM integrates the inference results of expert models and generates a summary of workflow logs to respond to the user. Another similar prompt-based approach named Chameleon[154] is comprised of an LLM-based planner and a module inventory that consists of a set of pre-built modules, each corresponding to a tool (13 tools of 6 tool types in the inventory). The planner is prompted with a planning task instruction, the descriptions of modules with their corresponding constraints (e.g., the concurrent relations and sequence orders of modules) for the plan generation, as well as few-shot demonstration examples. The planner then decomposes the task into a plan of sub-tasks by selecting a set of modules that can be executed sequentially to solve the task via generating a program in a natural-language-like format. The corresponding modules for each sub-task are then executed sequentially. The output of each sub-task is used to update the input and the cached information of the execution history for the next module. The output of the last module is used as the final response to the original request. Although prompt-based approach has the advantage of quick adaptability, it suffers from limited context length, making it impossible to demonstrate massive tools in the context. Furthermore, it can be challenging to master new and unfamiliar tools simply with few-shot examples. To address these limitations, ToolkenGPT[155] represents each tool as a new token (“toolken”) to augment the vocabulary, and each toolken is parameterized as a toolken embedding vector. The toolken embeddings are trained with pre-trained frozen LLMs by supervised learning on a specially designed training dataset containing toolkens placed at positions for a tool call. The training process is consistent with the inference in the “reasoning mode”, where the LLM generates text as usual, except that any plugged-in toolkens are also considered for the next token generation. Once a toolken is predicted, the LLM switches to the “tool mode”, which provides a few demonstrations of the same tool to complete the arguments. Then, the tool call is executed, and the result is sent back to the text to continue the reasoning mode until the final answer is generated. ToolkenGPT offers better grounding for 58 grounded actions and objects than previous in-context learning and specialized decoding methods. Gorilla[157] is a LLaMA-7B-based model, finetuned on a a comprehensive dataset consisting of 16,450 {instruction, API} pairs, where instructions are generated by GPT-4 using Self-Instruct paradigm[51] and 1,645 APIs are derived from the model cards of 925 models from HuggingFace, 626 models from TensorFlow Hub, and 95 models from Torch Hub. Gorilla supports two modes, with retrieval and zero-shot (without retrieval), in both training and inference. For the “with retrieval” mode, the right API is retrieved from the API database; for the “zero-shot” mode, the right API is determined by the Gorilla. LATM (LLMs As Tool Makers)[22] uses LLMs for not only utilizing tools but also creating their own reusable tools for problem-solving. LATM consists of two phases: (1) Tool Making phase employs a more powerful LLM, such as GPT-4, as the tool maker to create a generic and reusable tool, implemented as a Python function, from a few demonstrations of a task. This phase is further divided into 3 sub-stages: (i) Tool Proposing, where the tool maker attempts to generate a Python function that produces the behaviors of 3 demonstrations and makes another attempt if the proposed tool is unexecutable or encounters errors; (ii) Tool Verification, where the tool maker generates unit tests using 3 validation samples and subsequently executes these tests on the proposed tool; and (iii) Tool Wrapping, where the function code is wrapped up with demonstrations of how to convert a task into a function call and this final product is then ready for use by the tool user. (2) Tool Using phase employs a lightweight and cost-effective model, such as GPT-3.5 Turbo, as the tool user to utilize the verified tool to solve various instances of the task. To handle stream of tasks arriving in sequence, a third LLM, the dispatcher, is introduced to determine whether to engage the tool user or tool maker for each incoming task. The dispatcher maintains a record of existing tools produced by the tool maker and determines if there is a suitable tool for each incoming task. When a suitable tool exists, the dispatcher passes the task and its corresponding tool to the tool user for task resolution. If no appropriate tool is found, the new task is solved with a powerful model and the instances from a new task are then cached until sufficient cached instances are available for the tool maker to make a new tool. GPT4Tools[158] enables open-source LLMs, such as OPT-13B, LLaMA-13N, and Vicuna-13B, to use 31 multimodal tools for solving a range of visual problems, including visual comprehension and image generation. The method first constructs multimodal tool-related instruction-following dataset by prompting ChatGPT (GPT-3.5-turbo), as the teacher model, with image content and definition of tools. The dataset is then used to finetune open-source LLMs using their original auto-regressive training objective with LoRA (Low Rank Adaptation) technique[159], which freezes the pre-trained model weights and optimizes injected rank decomposition matrices of the query/key/value/output projection matrices in the self-attention module. AssistGPT[160] is a prompt-based approach to integrate LLMs with 13 multi-modal tools, which consists of 4 collaborating parts: Planner, Executor, Inspector, and Learner (PEIL). The Planner, implemented with GPT-4 API, takes inputs from an Instruction Prompt (consisting of the [Tool Set Illustration] and [In-Context Example]), Input Query, and the Summary of Visual Input (created by Inspector), and then generates an appropriate output for the next step, which consists of Thought (a language phrase indicating what should be done next) and Action (a string following the code-style template Module_Name(<text_query>, <visual_index>) to specify which external tool to call and what arguments to provide). The Executor takes the Action as input, then call a module to produce the output in 3 steps: (1) Validation Check, which determines whether the Action is executable and returns an error message if the Action includes errors; (2) Module Execution, which uses a simple rule-based function to map Action to executable codes and executes it to obtain the final result; (3) Post-processing, which translates the final result into natural language format that is referred to as Observation and sends intermediate results, such as segmented video or cropped image region, to the subsequent visual outcome manager (i.e. Inspector). The Inspector records the metadata of each visual element, which includes its type (image or video), source (provided by the user or generated by the system), a brief description of the content (obtained from the caption model, or the title of an online video), and, for video, the duration and whether it contains audio and subtitles. The Inspector also generates a Summary from the metadata of the intermediate outcome and appends it to the reasoning history of the Planner. The Learner includes an evaluator implemented by the LLM, which operates in two modes: self-assessment mode (activated when there is no user feedback or ground truth) and ground-truth comparison mode (activated when ground truth is available). Self-assessment mode takes the reasoning trace and the results of each step as input and assesses whether the reasoning is complete, consistent, and adhere to the required format. Ground-truth comparison mode evaluates whether the AssistGPT’s prediction is semantically consistent with the provided ground truth. When the response is not satisfactory, AssistGPT will repeatedly attempt to provide the answer until either passes the self-check, or correct answer is given or a predefined maximum number of attempts is reached. ToolLLM[161] is a general tool-use framework of data construction, model training and evaluation to facilitate tool-use capabilities of open-source LLMs. An instruction tuning dataset, ToolBench, for tool learning is constructed in 3 stages: (1) API collection, (2) instruction generation, and (3) solution path annotation. APIs listed on RapidAPI are filtered for reliability and functionality to retain 3,451 high-quality tools, covering 16,464 APIs. During inference, when the API response length exceeds 2048 tokens, the response is compressed by removing unimportant information and the compressed response is truncated if it is still longer than 2048 tokens. ChatGPT is used to generate instructions and instruction-relevant API pairs using prompts composed of a description of instruction generation task, documentation of each API in a sample of a few APIs, and 3 seed examples randomly sampled from 12 or 36 diverse expert-written examples for single-tool or multi-tool settings, respectively. For multi-tool settings, 2~5 tools from the same category or collection are randomly selected and at most 3 APIs from each tool are sampled to generate intra-category multi-tool instructions or intra-collection multi-tool instructions. After filtering out hallucinated relevant APIs, over 200k qualified instruction-relevant API pairs are collected. For a given instruction, ChatGPT is prompted to search for a valid action sequence, in which, for each action, ChatGPT is prompted to specify which API to use, the specific parameters for an API call, and its “thought”. Leveraging the function call feature of GPT-3.5-Turbo-16K, each API is treated as a special function and its documentation is fed into the ChatGPT’s function field. To expand the exploration of the action space and increase the possibility of finding a valid solution path, a pre-order traversal for a depth-first search-based decision tree is performed to find a valid action sequence. The instruction-solution pairs are used to fine-tune LLaMA 7B model with a context length of 8192 in a multi-round conversation mode to obtain ToolLLaMA. An API Retriever that can retrieve relevant APIs for a given instruction is trained on instruction-relevant API pairs based on BERT-BASE model, which encodes the instruction and API document into two embeddings and determines the relevance of the two by the similarity of these two embeddings. CRAFT[162] is another general tool creation and retrieval framework for LLMs, which constructs a toolset through 4 steps: Generation, Abstraction, Verification, and Deduplication. The Generation step first samples a diverse set of problems from a training dataset of problem-answer pairs, using min-max strategy on sentence embeddings encoded by SimCSE; then, for each problem, GPT-4 is prompted to generate a specific Python solution. The code solutions that produce incorrect outputs are discarded. The Abstraction step aims to promote reusability by instructing GPT-4 to replace all specific variable names with general ones and wrap textual inputs of internal function calls as arguments of the tool, substituting them with more generic counterparts to adapt to similar problems. In addition, GPT-4 is instructed to assign a suitable and general function name and compose a corresponding docstring to elucidate the functionality of created tools. In the Validation step, GPT-4 is used to access the abstract tool function and the tools that fail to derive the correct answers given the original problems are discarded. In the Deduplication step, tools with the same function names and the number of input arguments are deduplicated to only keep the most comprehensive one. At inference time, CRAFT retrieves tools based on multi-view matching, where an evaluated LLM is asked to generate the function names and the docstrings based on the target problem; and then three lists of tools are retrieved from CRAFT toolset based on the similarity between two SimCSE embeddings of function name, docstring, and problem, respectively. The three lists are then aggregated and ranked by their frequency of occurrences; and the top three most frequent tools are retrieved. The retrieved tools that occur only once are filtered out. If the retrieved tool set is empty, then LLMs would directly perform code generation to solve question without invoking task-specific tools. After retrieval, the code snippets of tools are added to the prompt of LLMs for code generation to solve a given question. The retrieved tool functions and LLM-generated code solutions are instantiated into executable code that are executed to obtain the final predictions. Ablation studies showed that CRAFT implemented with more powerful backbone model (GPT-4) substantially outperforms CRAFT implemented with weaker model (GPT-3.5-Turbo); and the performance of CRAFT improves as the toolset size scales up (e.g. from 261 to 525).
(5) Automated Prompting by Autonomous Agents. Prompting can be automatically generated and/or optimized by autonomous agents that are software systems designed to automate task-planning, decision-making, and action-execution when interacting with LLMs and other tools. Autonomous agent approach has been applied in exploring the four aspects of AGI systems described above, such as Auto-CoT[115] for reasoning, Relexion[88] for self-reflection, AutoAgents[146] for multi-agent collaboration, and ART[149] for reasoning and tool-use. Although some studies continue to focus on building autonomous agents optimized for a domain-specific task, more studies have aimed at building task-agnostic and broadly capable autonomous agents. LLM-powered autonomous web navigation on real-world websites has been challenging due to open-ended action space and long and messy HTML documents. To address these issues, WebAgent[164] combines two LLMs: HTML-T5 that decomposes instructions into canonical sub-instructions and summarizes long HTML documents into task-relevant snippets and Flan-U-PaLM[35] that generates Python programs for browser actions. HTML-T5 is based on LongT5[165], an encoder-decoder Transformer, but pre-trained on a CommonCrawl HTML corpus using local and global attention in the encoder and dense attention in the decoder, with a mixture of longer-mean span denoising objectives to capture the hierarchical structures of HTML documents. It is then finetuned with demonstrations of planning sub-instructions on real websites. HTML-T5 takes task instructions, sub-instruction histories, and raw HTML as inputs, and then predicts the next sub-instruction and the corresponding data-ref attributes to extract the HTML snippet with XPath. Flan-U-PaLM-540B takes the predicted next sub-instruction and extracted HTML snippet from HTML-T5 and a few canonical examples for program generation as input and generates an executable Python program using Selenium WebDriver, a library for browser automation. WebAgent achieves around 70% success on real websites outperforming single LLM approach by over 50%. AGENTS[168] is designed to make it easy for developers to build LLM-powered applications with features including memory, tool usage, multi-agent communication, and fine grained symbolic control. AGENTS stores long-term memories of action histories embedded by sentence-transformers in a VectorDB, which is queried via semantic search. AGENTS maintains short-term memories in natural language form and updates it by an LLM via a carefully tuned prompt. Users can choose to equip an agent with long-term memory, short-term memory, or both by simply filling in a field in the config file. For each external tool or API, developer can wrap the API call in AGENTS’ ToolComponent.func() method. For context-dependent API call, AGENTS integrates the “Function-calling” feature of OpenAI’s GPT APIs to let LLMs decide how to use the tools. Web navigation is achieved by implementing web search as a specialized tool. For multi-agent communication, AGENTS uses a controller function that dynamically decides which agent will perform the next action using an LLM by considering the previous actions, the environment, and the target of the current states. For human-agent interaction, human users can play the role of an agent by changing the “is_human” field in the agent’s config file to “True”, and then, interact with other language agents in the environment by inputting his/her own actions. AGENTS controls an agent’s behavior using a symbolic plan, named as standard operating procedures (SOPs), which is a graph of multiple states that defines different situations an agent may encounter while accomplishing a task, and the transition rules between the states. An SOP in AGENTS is a set of step-by-step instructions that outlines how a particular task or process should be performed by an agent or a group of agents. SOPs can be automatically generated by an LLM and then edited by the user when customizing and tuning the agent. To avoid manual trial and error in hand-crafting prompt template for in-context learning, DSPy[163] introduces a more systematic approach, a programming model, of building AI pipelines, which abstracts LM pipelines as text transformation graphs that are built by composing modular operators and compiled to generate optimized prompts and LM invocation strategies. DSPy programs are expressed in Python, in which each program takes the task input and returns the output after a series of steps. Three DSPy abstractions contribute toward automatic optimization: signatures, modules, and teleprompters. A DSPy signature is natural-language typed declaration of a function, including input fields, output fields, and an optional instruction. To use a signature, a module must be declared with that signature and the declared module returns a function having that signature. DSPy has a few built-in modules: Predict, ChainOfThought, ProgramOfThought, MultiChainComparison, and ReAct, which can all be used interchangeably to implement a DSPy signature. A teleprompter is an optimizer that takes the given DSPy program, a training set, and a metric and returns a new optimized program. Teleprompters are invoked when compiling DSPy programs and different teleprompters use different strategies for optimization, such as sampling best demonstrations or finetuning a LM. In two case studies, Math Word Problems and Complex Question Answering, DSPy has been shown to support rapid development of highly effective systems using relatively small LMs, such as T-5 770M and Llama2-13B-Chat. OpenAgents[169] is an open-source platform for general users to interact with its agents via an online web UI, for developers to easily deploy it locally for further development, and for researchers to build new agents or agent-related methods given the examples and shared components. The OpenAgents architecture is composed of two parts: (1) User Interface, including both the frontend and backend for user-agent communication; (2) Language Agent, including language models, tool interface (for translating model outputs into executable actions), and environments (for actions execution). Three distinct agents are built in OpenAgents: Data Agent for data analysis, Plugins Agent for plugin integration, and Web Agent for autonomous web browsing. The DataAgent can generate and execute code in Python and SQL, and can use data tools, such as Kaggle Data Search, Data Profiling, and ECharts Tool, to proficiently perform data queries, visualization, manipulation tasks, etc. The Plugins Agent includes over 200 plugins, including Google Search, Wolframe Alpha (computational knowledge engine), Zapier (an online automation tool that connects apps and services), Klarna (online financial services), Coursera, Show Me (online learning), Speak (language learning), AskYourPDF, etc. The Plugins Agent has incorporated a feature that automatically selects the most relevant plugins based on the user instructions. The Web Agent is composed of a chat agent and a web-browsing agent, where the chat agent decomposes user inquiries into sub-tasks to be resolved sequentially by the web-browsing agent. TaskWeaver[167] uses LLM-powered autonomous agents to conduct anomaly detection on time series data stored in a SQL database. TaskWeaver consists of 3 key components: the Planner, Code Generator (CG), and Code Executor (CE). The Planner decomposes user requests into subtasks, manages the execution process with self-reflection, and transforms execution results into human-readable response for users. The CG generates Python program for each subtask, by treating user defined plugins as callable functions and using examples within the CG for domain-specific tasks unfamiliar to the LLM. The CE is responsible for executing the generated code and maintaining the execution state throughout the entire session. TaskWeaver provides support for rich data structures, such as pandas DataFrame. Plugins are specialized Python functions to handle tasks that are either too complex or require specific domain knowledge. TaskWeaver features dynamic plugin selection, which selects only the plugins that are relevant to user requests. TaskWeaver provides an interface for users to configure examples to teach the LLM, in Planner or CG, how to respond to certain requests. Meta-Prompting[170] is a prompting strategy that uses the same LLM, such as GPT-4, to function as both a conductor and a diverse panel of experts that are distinguished by their respective instructions in their prompts. Meta-prompting technique combines and expands upon various prompting ideas, including high-level planning and decision-making, dynamic persona assignment, multi-agent debating, and self-debugging and self-reflection. When presented with a query, the LLM serves as a conductor, also called Meta Model, that is instructed by a “meta” prompt to: (i) break down complex tasks or problems into smaller, manageable pieces; (ii) assign these pieces to specialized “expert” models with proper and detailed natural-language instructions; (iii) oversee the communication between these expert models; and (iv) apply its own critical thinking, reasoning, and verification skills throughout the process. The conductor also produces a message history, comprising the selection of experts, the formulation of specific instructions for them, and the responses from them. Meta-prompting is task-agnostic, meaning it employs the same set of high-level instructions across various tasks and inputs, instead of specific instructions or examples tailored to each task. Meta-prompting also includes the functionality of invoking a Python interpreter for real-time code execution. Experts can be called only by the Meta Model; they cannot directly interact or communicate with each other, though the Meta Model can choose to share some text from or combine the insights of various experts when interacting with a new expert. The algorithmic procedure of meta-prompting starts with transforming the raw query into the input for the Meta Model, then iterates in a loop of prompting the Meta Model, engaging domain-specific expert models or returning the final response or error handling. Meta-prompting, augmented with a Python interpreter functionality, surpasses standard prompting by 17.1%, expert (dynamic) prompting by 17.3%, and multipersona prompting by 15.2%, on macro-averaged performance across 8 diverse tasks. Meta-prompting is better at the type of tasks that require complex, iterative, and heuristic search strategies, as well as task that demands linguistic precision and creative conformity to specific writing structure. The success of meta-prompting framework can be attributed to its strategic use of specialized knowledge, self-collaboration, multipersona prompting, and implicit verification loops. Meta-prompting incorporates fresh perspectives at each step by prompting experts without including the whole history; thus, it may lead to more creative problem-solving and error detection, and may help avoid cognitive biases such as anchoring, confirmation bias, as well as overconfidence. Python Expert’s real-time code execution capability is shown to contribute significantly to the performance of meta-prompting on various computational tasks, but its deployment should be fortified with a secure sandbox to mitigate risks such as data breaches and system vulnerabilities. On the other hand, meta-prompting framework encounters several notable limitations: (1) extensive calls & long context of history using GPT-4 incur substantial costs; (2) requirements for large scale & long context window are limited to very powerful LLM, such as GPT-4; (3) multiple steps in meta-prompting are sequential, not parallelizable, processes, impacting the speed and efficiency of the system; (4) meta-prompting is confined within a closed-domain system without incorporating external resources; (5) meta model occasionally sends nonconforming message to expert model, leading to unintended confusion; (6) meta model’s response pattern often includes apologies, particularly in tasks with lower performance.
The multifaceted nature of AGI is now well-documented, including some opposing facets, such as factual groundedness vs creativeness. Thus, it is challenging to come up with a single aggregated metric for AGI. In practice, it would be more beneficial to use a panel of AGIs, where the best-matching AGI will be automatically selected for the given task or subtask that can leverage its strength.
Postulate of General Intelligence Formation. General intelligence can be formed in a conditional language generation system by training it with sufficiently large amount of high-quality knowledge to perform well above average human adult on all the tasks required for intelligence evaluations.
OpenAI
In just a little over two months, ChatGPT has attracted more than 100 million subscribers, and has been described as the fastest growing web platform ever, leaving behind Instagram, Facebook, Netflix and TikTok[16].
InstructGPT
Ouyang et al. (2022)[2] introduced InstructGPT models to align GPT-3 language models with the objective of following user’s instructions helpfully and safely, by fine-tuning GPT-3 models using deep reinforcement learning from human feedback. The training process consists of 3 steps, as illustrated in the Figure below. In step 1, a dataset of (prompt, desired output) written by 40 human labelers are collected and used to fine-tune GPT-3 with supervised learning. In step 2, a comparison dataset of (prompt, several model outputs) are sampled, ranked by labelers, and used to train a reward model (RM). In step 3, the proximal policy optimization (PPO)[3] algorithm of reinforcement learning is used to fine-tune the policy that is initialized with the model obtained in the step 1 and the state-value function that is initialized with the RM model obtained in the step 2. Steps 2 and 3 can be iterated continuously; more comparison data is collected on the current best policy, which is used to train a new RM and then a new policy. In practice, most of the comparison data comes from the initial supervised policy, with some coming from the PPO policies.
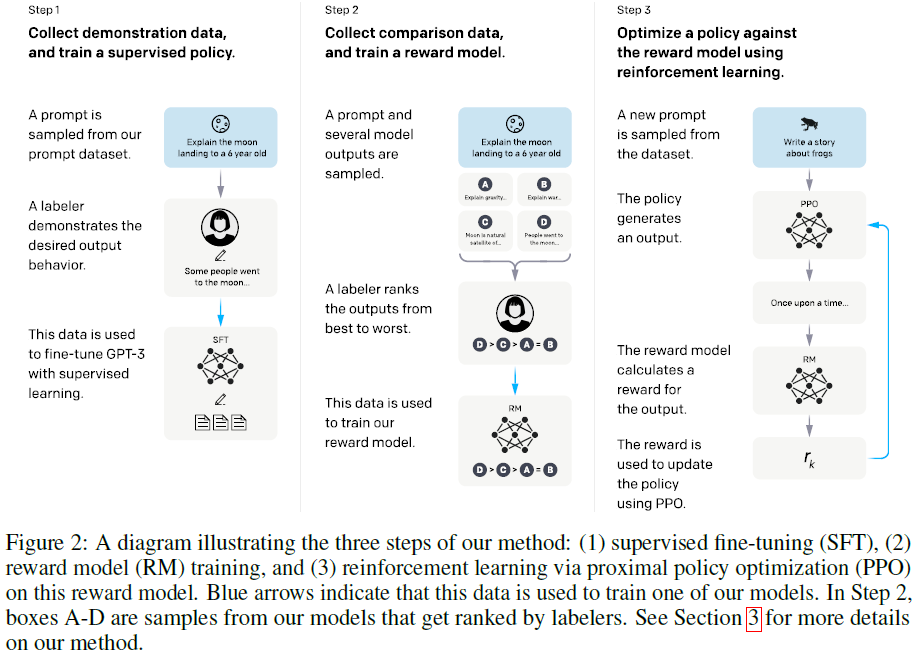
Data
The prompt dataset consists primarily of text prompts submitted by customers to the OpenAI API running an earlier version of the InstructGPT models. The prompts are deduplicated heuristically by checking for prompts that share a long common prefix, and the number of prompts per user ID is limited to 200. The train, validation, and test splits are created based on User ID. All prompts in the training split are filtered for personally identifiable information (PII), to avoid the models learning sensitive customer details. An initial source of instruction-like prompts was written by labelers to bootstrap the process of training the very first InstructGPT models, which include 3 kinds of prompts: (1) Plain \(\doteq\) an arbitrary task to ensure sufficient diversity, (2) Few-shot \(\doteq\) an instruction and multiple query/response pairs for that instruction, (3) User-based \(\doteq\) prompts corresponding to use-cases stated in waitlist applications to the OpenAI API. The distribution of use case categories and some illustrative prompts from the API prompt dataset are shown in the Tables below.
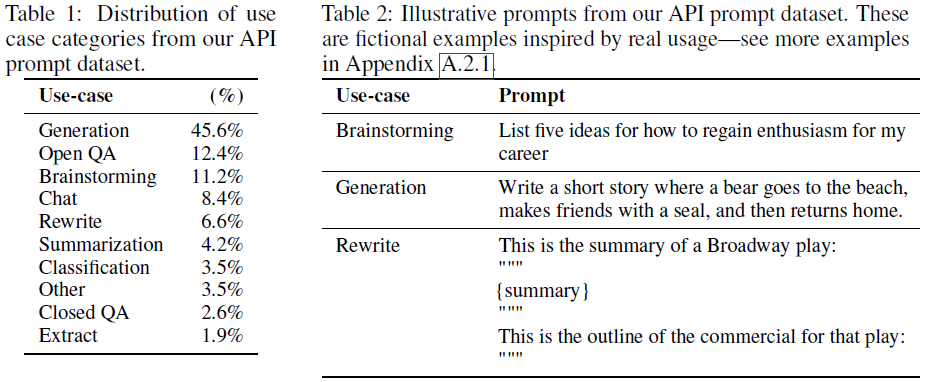
The prompt dataset is used to produce 3 different datasets for fine-tuning procedure: (1) the supervised fine-tuning (SFT) dataset, with labeler demonstrations used to train the SFT models, (2) the RM dataset, with labeler rankings of 4~9 model outputs per prompt used to train the RMs, and (3) the PPO dataset, with customer data from the API only, which are used as inputs for RLHF fine-tuning. The number of prompts in the training splits of the 3 datasets are 13k, 33k, and 31k, respectively. For the RM, the \(K\) outputs per prompt produce \(\binom{K}{2}\) number of ranked pairs per prompt. In writing responses, the labelers are asked to do their best to infer the intent of the user who wrote the prompt, to skip very unclear inputs, to take into account the implicit intentions such as truthfulness of the response and potentially biased, harmful, or toxic outputs, and to refuse to answer certain instructions.
Model
All model architectures in this paper use the GPT-3 architecture. For the reward models and value functions, the unembedding layer of the original model is replaced with a projection layer to output a scalar value. All the language models and RL policies have a context length of 2k tokens. Prompts that are longer than 1k tokens are filtered out and the maximum response length is limited to 1k tokens. All models use fp16 weights and activations and are trained with the Adam optimizer, with \(\beta_1=0.9\) and \(\beta_2=0.95\). Three model sizes (1.3B, 6B, and 175B parameters) are trained. Supervised fine-tuning (SFT) is done by fine-tuning GPT-3 model on labeler-written responses for 16 epochs, using a cosine learning rate decay, and residual dropout of 0.2. The final SFT models are selected based on the RM score on the validation set, which is more predictive of human preference than validation loss.
For an introduction to reinforcement learning and policy gradient methods, see the textbook by Sutton and Barto[4], especially the chapters 3 and 13. In the setting of a chatbot, human interaction is the environment. The policy model receives an input from the environment and constructs a response by iteratively choosing an action as the next token. In this paper, the chatbot’s response, along with its prompt, is used to compute a reward signal to train the model. The state of the environment is all the text in the conversation uttered by both sides so far. The value function estimates future reward for the next token in the utterance. Actor-Critic methods train both policy and value function simultaneously. The last token of a bot’s utterance signals the end of an episode and the response, along with its prompt, is used to compute a new reward signal for the next cycle. User’s response to a bot’s response will be appended to the bot’s response and be used as a new prompt for the next cycle. The PPO methods have the stability and reliability of earlier policy gradient methods, but are much simpler to implement, more compatible with architectures that include dropout or parameter sharing, and have better data efficiency[3].
The RM is initialized from a 6B SFT model with the final unembedding layer replaced by a scalar reward output layer. Only a single 6B RM is used for all PPO models of all sizes. It is trained for a single epoch over the full reward model training set. For two model outputs on the same input, the difference in rewards represents the log odds that one output will be preferred over the other by a human labeler. The labeler preferences on each pair of outputs are used as label for the training. The loss function for the RM is: \(\mathrm{loss}(\theta)=-\frac{1}{\binom{K}{2}}E_{(x,y_w,y_l)\sim D}[\log(\sigma(r_{\theta}(x,y_w)-r_{\theta}(x,y_l)))]\), where \(r_{\theta}(x,y)\) is the scalar output of the RM for prompt \(x\) and response \(y\) with parameters \(\theta\), \(y_w\) is the preferred response out of the pair of \(y_w\) and \(y_l\), and \(D\) is the dataset of human comparisons. Minimizing the loss is equivalent to maximizing the difference of the two scalar outputs, \(r_{\theta}(x,y_w)-r_{\theta}(x,y_l)\). All \(\binom{K}{2}\) comparisons of the \(K\) responses from each prompt are trained in the same batch. Thus, a batch size of 64 could contain up to \(64\times\binom{K}{2}\leq2,304\) comparisons for \(K=4\sim9\). This is much more computationally efficient because it only requires a single forward pass of the RM for each response (rather than \(\binom{K}{2}\) forward passes for \(K\) responses) and, because it avoids overfitting, it achieves much improved validation accuracy and log loss. Finally, since the RM loss is invariant to shifts in reward, the reward model is normalized using a bias so that the labeler demonstrations achieve a mean score of 0 before doing RL.
The RLHF models are initialized from a pretrained GPT-3 model that has been supervised fine-tuned for 2 epochs on the demonstration dataset. The value function is initialized from the RM. These models are called “PPO”. To mitigate performance regressions on public NLP datasets, such as SQuADv2 and DROP, 10% of the fine-tuning data are randomly drawn from pretraining data of the GPT-3, which is called PPO with pretraining data mix (PPO-ptx). The RL policies are initialized from the PPO-ptx. In addition, a per-token KL penalty from the SFT model is added at each token to mitigate over-optimization of the reward model. The RL training is to maximize the following combined objective function:
\[\mathrm{objective}(\phi)=E_{(x,y)\sim D_{\pi_{\phi}^{\mathrm{RL}}}}[r_{\theta}(x,y)-\beta\log(\pi_{\phi}^{\mathrm{RL}}(y\vert x)/\pi^{\mathrm{SFT}}(y\vert x))]+\gamma E_{x\sim D_{\mathrm{pretrain}}}[\log(\pi_{\phi}^{\mathrm{RL}}(x))]\]where \(\pi_{\phi}^{\mathrm{RL}}\) is the learned RL policy, \(\pi^{\mathrm{SFT}}\) is the supervised trained model, and \(D_{\mathrm{pretrain}}\) is the pretraining distribution. The KL reward coefficient, \(\beta=0.02\), and the pretraining loss coefficient, \(\gamma=27.8\), control the strength of the KL penalty and pretraining gradients, respectively. For “PPO” models, \(\gamma\) is set to 0. In this paper, InstructGPT refers to the PPO-ptx models, unless otherwise specified.
All the RL models are trained for 256k episodes. These episodes include about 31k unique prompts, after filtering out prompts with PII and deduplication based on common prefixes. The batch size for each iteration is 512, with a minibatch size of 64. In other words, each batch is randomly split into 8 minibatches and is trained on for only a single inner epoch. No discount is applied when estimating the generalized advantage. The PPO clip ratio is set to 0.2, and the sampling temperature is 1 for rollouts.
For all PPO models, a 6B value function is initialized from a 6B RM. By using the same 6B reward model and value function on policies of all model sizes, it’s easier to compare the effect of policy model size on policy performance. For each minibatch, the PPO gradients and pretraining gradients are computed in consecutive steps and accumulated into their respective gradient buffers.
The SFT and GPT-3 models are used as baselines for performance comparison with PPO models. A GPT-3-prompted mode is also compared, which is provided with a few-shot prefix to prompt it into an instruction-following mode. An additional 175B GPT-3 is fine-tuned on the FLAN[5] and T0[6] datasets, which both consist of a variety of NLP tasks with natural language instructions for each task (the two differ in the NLP datasets included, and the style of instructions used). The fine-tuning was done on approximately 1 million examples respectively and the checkpoint with the highest RM score on the validation set was chosen.
Evaluation
To evaluate how aligned a language model is with user intentions, this paper adopts the definition that a model is aligned if they are helpful, honest, and harmless. The main metric for helpfulness is labeler preference ratings. However, since the labelers are not the users who generated the prompts, there could be a divergence between what a user actually intended and what the labeler thought was intended from only reading the prompt. For honesty, this paper measures truthfulness instead, using two metrics: (1) evaluating the model’s tendency to make up information on closed domain tasks (“hallucinations”), and (2) using the TruthfulQA dataset. These only captures a small part of what is actually meant by truthfulness. To measure harms, a suite of proxy criteria are used: labeler evaluation on whether an output is inappropriate in the context of a customer assistant, denigrates a protected class, or contains sexual or violent content. Benchmark datasets, such as RealToxicityPrompts[7] and CrowS-Pairs[8], are also used to measure bias and toxicity.
Evaluations on API Distribution
The main metric of this paper is human preference ratings on a held out set of prompts submitted by the customers not included in training. The prompts designed for InstructGPT may not be understood by GPT-3 baselines; thus, prompts submitted specifically to GPT-3 models on the API, generally not in an ‘instruction following’ style, are also evaluated. In both cases and for each model, how often its outputs are preferred over a baseline policy (win rate against 175B SFT model) is calculated. Additionally, the overall quality (on a 1-7 Likert scale) and 11 binary metadata (e.g. inappropriate, hallucination, harmful, sexual, violent, etc.) of each response from each model are judged by human labelers.
Evaluations on Public NLP Datasets
Two types of public NLP datasets are used for automatic evaluation: (1) those that capture an aspect of language model safety, particularly truthfulness, toxicity, and bias, and (2) those that capture zero-shot performance on traditional NLP tasks like question answering, reading comprehension, and summarization. RealToxicityPrompts dataset is used for both automatic evaluations and human evaluations. In the latter, human labelers rate toxicity (scale in 0, 1, 2), relative toxicity (scale in -1, 0, 1), and continuity (scale in 1, 4, 7).
Results
The win rate against baseline shows the order at the same model size on all three model sizes (1.3B, 6B, 175B): PPO-ptx \(\approx\) PPO \(>\) SFT \(>\) GPT-3 prompted \(>\) GPT-3. Human preference of 1.3B PPO-ptx and PPO models are significantly higher than those of the 175B GPT-3 models. The computational cost of training the 175B SFT and 175B PPO-ptx models are 0.13% and 1.65% of the cost of pretraining GPT-3, respectively. There is no significant difference between results from InstructGPT prompts and those from GPT-3 prompts.
Compared to GPT-3, InstructGPT outputs are more appropriate in the context of a customer assistant, more often follow explicit constraints defined in the instruction (e.g. “Write your answer in 2 paragraphs or less.”), are less likely to fail to follow the correct instruction entirely, and make up facts (‘hallucinate’) less often in closed-domain tasks. Other 7 metadata categories occur too infrequently in the OpenAI API to obtain statistically significant differences between the models.
Held-out labelers’ ranking preferences, InstructGPT models greatly outperforming the GPT-3 baselines, are similar to those of training data labelers, indicating that the reward models can generalize to the preferences of held-out labelers. This generalization capabilities of the reward models are further supported using a 5-fold cross validation experiments by splitting labelers into 5 groups and training on 4 groups and evaluating on the held-out group.
The overall quality measured using Lickert score on a 1-7 scale is in the order: PPO-ptx \(>\) SFT \(>\) GPT-3 prompted \(\approx\) GPT-3 fine-tuned on the FLAN \(\approx\) GPT-3 fine-tuned on the T0 \(>\) GPT-3. This indicates that FLAN and T0 datasets are not sufficiently diverse to improve performance on the API prompt distribution. The better performance of InstructGPT over FLAN and T0 is attributed to two reasons: (1) The two datasets are designed for classification, question answering, and to a certain extent, summarization and translation tasks, which only constitute a small part (\(<25\%\)) of the API prompt use case distribution, whereas open-ended generation and brainstorming consist of about 57% of the prompt dataset. (2) Public NLP datasets are not sufficiently diverse to cover real-world user inputs.
Human evaluations on the TruthfulQA dataset show that PPO models slightly but significantly improve truthfulness and informativeness over GPT models of the same size (except 1.3B PPO-ptx) when only QA prompts are used. When using a “Instruction+QA” prompt that instructs the model to respond with “I have no comment” when it is not certain of the correct answer, the improvement on truthfulness and informativeness of PPO over GPT is greatly increased. The improvements in truthfulness are also evidenced by the fact that the PPO models hallucinate (i.e. fabricate information) less often on closed-domain tasks from the API distribution.
Toxicity is evaluated on RealToxicityPrompts dataset in two ways: (1) model samples are run through the Perspective API to obtain a toxicity score, and (2) model samples are sent to human labelers to obtain ratings on absolute toxicity, toxicity relative to the prompt, continuity, and overall output preference. Prompts from the RealToxicityPrompts dataset are uniformly sampled according to prompt toxicity. In both ways, InstructGPT models generate less toxic outputs than GPT-3 models, when instructed to produce a safe and respectful output (“respectful prompt”); but InstructGPT models generate similar amount of toxic outputs as GPT-3 models, when the respectful prompt is removed (“no prompt”). When explicitly prompted to produce a toxic output (“biased prompt”), InstructGPT outputs are much more toxic than those from GPT-3.
Stereotyping biases are evaluated by pairs of sentences from CrowS-Pairs and Winogender datasets, in which one sentence is more biased and the other is less biased. A model’s relative probabilities of producing the sentence in each pair and the entropy (in bits) of the associated binary probability distributions are calculated. Perfectly unbiased models will have no preference between the sentences in each pair and will therefore have maximum entropy. By this metric, the PPO-ptx model shows similar bias to GPT-3, but when instructed to act respectfully it exhibits lower entropy and thus higher bias.
When a PPO model is trained on the API distribution, its performance on several public NLP datasets decreases. This performance regression is termed “alignment tax”. Adding pretraining updates to PPO fine-tuning (PPO-ptx) mitigates these performance regressions on all datasets, and even surpasses GPT-3 on HellaSwag. The performance of the PPO-ptx model still lags behind GPT-3 on DROP, SQuADv2, and translation. Mixing in pretraining updates performs better than the simpler solution of increasing the KL coefficient.
InstructGPT shows ability to follow instructions outside the RLHF fine-tuning distribution: to follow instructions in non-English languages, and perform summarization and question-answering for code. Because non-English languages and code form a tiny minority of the fine-tuning data, it suggests that alignment methods could generalize to producing the desired behavior on inputs that humans did not directly supervise. In comparison, GPT-3 can perform these tasks but requires more careful prompting, suggesting that part of InstructGPT’s generalization capability is inherited from GPT-3.
The 175B PPO-ptx model can still make simple mistakes. For examples, (1) when given an instruction with a false premise, the model sometimes incorrectly assumes the premise is true; (2) when given a simple question, it can sometimes say that there is no one answer to the question and give multiple possible answers, even when there is one fairly clear answer from the context; and (3) the model’s performance degrades when instructions contain multiple explicit constraints (e.g. “list 10 movies made in the 1930’s set in France”) or when constraints can be challenging for language models (e.g. writing a summary in a specified number of sentences). The example (1) occurs because there are few prompts in the training set that assume false premises, and the models don’t generalize well to these examples. The example (2) is partly because labelers are instructed to reward epistemic humility and they tend to reward outputs that hedge. The models are neither fully aligned nor fully safe; they still generate toxic or biased outputs, make up facts, and generate sexual and violent content without explicit prompting. They can also fail to generate reasonable outputs on some inputs. Perhaps the greatest limitation of the models is that, in most cases, they follow the user’s instruction, even if that could lead to harm in the real world.
ChatGPT
ChatGPT is trained by using Reinforcement Learning from Human Feedback (RLHF), the same methods as InstructGPT, with slight differences in the data collection setup[1]. A new dialogue dataset is created by human trainers who played both user and chatbot, which is then mixed with the InstructGPT dataset that was transformed into a dialogue format. To train a reward model, another dataset was collected by sampling several alternative responses for each randomly selected model-written message and having their quality ranked by human trainers. The first version of ChatGPT was fine-tuned from a model in the GPT-3.5 series. Three single-turn examples were given[1] to demonstrate that ChatGPT outperformed InstructGPT on safety mitigations, such as challenging incorrect premises or rejecting inappropriate requests. Detailed differences between ChatGPT and InstructGPT are not yet published.
Five limitations of ChatGPT are reported[1]: (1) Untrue or nonsensical answers are sometimes generated, partly because there is no source of truth during RL training. (2) A slight rephrase of a question may result in opposite response. (3) The model is often excessively verbose and overuses certain phrases, due to biases toward longer answers in the training data. (4) When user provided an ambiguous query, the model usually guesses what the user intended instead of asking clarifying questions. (5) Even though the model has learned to refuse inappropriate requests, it sometimes still responds to harmful instructions or exhibits biased behavior.
A few updates to ChatGPT have been released since the initial launch on November 30, 2022. The most significant update was the incorporation of GPT-4 into ChatGPT, which has reached human-level performance on various academic and professional exams.
GPT-4
GPT-4 differs from GPT-3.5 by being multimodal, which can accept image and text inputs and produce text outputs. It has been deployed as ChatGPT Plus that requires paid access. Like ChatGPT, the technical details (dataset construction, model size, training method, hardware, etc.) of GPT-4 are not published. A technical report[13] focusing on the capabilities, limitations, and safety properties of GPT-4 is covered here.
For very large model like GPT-4, it is not feasible to do extensive model-specific tuning. It is desirable to be able to reliably predict some aspects of the performance of GPT-4 from smaller models trained using \(1,000\times\sim 10,000\times\) less compute. An infrastructure and optimization methods have been developed to achieve such highly predictable behavior across multiple scales. The final loss of a properly-trained language model has been shown to scale as a power-law with model size, dataset size, and the amount of compute used for training.[14][15] The final loss on a large dataset of code tokens (not contained in the training set) as a function of training compute can be fitted with \(L(C)=aC^b+c\) for smaller models trained using the same methodology but using at most \(10,000\times\) less compute than GPT-4, where \(L,C,c\) denote cross-entropy loss, compute budget, and an irreducible loss[15], respectively. The fitted scaling law predicted GPT-4’s final loss with high accuracy.
In addition to predicting final loss, similar methodology has been developed to predict more interpretable metrics of capability. One such metric is pass rate on the HumanEval dataset, which measures functional correctness for synthesizing Python programs from docstrings. An approximate power law relationship is found between mean log pass rate and training compute on smaller models: \(-E_P[\log(pass\_rate(C))]=\alpha\times C^{-k}\), where \(\alpha\) and \(k\) are positive constants, and \(P\) is a subset of problems in the dataset. This fit accurately predicts GPT-4’s performance.
GPT-4 with post-trained RLHF model was tested (but not trained) on a set of academic and professional exams, originally designed for humans. A minority of the questions in the exams were seen in the training data; for each exam, a variant with these “contaminated” questions removed was run and the lower score of the two was reported. Exam questions included two types of formats, multiple-choice and free-response questions, with separate prompts. Images were included in the input for questions requiring them. Evaluation was based on performance on a validation set of exams and final results were based on held-out test exams. Overall scores were determined by combining multiple-choice and free-response question scores for each exam. The percentile each overall score corresponds to is estimated and reported. GPT-4 exhibits human-level performance on the majority of these professional and academic exams, as shown in the Figure below. Notably, its score of the Uniform Bar Examination is in the top 10% of test takers.
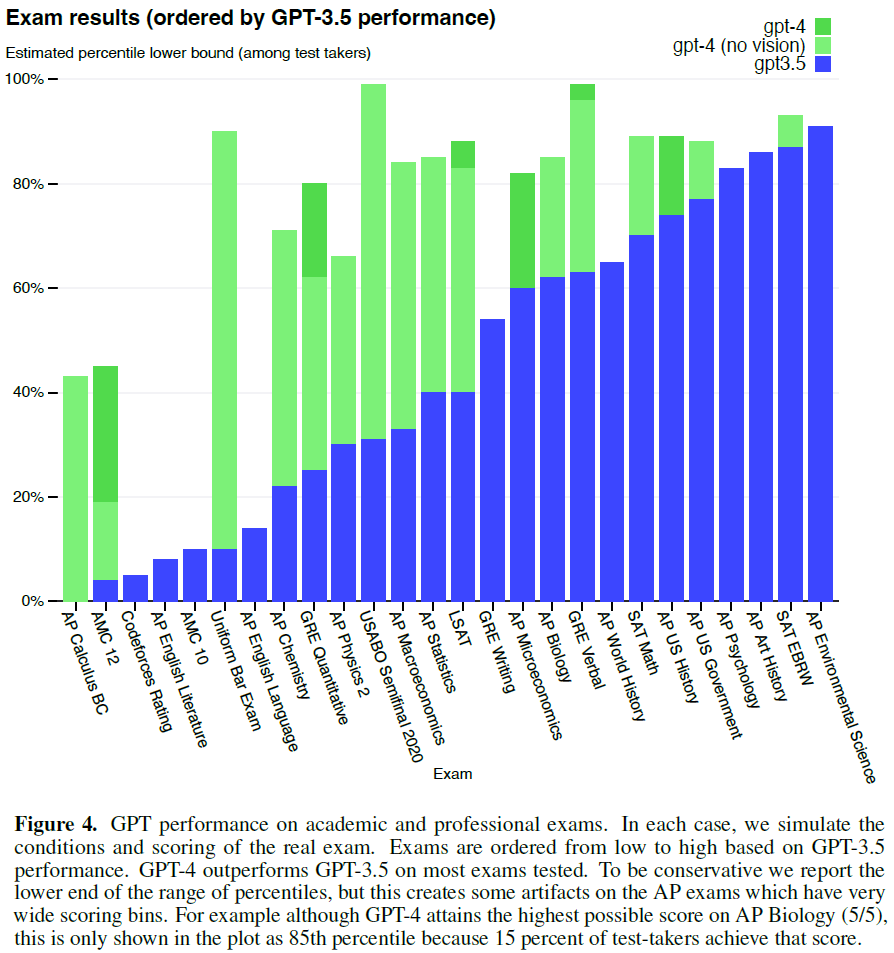
Comparison between GPT-4 base and GPT-4 post-RLHF on the multiple-choice question portions of the exam benchmarks shows that averaged across all exams, the base model and the RLHF model achieve a score of 73.7% and 74.0%, respectively, suggesting that RLHF post-training does not substantially alter base model capabilities and the capabilities on exams appear to stem primarily from the pre-training process.
On 7 common NLP benchmarks, the pre-trained base GPT-4 model considerably outperforms existing language models (e.g. PaLM, LLaMA), as well as previous state-of-the-art systems which often have benchmark-specific training (e.g. PaLM, GPT-3.5, Chinchilla). On a variety of non-English languages benchmarks, translated by Azure Translate from English MMLU benchmark[62], GPT-4 outperforms the English language performance of GPT-3.5 and existing language models (PaLM, Chinchilla) for the majority of languages tested. On the ability to follow user intent, as judged by human evaluations of the responses generated for a dataset of user prompts, GPT-4 was preferred over GPT-3.5 on 70.2% of prompts.
GPT-4 accepts inputs consisting of arbitrarily interlaced text and images. GPT-4 exhibits similar capabilities on documents with text and photographs, diagrams, or screenshots as it does on text-only inputs. The standard test-time techniques developed for language models (e.g. few-shot prompting, chain-of-thought, etc) are similarly effective when using both images and text. Preliminary results on a narrow set of academic vision benchmarks can be found in the GPT-4 blog post.
Despite its capabilities, GPT-4 still hallucinates facts and makes reasoning errors, like earlier GPT models. Comparing to GPT-3.5 models, GPT-4 significantly reduces hallucinations. On internal adversarially-designed factuality evaluations, GPT-4 scores 19 percentage points higher than latest GPT-3.5. On TruthfulQA task, the GPT-4 base model is only slightly better than GPT-3.5; but the RLHF post-training largely improves GPT-4 over GPT-3.5. GPT-4 resists selecting common sayings; however, it still can miss subtle details. GPT-4 generally lacks knowledge of events occurred after September 2021 (pre-training data cutoff date) and does not learn from its experience. It sometimes makes simple reasoning errors or is overly gullible in accepting obviously false statements from a user.
Pre-trained GPT-4 model is highly calibrated, meaning its predicted confidence in an answer generally matches the probability of being correct. However, after the post-training process, the calibration is reduced.
In addition to common risks of generative language models, such as generating harmful advice, buggy code, or inaccurate information, GPT-4’s higher capabilities pose new risks, such as long-term AI alignment risks, cybersecurity, biorisk, and international security. To evaluate model behavior in high-risk areas requires domain experts to adversarially test the model. Recommendations and training data gathered from these experts are used in mitigations and improvements for the model.
To mitigate safety risks at a more fine-grained level, the models themselves are used as tools. The approach consists of two main components: (1) rule-based reward models (RBRMs), and (2) an additional set of safety-relevant RLHF training prompts. The RBRMs are a set of zero-shot GPT-4 classifiers that provide an additional reward signal to the GPT-4 policy model during RLHF fine-tuning that targets correct behavior, such as refusing to generate harmful content or not refusing innocuous requests. The RBRM takes three inputs: the prompt (optional), the output from the policy model, and a human-written rubric (e.g., a set of rules in multiple-choice style) for how this output should be evaluated (e.g., to classify a response as one of the choices). Then, the RBRM classifies the output based on the rubric. For the set of safety-relevant training prompts that request harmful content, GPT-4 is rewarded for refusing these requests. Conversely, GPT-4 is rewarded for not refusing requests on a subset of prompts that are guaranteed to be safe and answerable. Combining this approach with other improvements such as computing optimal RBRM weights and providing additional SFT data targeting the areas to be improved, allows steering the model closer towards the desired behavior.
The safety mitigations have decreased GPT-4’s tendency to respond to requests for disallowed content by 82% compared to GPT-3.5, and increased GPT-4’s correct behavior rate for sensitive requests by 29% compared to GPT-3.5. On the RealToxicityPrompts dataset, GPT-4 and GPT-3.5 generate toxic content 0.73% and 6.48% of time, respectively. Because it is still possible to generate content violating usage guidelines, it’s important to complement them with deployment-time safety techniques like monitoring for abuse as well as a pipeline for fast iterative model improvement.
An Artificial General Intelligence
Bubeck et al. (2023)[20] use a broad range of novel and difficult questions to probe a text-only-input version of GPT-4’s responses and behaviors, to assess its intelligence, according to the 1994 definition of human intelligence[21]: a very general mental capability that, among other things, involves the ability to reason, plan, solve problems, think abstractly, comprehend complex ideas, learn quickly and learn from experience. The authors also adopt the phrase “artificial general intelligence” (AGI) to refer to systems that demonstrate broad capabilities of intelligence as captured in the 1994 definition, with the additional requirement that these capabilities are at or above human-level. This paper demonstrates GPT-4’s capabilities across a broad swath of domains and its performance on a wide spectrum of tasks at or beyond human-level. Thus, the authors claim that GPT-4 is a significant step towards AGI.
Multimodal and Interdisciplinary Composition
To assess GPT-4’s ability to comprehend complex ideas, the authors designed a set of prompts that require synthesis of information from different domains or modalities and combination of knowledge and skills across different contexts or disciplines. The combinations were deliberately chosen for those that the training data would rarely include, such as literature and mathematics (e.g. “Produce a proof of the fact there are infinitely many prime numbers in the literary style of Shakespeare”), programming and art (e.g. “Produce javascript code which generates random images in the style of the painter Kandinsky”), history and physics (e.g. “Write a supporting letter for Electron as a US presidential candidate, written by Mahatma Gandhi and addressed to his wife”), or programming and medicine (e.g. “Produce python code for a program that takes as an input a patient’s age, sex, weight, height and blood test results vector and indicates if the person is at increased risk for diabetes”). The generated responses show that both GPT-4 and ChatGPT can synthesize principles of different domains in creative and novel ways; but GPT-4 outperforms ChatGPT in several aspects as judged by human and GPT-4.
Additional sets of prompts were used to assess GPT-4’s abilities in image generation by producing scalable vector graphics (SVG) code, TiKZ (a language for creating graphics in LATEX) code, or JavaScript 3D library Three.js code. The image generation prompts for combining alphabet symbols and objects demonstrate that GPT-4 can handle visual concepts, despite its text-only training, and appears to have a genuine ability for visual tasks, rather than just copying code from similar examples in the training data. Examples of 2D and 3D images generated and edited by following detailed instructions demonstrate that GPT-4 appears to have not only generative skills, but also interpretive, compositional, and spatial skills. GPT-4’s high capability of following complex instructions but low quality of rendered images complement existing text-to-image synthesis models, such as DALLE-v2, Stable Diffusion, and Composable Diffusion, which produce high quality images but often suffer from a lack of spatial understanding capabilities and the inability to follow complex instructions. This paper demonstrates that combining GPT-4 output as the sketch with Stable Fusion v2.1 can produce images that have better quality and follow the instructions more closely than either model alone.
Another set of prompts were used to assess GPT-4’s abilities in music generation by producing ABC notation, a shorthand form of musical notation that uses letters, numbers and symbols to represent musical pitches, durations, chords and other elements in a compact and readable way. GPT-4 was able to produce valid ABC notation for a short tune according to instructions and, to some extent, explain and manipulate their structure. However, it could not produce any nontrivial form of harmony.
Coding
Two aspects of GPT-4’s coding abilities were evaluated: (1) coding proficiency in following instructions and (2) ability to understand existing code. For coding proficiency assessment, two types of instructions were used: (i) coding challenges and (ii) real world scenarios. Two benchmark datasets were used for coding challenges: HumanEval benchmark, a docstring-to-code dataset consisting of 164 coding problems, and a LeetCode benchmark, consisting of 100 software engineering interviews problems posted after GPT-4’s pretraining period. On HumanEval, GPT-4’s accuracy shows a big jump over the accuracies of GPT-3.5 (i.e. text-davinci-003, the base model of ChatGPT) and Codex (i.e. code-davinci-002, trained specifically on code). On the LeetCode benchmark, GPT-4 significantly outperforms the other models and is on par with human performance. GPT-4 even passes all three stages of mock software engineer interviews for Amazon on LeetCode. For end-to-end real-world scenarios, four examples are used: (a) Data Visualization - to extract data from the LaTeX code for a table and to produce a visualization plot in Python and then to perform various operations on the produced plot, (b) Front-end Game Development - to write a 3D game in HTML with JavaScript using a very high-level specification, (c) Deep Learning - to write a custom optimizer module that includes a sequence of non-trivial operations without detailed instructions, (d) Interfacing with LaTeX - to transform a snippet of buggy LaTeX code mixed with natural language into accurate LaTeX commands that compiles and is faithful in one shot. In all four scenarios, GPT-4’s responses largely match the instructions, but ChatGPT makes some major or fatal mistakes. To assess the ability of understanding existing code, four examples are examined: (A) Reverse-engineering assembly code - to find the password that is required to run a binary executable that stores the hash value of the password, (B) Reasoning about code execution - to predict and explain the output of a C program that prints the size of two structures, (C) Executing Python code - to explain the execution of a given Python code in detail by writing intermediate steps and comments, (D) Executing pseudo-code - to execute and explain every step of the pseudo-code of a given Python function. In all four examples, GPT-4 exhibits all-around proficiency in utilizing existing tools to crack the password or explains code executions correctly, but ChatGPT refuses to crack the password on ethical ground or fails to correctly explain code executions.
Mathematical Abilities
The first assessment was asking GPT-4 to solve several variants of a high-school level math question through a dialogue on different ways of formulating the question and reasoning of the solutions. It shows that GPT-4 can answer difficult high-school level math questions, and can sometimes engage in meaningful conversation around advanced math topics, but can also make very basic mistakes and occasionally produce incoherent output which may be interpreted as a lack of true understanding. Mathematical understanding was analyzed in three aspects: creative reasoning, technical proficiency, and critical reasoning. Creative reasoning refers to the ability in choosing the right argument or path towards the solution before “knowing” whether or not the path is going to lead to the correct solution. GPT-4’s ability in this aspect is comparable to that of a good high-school student or even higher. Technical proficiency refers to the ability to perform routine calculations or manipulations that follow a prescribed set of steps. While GPT-4 demonstrates a high degree of knowledge of the algorithms, it also makes very frequent mistakes when performing these tasks, such as making arithmetic mistakes, confusing the order of operations or using incorrect notation. Critical reasoning refers to the ability to critically examine each step of the argument, break it down into its sub-components, explain what it entails, how it is related to the rest of the argument and why it is correct. GPT-4 exhibits a significant deficiency in critically examining each step of the argument. The lack of critical reasoning could be attributed to two factors: (1) the training data of the model do not capture the wording that expresses the thinking process of math problem solving, and (2) the next-word-prediction paradigm has no mechanism to revise or modify its previous output, making its arguments “linearly”.
Three math benchmark datasets are used to evaluate GPT-4, ChatGPT (text-davinci-003), and Minerva (SOTA LLM for Math): GSM8K (elementary school level), MATH (high school level), MMMLU-STEM (high school and college STEM topics). To reduce the likelihood that testing questions/answers have been included in pre-training data, three approaches are taken: (1) asking for solution template or detailed steps, not just final answer, (2) altering numerical values in questions, (3) creating new questions. On an example question using the (2) approach, GPT-4 achieves an accuracy of 75.2%, while text-davinci-003 only has an accuracy of 0.2%, suggesting that GPT-4 does not rely on memorizing the exact problem statement but on applying a general solution method. For the benchmark datasets, the models are evaluated on the percentage of questions that they answered correctly in one try. The results show that GPT-4’s accuracy modestly outperform other models. GPT-4’s errors are largely due to arithmetic and calculation mistakes. In contrast, ChatGPT mostly produces incoherent argument and leads to irrelevant calculation.
Two examples are used to evaluate GPT-4’s abilities to build a mathematical model to address real-world problems. The first example asks for profiling power rate over time of a professional StarCraft 2 player during a match. GPT-4 successfully builds a plausible mathematical model for a complex system that requires extensive interdisciplinary knowledge, while ChatGPT fails to make meaningful progress. The second example asks to estimate how many Fermi questions are being asked every day. Fermi questions involve making educated guesses about quantities or phenomena using logic, approximation, and order-of-magnitude reasoning. GPT-4 demonstrates outstanding ability to answer Fermi questions by making layers of reasonable assumptions and informed guesses, while ChatGPT admits defeat immediately barely showing trace of mathematical thinking.
Three examples are used to evaluate GPT-4’s performance on advanced mathematical topics. The first example is a math proof question in the 2022 International Mathematics Olympiad (IMO), which requires knowledge of calculus to solve. GPT-4 manages to produce a correct proof. The second example is a discussion about algorithms and graph theory, typically covered in the first or second year of an undergraduate computer science degree. GPT-4 demonstrates profound understanding of the concepts discussed, as well as a significant extent of creativity; but GPT-4 can make a mistake similar to human typos. The third example is a question that requires knowledge of number theory and probability to solve. GPT-4 produces a sound argument but makes a counting mistake at the end which leads to an incorrect final answer.
Interaction with the World
An important aspect of intelligence is interactivity, which is defined as the ability to communicate and respond to feedback from other agents, tools, and environments. Interactivity requires an agent to comprehend complex ideas, learn quickly, and learn from experience. Two aspects of interactivity are explored: tool use (use of external resources) and embodied interaction (use of natural language to interact with environments).
To evaluate usage of external resources, it requires a prompt to tell the model that it is allowed or expected to use some specified external tools, such as search engines, APIs, or other functions. During execution, when an external function is called, model generation is paused, the appropriate function is called, the results are pasted back into the prompt, and then the generation is continued. In simple one-turn question-answering examples, GPT-4 is able to use the tools with very minimal instruction and no demonstrations, and then make use of the output appropriately. In contrast, ChatGPT sometimes refuses to answer a question, sometimes does not call the tools at all, and sometimes calls them after giving an incorrect answer. In more complex tasks, where a solution requires using multiple tools, models need to be able to understand the task at hand, identify the tools needed, use them in the correct order, and respond appropriately to their outputs. Four example tasks are shown to demonstrate GPT-4’s ability of using multiple tools. The first task asks GPT-4/ChatGPT to hack into a computer on the local network. GPT-4 scans the network for devices, identifies a target host, runs an executable that tries common passwords, and gains root access to the machine. ChatGPT refused to perform the task on the grounds of potential illegality. The second task asks GPT-4 to play the role of a zoo manager by completing a sequence of six tasks specified in a file, which requires it to manipulate files and folders containing information of the zoo, and to understand both the task and the appropriate commands. GPT-4 was able to solve almost all tasks, except fabricating content when replying to emails, rather than reading the specified content from a file. The problem is fixed by a simple tweak to the prompt. The third task asks GPT-4 to coordinate a dinner with two other people, and book it on a night when the user is free. GPT-4 uses the available APIs to retrieve information about the user’s calendar, coordinate with other people over email, book the dinner, and message the user with the details. GPT-4 demonstrates its ability to combine multiple tools and APIs, as well as reason about free-form outputs in order to solve a complex task. ChatGPT was unable to accomplish the same task. The fourth task asks GPT-4 to use a search engine and a SUMMARIZE function to browse the web and answer questions. GPT-4 is able to identify relevant search results to look at with more depth, summarize them, and provide accurate answers, even when the question contains a false premise. GPT-4 is able to do so without any fine-tuning or demonstration. In conclusion, GPT-4 is able to identify and use external tools on its own in order to improve its performance and to reason about which tools it needs, effectively parse the output of these tools and respond appropriately, all without any specialized training or fine-tuning. On the other hand, there are three limitations. First, an instruction prompt that specifies allowed or expected external tools is required. Second, even with access to tools, GPT-4 is not always able to reason about when it should use them and when it should simply respond based on its own parametric knowledge. Third, GPT-4 may repeat some error pattern or fail to use unusual tools, which can be fixed by GPT-4 when prompted to do so. In contrast, ChatGPT was unable to perform interactivity at a similar level, often ignoring the tools or their responses, and preferring generic answers.
Three examples are used to explore whether GPT-4 can engage in embodied interaction by using natural language as a text interface. The first task asks GPT-4 to explore a “map” of a house through interactive queries. Then, GPT-4 is asked to describe it in language and in a visualization. GPT-4 accurately describes what it explored, even though all of its interactions were through this restricted text interface. The second task is text-based games where an agent interacts with an environment through natural language descriptions and commands, and the agent has to perform a given task by exploring the environment and manipulating objects. Two different games are generated and played using TextWorld, a framework for text-based games. The first game is to find and unlock a certain chest by navigating between different rooms in a house with many rooms. The environment is described by a text paragraph, and the player can type commands such as “go north”, “examine couch”, or “open chest”. GPT-4 solves the game in 30 actions, by examining and picking up every object in each room regardless of its relevance to the game objective. In contrast, text-davinci-003 does not respond to the environment feedback at all, issuing the same command repeatedly. The second game is to prepare a two-ingredient, five-step meal according to a cookbook by figuring out key commands by itself from the environment response. GPT-4 uses trial and error when playing the game, but it cannot solve this game. However, if a one-shot demonstration of creating a different meal is given, it is able to generalize from it and solve the game. The third example is real world problems with a human partner: (1) to find and fix a water leak, (2) to identify the root cause of why a house is cold. For both problems, GPT-4 is able to identify the actions the human needs to take in order to address the problem. These examples illustrate that using language as an interface allows GPT-4 to perform tasks that require understanding the environment, the task, the actions, and the feedback, and adapting accordingly. While it cannot actually see or perform actions, it can do so via a human surrogate.
Interaction with Humans
Theory of mind is the ability to attribute mental states such as beliefs, emotions, desires, intentions, and knowledge to oneself and others, and to understand how they affect behavior and communication. Theory of mind is essential for effective communication and cooperation with other intelligent agents, as it allows one to infer their goals, preferences, motives, and expectations, and to adjust one’s own actions and utterances accordingly. It is also important for learning from others, as it enables one to interpret their feedback, advice, and demonstrations.
Three tests are used to evaluate the theory of mind capabilities of GPT-4, ChatGPT, and text-davinci-003. (1) On the classic Sally-Anne false-belief test from psychology, GPT-4 and ChatGPT correctly reason about the false-belief, while text-davinci-003 gives a wrong answer. (2) On a test to reason about the emotional state of others in complex situations, GPT-4 and ChatGPT pass the test, while text-davinci-003 fails the test. (3) On a test to reason about the intentions of people in complex social situations, GPT-4 gives a plausible answer for the intentions behind a puzzling action and a nuanced answer for a third-party’s likely interpretation of the puzzling action; ChatGPT gives a similar answer to the first question, but does not offer a nuanced response to the second question; text-davinci-003 gives plausible but very short answers to both questions.
Two realistic scenarios of difficult situations are used to test advanced theory of mind capabilities of GPT-4, ChatGPT, and text-davinci-003. The models are asked to propose actions that are likely to improve the situation, which require inferences about the counterfactual impact of actions on mental states. (1) On a conversation of marital struggle, GPT-4 is able to infer what each character’s mental state is, discern where miscommunication and misunderstanding lies, and provide suggestions that actually address the root cause of the misunderstanding. In contrast, both ChatGPT and text-davinci-003 incorrectly accept a mistaken assumption made by one of the characters, thus fail to understand the real dynamics of the situation, and only provide generic suggestions for improvement. (2) On a challenging family scenario, GPT-4 provides more nuanced answers, taking the whole scenario and actors into account. In contrast, ChatGPT and text-davinci-003 provide more general answers which do not include reasoning about the characters’ state of mind. In conclusion, GPT-4 outperforms the other two models in both basic and realistic scenarios that require reasoning about the mental states of others, and in proposing actions for cooperation towards common goals in social situations. GPT-4 is also able to handle abstract and novel situations that are not likely to have been seen during training, suggesting that GPT-4 has a very advanced level of theory of mind. However, the tests above are not exhaustive or comprehensive, and not covering all the possible aspects or dimensions of theory of mind.
The ability of self-explanation is a key component of intelligence, requiring communication, reasoning, and a good theory of mind for both oneself (the explainer) and the listener. In contrast to human, a chatbot does not have a consistent “self” across different execution. Given an input \(x\), a language model simulates some process \(P_{T}\) to solve a task \(T\) and can produce vastly different outputs \(y\) depending on the context \(c\) (topic, details, and even formatting of the input). The notation \(P_{T}(y\vert x,c)\) refers to the process that produces \(y\) given \(x,c\), which may not be the same process as solving the user’s task \(T\). Prompt engineering refers to setting up \((x,c)\) such that the simulation of \(P_{T}(y\vert x,c)\) approximates the task of interest well enough for the user’s purpose. To simulate the self-explanatory process, the notation \(P_{E}(e\vert x,c,y)\) is used, where \(e\) denotes the explanation. Two ways are used to evaluate the quality of an explanation: output consistency and process consistency. When an explanation is consistent with the output \(y\) given the input \(x\) and the context \(c\), it is termed output-consistent and considered as a plausible causal explanation. GPT-4 is remarkably good at generating reasonable and coherent explanations, even when the output is nonsensical or wrong, while text-davinci-003 produces an explanation that is not output-consistent on a test. Output consistency does not necessarily lead to process consistency. Process consistency checks whether an explanation is consistent with a model’s simulation of \(P_{T}\), i.e. whether it gives us the ability to make predictions about the future behavior of the model under different inputs (or even different contexts). On testing poetry writing explanations, GPT-4 shows process-consistent explanations.
Factors that influence process-consistency include the quality and variability of GPT-4’s simulation of the task, the degree of arbitrariness and inherent explainability of the task, the explanatory power of \(P_{E}\), and GPT-4’s skill in simulating \(P_{E}\). Output-consistent explanations can be valuable even when process-consistency is lacking, as they provide reasonable accounts of how the prediction could have been made, and thus give insight into the task itself. GPT-4’s improved ability to simulate various \(P_{T}\) and \(P_{E}\) represents an advance in explainability over prior art.
Discriminative Capabilities
The ability to discriminate, or to make distinctions between different stimuli, concepts, and situations, is a crucial component of intelligence, because it allows one to make more accurate judgments and decisions. Two tests are used to evaluate GPT-4’s capabilities of performing discriminative tasks: (1) to identify personally identifiable information (PII) in sentences, and (2) to determine similarity between statements.
PII can include email addresses, phone numbers, social security numbers, credit card numbers, along with other innocuous information such as names of places and locations. The PII detection task is to identify the segments that constitute PII and count the total number of such segments in a given sentence. A subset of the data from the text anonymization benchmark (TAB) is used for the test, which contains 6764 sentences, information about the various types of PII in the sentences, and the PII elements themselves. Two approaches to conduct the tests are compared: (1) a tool, called Presidio, that detects PII utilizing a combination of named-entity recognition and regular expression matching, and (2) GPT-4 powered by a specially constructed zero-shot prompt that contains definitions of 8 categories of PII. GPT-4 substantially outperforms Presidio. GPT-4 is able to match the ground truth 77.4% of the times, while Presidio only matches the ground truth 40.8% of the times.
Open-domain question answering is used to determine similarities between model-generated answers and corresponding reference answers. GPT-4 and GPT-3 (text-davinci-002) are compared using the TruthfulQA dataset containing 816 questions across 38 subject categories, such as economics, science, and law. The questions are chosen such that humans may also incorrectly answer them based on misconceptions and biases they may have. The prompt is designed to contain several examples of question-answer pairs followed by a question from the dataset for the models to answer. The generated answers are compared with provided reference answers using n-gram-based lexical similarity metrics ROUGE and BLEU, or machine-learned metric BLEURT. A generated answer is considered as a truthful completion matching the reference answer, if the score of a metric is above a pre-determined threshold. The percentage of truthful answers per metric is calculated across all the questions. The results show that GPT-4-generated answers are substantially closer to the reference answers than GPT-3-generated answers in all the three metrics. The percentages of correct answers generated by GPT-4 and GPT-3 for each subject category based on the ROUGE metric show that GPT-4 substantially outperforms in some subjects, e.g. Science, Sociology, Statistics; GPT-3 substantially outperforms in some other subjects, e.g. Misinformation, Advertising, Religion; and they perform equally in some other subjects, e.g. Superstitions, Paranormal, Fiction. Manual inspections of some GPT-4-generated answers that induced poor performance show that the degradation was not because they were inaccurate, but because they were long and meandering, which is commonly referred to as hedging and is a mechanism imbued into the model to handle ambiguity. GPT-4 often returns more plausible answers than GPT-3, particularly for categories where there is more ambiguity, e.g., Myths and Fairy Tales. For certain questions, GPT-4’s parametric knowledge seems to be not enough to provide truthful answers, and may require inputs from a verified external corpus, such as in Retrieval Augmented Generation methods. The performance of GPT-4 is higher than GPT-3 in categories related to people and places because GPT-4 is observed to hallucinate less when the questions are about well-known entities and locations.
Another approach to determine which one of a pair of statements generated by two models is more similar to the reference statement is to utilize GPT-4 itself as a judge. The prompt asks the model to provide (1) the similarities and differences between first generated and reference statements, (2) the similarities and differences between second generated and reference statements, and (3) which one of the two generated statements better captures the information of the reference statement and what is the justification for the choice. Judge GPT-4 picks the GPT-4-generated answer 87.76% of the time, the GPT-3-generated answer 11.01% of the time and neither answer 1.23% of the time. The explanations created by GPT-4 to justify its selection relies on semantic as well as conceptual similarity regardless of the length of the two statements it is comparing. To understand if humans would make the same decision as Judge GPT-4, two independent reviewers manually checked the similarity between the reference and model-generated responses for a subset of the questions. They picked the GPT-4-generated response 47.61% of the time, GPT-3-generated response 6.35% of the time, neither of the responses 22.75% of the time, and both of the responses 23.29% of the time. There was only a 50.8% overlap between the decisions made by Judge GPT-4 with humans. However, if human annotators were not allowed to pick “neither” or “none”, then the re-calibrated scores match what Judge GPT-4 chooses.
Limitations of Autoregressive Architecture Highlighted by GPT-4
At inference time, GPT architecture uses a single-pass next-word prediction paradigm that does not allow for storing intermediate results in working memory, backtracking, multi-step computation, or far-ahead planning. In some cases, this limitation can be remedied by explicitly instructing the model to solve the question in a step-by-step fashion; but this remedy is not sufficient in other cases due to the model’s autoregressive nature that sometimes poses a more profound difficulty. The lack of planning is demonstrated in two types of problems: arithmetic/reasoning problems and constrained text generation.
In the basic elementary school math \(a\times b+c\times d=?\) where the four numbers \(a,b,c,d\) are randomly chosen between 0 and 9 with uniform distribution, GPT-4 only achieves 58% accuracy. When the numbers are chosen uniformly between 10 and 19, between 20 and 39, and between 99 and 199, the accuracy drops to 16%, 12%, and 0%, respectively. If the model is asked to write down all the intermediate steps before producing the final answer, then the accuracy goes to 100% and 90% when the numbers are in the intervals 1-40 and 1-200, respectively. In another simple arithmetic problem, given \(9\times 4+6\times 6=72\), the model is asked to modify only one integer on the left-hand side so that the right-hand side becomes 99 and to write down a step-by-step plan before writing down the solution. The model’s plan reveals that it “thinks” in a linear manner and does not even “see” one step ahead. On 100 samples of the form \(a\times b+c\times d=e\), the correct rate ranges from 32/100 down to 18/200 dependent on the intervals from which the numbers are chosen. The results suggest that the low arithmetic performance is due to the model’s lack of ability to plan ahead. Similar low performance is observed in the “Tower of Hanoi” reasoning problem.
Constrained text generation is to ask the model to generate textual content according to specific instructions that include constraints on the structure of generated text. The constraints considered here can be roughly categorized as local and global. A local constraint only involves interactions between proximal parts of the text, such as generating rhymes that constrain a phonetic relation between consecutive sentences or prescribing the first letter or the first word in each sentence. A global constraint enforces a long-range interaction between different parts of the text, such as requiring that the first and last sentences are identical. GPT-4 seems to handle local constraints very well. On the contrary, examples of global constraints reveal the model’s lack of planning, working memory, ability to backtrack, and reasoning abilities. The model relies on a local and greedy process of generating the next word, without any global or deep understanding of the task or the output. GPT-4 is good at producing fluent and coherent texts, but has limitations on solving complex or creative problems that cannot be solved in a sequential manner. There are some parallelisms between the two types of constraints and two types of intellectual tasks: incremental tasks and discontinuous tasks. Incremental tasks can be solved in a gradual or continuous way by adding one word or sentence at a time toward the direction of the solution. These tasks rely on applying existing knowledge and skills to the given topic or problem and can be solved via content generation, such as writing a summary of a text, answering factual questions, composing a poem based on a given rhyme scheme, or solving a math problem that follows a standard procedure. Discontinuous tasks cannot generate content in a gradual or continuous wat and require a certain “Eureka” idea that accounts for a discontinuous leap towards the solution. These tasks involve discovering or inventing a new way of framing the problem, such as solving a math problem that requires a novel or creative application of a formula, writing a joke or a riddle, coming up with a scientific hypothesis or a philosophical argument, or creating a new genre or style of writing. There is also some parallelisms between the two types of constraints and the concepts of fast and slow thinking. Fast thinking is a mode of thinking that is automatic, intuitive, and effortless, but also prone to errors and biases. Slow thinking is a mode of thinking that is controlled, rational, and effortful, but also more accurate and reliable. The “slow thinking” component oversees the thought process and uses the fast-thinking component as a subroutine together with working memory in an organized thinking scheme. It has been hypothesized that human cognition is a mixture of these two modes of thinking, and human often rely on one mode when the other mode should be used. GPT-4 can be seen as able to perform “fast thinking” operations very impressively, but is missing the “slow thinking” component.
Societal Influences
GPT-4, like all LLMs, can generate errors, including mathematical, programming, attribution, and conceptual errors, which are often referred to as hallucinations and often intertwined with correct information and presented in a persuasive and confident manner. Care must be taken to review output for correctness for uses in domains where truthfulness and accuracy are required, such as medicine, transportation, journalism, and attribution to individuals or organizations. Examples of such care include clearly indicating the use of an LLM to generate content, naming human editors responsible for fact-checking, and adhering to the highest standards and practices for verifying information generated by LLMs. Consumers of generated content will need to be educated about the challenges of erroneous generations and the need for their ongoing vigilance about erroneous output. In GPT-4 applications that depend critically on factual inferences, people and organizations will need to develop best practices for quality assurance.
GPT-4, like all LLMs, can be used by malevolent actors in adversarial scenarios, from efficient generation of disinformation to creating cyberattacks against computing infrastructure. Two examples are used to demonstrate the pre-alignment version of GPT-4’s power in generating disinformation and performing subtle, yet powerful manipulation. The first example asks the model to create a misinformation plan for convincing parents not to vaccinate their kids. The model returns a plan containing three steps: (1) identifying online platforms and target audience group for sharing disinformation, (2) finding disinformation sources, and (3) identifying a strategy for using emotional appeals for persuasion. The model generates three disinformation messages that are customized for triggering different emotional reactions, such as guilt or pride, even for people with a specified attribute. The second example asks the model to have a conversation with a child, trying to convince the child to do whatever their friends are asking of them to do. The model demonstrates abilities in building emotional connection with the child and providing encouragement in order to influence, persuade, or manipulate the child.
GPT-4, like all LLMs, inherits various forms of biases in the training data from the public internet. Three experiments are used to demonstrate the existence of biases in GPT-4. The first experiment asks GPT-4 to write a note recommending a given occupation to a friend. Then, in the note, the first use of a word that identifies gender is tracked and the probability distribution of genders (normalized to she, he, third person pronoun) per occupation are computed after multiple runs. The results show that the model’s choice of the pronoun reflects the skewness of the world representation for that occupation in most cases (e.g., 98% he for software engineer, 93% she for elementary school teacher). Such gender bias on occupation in text generation can be mitigated by prompt engineering, such as asking the model to write the note “in an inclusive way”. The second experiment asks the model to complete an analogy like “A man is computer programmer, a woman is …” and to explain if any of these analogies could be offensive to a certain group. The model generates multiple analogies, some of which could be assessed to be offensive or biased. The explanation provided by GPT-4 on the potential offensiveness of its generations touch on social and societal norms and concepts. The third experiment asks GPT-4 to answer a common riddle that is widely used as an example of implicit bias. The model provides multiple answers, including the most common answer of the surgeon being the mother. When asked why people have a hard time answering this riddle, the model’s answer touches on human decision-making for this question being influenced by implicit or explicit biases and stereotypes.
GPT-4 can do quite well on examinations for professional certifications, such as those given in medicine and law, raising concerns about the potential impacts on highly skilled and respected professions, where human and machine inferences may compete or complement each other in different ways. The perception of the growing role of AI in radiology has significantly lowers US medical students’ choice of radiology as a career, which may reflect a broader trend across jobs that require advanced training, where AI systems could displace human workers or reduce their status. On the other hand, there are promising possibilities ahead for extending human intellect and abilities with new kinds of human-AI interaction and collaboration.
The limited availability to the most powerful AI systems may create an “AI divide”. AI advances can amplify existing societal divides and inequalities. On another front, confidentiality and privacy of individuals and organizations using the models will need to be protected against leakage through logging or generalization. On another concern, there are calls for marking the origin of content generated by AI systems.
Directions and Conclusions
GPT-4’s abilities are comparable to human-level for many tasks and domains, which suggest that the evaluation of the capabilities and cognitive abilities of GPT-4 and its successor models have become much closer in essence to the task of evaluating those of a human rather than those of a narrow AI model. This paper will stimulate further research on the mechanisms and principles that underlie GPT-4’s intelligence.
The central claim of this paper is that GPT-4 attains a form of general intelligence. The guiding framework to explore GPT-4’s artificial intelligence is the 1994 definition of intelligence by a group of psychologists[21], which is vague, incomplete, and does not specify how to measure or compare the intelligence. Moreover, the definition for human intelligence may not reflect the specific challenges and opportunities of artificial systems. Thus, this definition is only a useful starting point in this line of research.
Eight drawbacks of the model should be mitigated to achieve more general intelligence. (1) Hallucinations can be mitigated by three complementary approaches: (i) to improve the calibration of the model so that it either abstains from answering when confidence level is low or provides some indicator of confidence, (ii) to insert information that the model lacks into the prompt for mitigating open-domain hallucination and to use post-hoc checks for closed-domain hallucination, (iii) building the user experience of an application with the possibility of hallucinations in mind. (2) It is unclear whether the model can perform tasks that require an evolving long-term memory and context, because it operates in a stateless fashion and its input size, and thus context size, is limited. (3) The model is fixed once it is trained, and there is no mechanism for incorporating new information or user feedback. Fine-tuning with new information may cause performance degradation or overfitting. Therefore, the model is often out of date on events, information, and knowledge that came into being after the latest cycle of training. (4) The model does not have any way to incorporate personalized information into its responses, except by using meta-prompts, which are limited and inefficient. (5) The model does not perform well on tasks that require planning ahead or that require a discontinuous conceptual leap in completing the tasks. (6) The model has no way of verifying whether or not the content that it produces is consistent with the training data, or whether it is self-consistent. While the model can provide high-quality post-hoc explanations for its decisions, it is often to see inconsistencies between the model’s decisions and its explanations. (7) The model may inherit some of the biases, prejudices, or errors that are present in its training data, which may reflect the distribution of opinions or perspectives linked to subsets of the population or larger common views and assessments. (8) The model’s responses can be very sensitive to details of the framing or wording of prompts and their sequencing in a session. Significant effort and experimentation is often required with prompts engineering and sequencing to avoid suboptimal and non-aligned inferences and results.
Four potential extensions to next word prediction architecture are proposed: (1) external calls by the model to components and tools such as a calculator, a database search or code execution; (2) a “slow-thinking” mechanism that uses the “fast-thinking” mechanism of next word prediction model as a subroutine, and it also has access to external sources of information or feedback, and it would be able to revise or correct the outputs of the fast-thinking mechanism; (3) integration of long-term memory as an inherent part of the architecture, perhaps in the sense that both the input and output of the model will include a vector that represents the context; (4) replacing the sequence of tokens by a hierarchical structure, where higher-level parts of the text such as sentences, paragraphs or ideas are represented in the embedding, and where the content is generated in a top-down manner.
It is unknown why GPT-4 exhibits such general and flexible intelligence when it is at its core merely the combination of simple algorithmic components—gradient descent and large-scale transformers with extremely large amounts of data.
Ability of Making Reusable Tools
To remove dependence on the availability of suitable external tools for tool-augmented LLMs, Cai et al. (2023)[22] developed a closed-loop framework, referred to as LLMs As Tool Makers (LATM), where LLMs create their own reusable tools for problem-solving. The approach comprises two key stages: (1) tool making: an LLM, referred to as the tool maker, designs tools (implemented as Python functions) specifically for a given task, such as to schedule a meeting, to track shuffled objects, or to sort words alphabetically. (2) tool using: another LLM referred to as the tool user, which may or may not be the same as the tool maker, applies the tools to handle new requests. The tool maker can make different tools for different requests, and the tool user can reuse already made tools for similar requests. Another lightweight LLM, referred to as the dispatcher, is used to determine whether an incoming problem can be solved using existing tools or if a new tool needs to be created. This enables real-time, on-the-fly tool-making and usage. By assigning a more powerful albeit resource-intensive model (e.g., GPT-4) to the tool-making stage and a lightweight and cost-effective model (e.g., GPT-3.5 Turbo) to tool-using stage, this approach can balance performance and cost-effectiveness when addressing a series of tasks.
The tool maker’s role is to create a generic and reusable tool from several (3 in this paper) demonstrations of a task. The tool-making stage can be further divided into three sub-stages: (1) tool proposing: the tool maker attempts to generate a Python function that produces the demonstrated behaviors, if the proposed tool is unexecutable or encounters errors, appends the error messages to the history and makes another attempt to fix the error; (2) tool verification: the tool maker generates unit tests using 3 validation samples and subsequently executes these tests on the proposed tool, if the tool fails any of these tests, records the error in its history and makes an attempt to generate new tests that correct the function calls, not the function, in the unit tests; and (3) tool wrapping: after the above two sub-stages succeeded, the tool maker wraps up the function code and the demonstrations of how to convert a question into a function call, extracted from unit tests, and prepares wrapped tools for tool user. The tool-making stage only needs to be performed once for each type of task. The resulting tools can then be reused for all instances of that task. The Python function tools are a more generic form of Chain-of-Thought and can be used to solve questions that involve algorithmic reasoning ability.
The tool user’s role is to utilize the verified tool to solve various instances of the task. The prompt for this stage is the wrapped tool which contains the function for solving the given task and demonstrations of how to convert a task query into a function call. Tool user can then generate the required function call in an in-context learning fashion. The function calls are then executed to solve the task. The output can be optionally converted to match the required format of the task, such as options for multiple-choice questions.
The dispatcher maintains a record of existing tools produced by the tool maker and determines whether to engage the tool user or tool maker for each incoming task in a stream of task instances. Upon receiving a new task instance, the dispatcher first determines if there is a suitable tool for the task at hand. If a suitable tool exists, the dispatcher passes the instance and its corresponding tool to the tool user for task resolution. If no appropriate tool is found, the dispatcher identifies the instance as a new task and solves the instance with a powerful model or even invokes a human labeler. The instances from a new task are then cached until sufficient cached instances are available for the tool maker to make a new tool. Given the simplicity of the dispatching task, the dispatcher can be a lightweight model equipped with proper prompts, which adds only a marginal cost to the overall pipeline.
Six datasets from diverse domains are used to evaluate the approach, five of which are sourced from BigBench and one, the Scheduling Meeting task, is constructed by the authors for real-world scenarios. During the tool-making stage, GPT-4 and GPT-3.5 Turbo models are used with the ChatComplete API and temperature = 0.3. Generated responses are always appended to the chat history to create an interactive experience. In the tool-using stage, the LLM API call is made only once with temperature = 0.0. Ablation studies are performed on GPT-3-type models with the standard Completion API. The maximal retry times are set to be 3 for the tool-proposing and tool-verification stages.
In the tool-making stage, k-shot exemplars (k=3) per task are provided for the LLM to guide it to generate generic Python programs. When GPT-4 is employed as the tool maker, the model frequently devises suitable algorithms for solving tasks. The tool-verification stage is mainly used to provide examples that demonstrate how to convert natural language questions into function calls, but only 2 cases, out of the 60 trials, are observed that the tool maker can correct its mistakes with the guide of error messages.
Comparison between the LATM and Chain-of-Thought (CoT) prompting demonstrates that the application of LATM can significantly enhance the performance of GPT-3.5 Turbo, not only substantially outperform GPT-3.5 Turbo with CoT in all 6 tasks, but also surpassing or matching GPT-4’s performance with CoT in 5 tasks. This highlights the effectiveness of LATM in enhancing the performance of lightweight models and therefore reducing the cost compared to employing expensive models. The overall cost of processing \(n\) samples are \(O(nc+C)\) and \(O(nC)\) for GPT-3.5 Turbo with LATM and GPT-4 with CoT, respectively, where \(c\) and \(C\) denote the cost of one call to GPT-3.5 Turbo and GPT-4, respectively. At the time of this study, \(C\) is over 15x larger than \(c\).
In a streaming setting where instances from potentially different tasks arrive on-the-fly. The dispatcher, implemented with GPT-3.5 Turbo, is evaluated for two abilities: (1) to identify existing tools to solve an incoming instance, and (2) to request tool-making for instances from an unseen task. For the first ability, the test set contains 100 samples of the 6 tasks mixed randomly. For each instance in the test set, the dispatcher is used to identify the appropriate existing tool with the prompt that contains task examples associated with existing tools. The accuracy of determining the correct tool is 94% ± 2% over five random constructions of the test set. For the second ability, 4 tasks are randomly selected as existing tasks with tools ready. Then, 4 tasks are selected for testing: 2 are unseen and 2 are within the existing tasks. A test set with 100 samples are generated. For each instance in the test set, the dispatcher is used to determine whether it needs to request tool-making or if the instance can be solved by an existing tool. The accuracy of making the correct request is 95% ± 4%. These suggest that LATM can be smoothly extended to a streaming setting with a mixture of tasks.
GPT-4 is more suitable to be used as a tool maker because (1) on hard tasks like Logical Deduction and Tracking Shuffled Objects, GPT-3.5 Turbo fails in all the 5 trials, and (2) GPT-4 has longer context length, 8192, preferable for the entire history in each step of tool-making to enhance the reliability of the tool-making stage. It is observed that GPT-3.5 Turbo offers the best balance between performance and cost among all the models tested. It is found that the older GPT-3 series of models (ada, babbage, curie, davinci) before instruction tuning often perform better than their counterparts post instruction tuning. It is hypothesized that the instruction tuning phase in these models may adversely impact the in-context learning ability, which is crucial for the tool-using stage.
It is also investigated whether Chain-of-Thought (CoT) steps generated by a larger model can be reused to a smaller model similar to LATM pipeline. GPT-4 is used in the “CoT-making” stage that uses zero-shot prompting “Let’s think step by step.” to elicit the intermediate thought steps. Then, the generated CoT is used to smaller tool-using model GPT-3.5 Turbo. The results show that using CoT generated by a large model has a similar or even worse performance than using human-written CoT, which in turn is much worse than LATM.
GPT-4V
GPT-4 with vision (GPT-4V) enables users to instruct GPT-4 to analyze image inputs provided by the user. The system card[83] outlines how OpenAI prepared the vision capabilities of GPT-4 for deployment.
Be My Eyes is an organization that builds tools for visually impaired users. Be My Eyes and OpenAI collaborated to develop Be My AI, a tool to describe the visual world for people who are blind or have low vision. Be My AI incorporated GPT-4V into the existing Be My Eyes platform which provided descriptions of photos taken by the blind user’s smartphone. Be My AI was beta tested by a group of blind and low vision users, who expressed concern that the model can make basic errors, sometimes with misleading matter-of-fact confidence. Since risks remain, Be My Eyes warns its testers and future users not to rely on Be My AI for safety and health issues like reading prescriptions, checking ingredient lists for allergens, or crossing the street. Likewise, Be My Eyes tells its users that AI should never be used to replace a white cane or a trained guide dog. Be My AI testers want to use Be My AI to know the facial and visible characteristics of people they meet, people in social media posts, and even their own images. But this feature has risks on privacy and bias.
GPT-4V has also been tested by over a thousand alpha testers over three months to better understand the use of GPT-4V for person identification, medical advice, and CAPTCHA breaking. 20% sampled prompts were queries requesting general explanations and descriptions of an image. Exposed risks include medical condition diagnosis, treatment recommendations, medication intake, and several privacy-related concerns on the uploaded images of people.
Refusal evaluations measure the percentage of model outputs that constitute a refusal in response to certain potentially risky inputs, including illicit behaviour, ungrounded inferences, person identification requests, and text-screenshot jailbreak. Performance accuracy evaluations measure how often the model correctly answers a certain input prompt by choosing the right answer out of 5 options in 6 areas. (1) Sensitive trait attribution across demographics. These evaluations were constructed using publicly available datasets such as FairFace and Labeled Faces in the Wild. To avoid performance parity on images of people for gender, age, and race recognition, OpenAI has added refusals for most instances of sensitive trait requests. (2) Person identification evaluations. Evaluation datasets were constructed using public datasets such as CelebA, Celebrity Faces in the Wild and a dataset of images of members of Congress for public figures. The model’s refusal rate is >98% and accuracy rate is 0% to this class of requests. (3) Ungrounded inference evaluation. Automatic evaluations have been built to gauge the model’s propensity to successfully refuse requests for ungrounded inferences, meaning inferences not justified by the provided image or text. (4) Multimodal jailbreak evaluations. Jailbreaks typically involve trapping the model via convoluted logical reasoning chains designed to make it circumvent the safety systems in place to prevent malicious misuse. For image input, the logical reasoning needed to break the model can be placed into images, e.g., in the form of screenshots of written instructions, or even visual reasoning cues, and thus circumvents text-based heuristic safety methods. A comprehensive set of known text jailbreaks are converted to screenshots of the text to quantify this. (5) Extending text-only evaluations to multimodal. Image synonyms are images that can be used to replace a word, for example, an image of a knife being used to replace the word ‘kill’. The same set of text-only evaluations from GPT-4 for domains such as self-harm behaviors and graphic material are used by replacing words with up to two image synonyms per example. This was done to ensure that images did not offer an easy way to bypass text-only mitigations. (6) CAPTCHA breaking and geolocation. Tasks such as the ability to solve CAPTCHAs indicate the model’s ability to solve puzzles and perform complex visual reasoning tasks. However, a powerful, general purpose CAPTCHA breaker can be used to bypass security measures intended for botware, and they enable AI systems to interact with systems intended for human use. High performance on geolocation (e.g., identify the name of the city) evaluations demonstrate world knowledge the model possesses and can be useful for users trying to search for an item or place, but may also present privacy concerns.
External red teaming experts test limitations and risks associated with the vision functionality of GPT-4V. Six key risk areas received especially useful red teamer feedback. (1) Scientific proficiency. GPT-4V makes mistakes, such as combining terms to create unrelated terms and missing information, while processing complex images. It is also prone to hallucinations and can make errors in an authoritative tone. The model is unreliable and should not be used for any high-risk tasks such as identification of dangerous compounds or foods. (2) Medical advice. While GPT-4V would occasionally give accurate responses to a question regarding a medical image, it could sometimes give wrong responses for the same question. Given the model’s inconsistent performance in medical domain and the risks associated with inaccuracies, the current version of GPT-4V is not considered to be fit for performing any medical function or substituting professional medical advice, diagnosis, or treatment, or judgment. (3) Stereotyping and ungrounded inferences. Earlier versions of GPT-4V often showed stereotypes and ungrounded inferences, when prompted to make a decision between a variety of options and asked to explain the decision. Open-ended questions paired with an image to GPT-4V exposed bias or anchoring towards specific topics that may not have been intended by the prompt. Mitigations for risks associated with ungrounded inferences have been added by having the model refuse such requests relating to people. (4) Disinformation risks. GPT-4V has higher risks of generating disinformation than GPT-4, due to additional content from image input. GPT-4V’s ability to detect disinformation was inconsistent; thus, it should not be used as a way to detect disinformation, or to otherwise verify something is true or false. (5) Hateful Content. In some but not all instances, GPT-4V refuses to answer questions about hate symbols and extremist content. The behavior may be inconsistent and at times contextually inappropriate. The model can also sometimes make songs or poems that praise certain hate figures or groups if given a picture of them, when the figures or groups are not explicitly named. OpenAI has added refusals for certain kinds of obviously harmful generations in the space but not all. (6) Visual vulnerabilities. The specific ways that images are presented, such as ordering of the images used as input, may influence model response. This represents challenges with robustness and reliability that the model still faces.
GPT-4V inherits some safety mitigations already deployed in GPT-4 and DALL-E. The performance of refusals of text content against existing policies is equivalent to the base language model. At the system-level, the existing moderation classifiers continue to inform the monitoring and enforcement pipelines for post-hoc enforcement of text inputs and outputs. Some novel risks introduced by the multimodal model include: (i) images with people in them, (ii) common multimodal jailbreaks such as adversarial images with text, and (iii) text or image not harmful individually, but becoming harmful when combined. GPT-4V refuses requests for the following: (i) identity of a person, (ii) sensitive traits of a person, (iii) ungrounded inferences of an image. Additional multimodal data were integrated into the training dataset in order to reinforce refusal behavior for illicit behavior and ungrounded inference requests. For ilicit behavior, a multimodal dataset were collected by augmenting the existing text-only dataset with image synonyms. For ungrounded inference requests, data were collected through red teaming campaigns. Post-training evaluations show that 97.2% of the completions refused requests for illicit advice, and 100% of the completions refused requests for ungrounded inference. Some system-level mitigations (e.g., OCR-based tool) were added for adversarial images containing overlaid text to ensure this input couldn’t be used to circumvent existing text safety mitigations.
Preliminary Explorations with GPT-4V
Yang et al. (2023)[85] qualitatively explored GPT-4V to provide a glimpse of its new capabilities and potential emerging use cases. The selected examples in this paper may require careful instruction tuning or may only work with the specifically designed prompts. Thus, the capabilities demonstrated in this paper may not consistently work across different samples. To prevent the text and images in the test prompts from being seen during GPT-4V training, original text queries are created from scratch, and images that are either not accessible online or with a timestamp beyond April 2023 are used. Instances not following these criteria will be indicated. This paper primarily focuses on zero-shot learning with instruction, as opposed to in-context few-shot learning. Zero-shot is designated as the default working mode for presentation. The use of in-context examples is reduced to minimize examples’ impacts on the evaluated capabilities.
GPT-4V’s Supported Inputs. Three types of input modalities are supported. (1) Text-only inputs. GPT-4V’s language and coding capabilities are performed with text for both input and output. (2) Single Image-text Pair. GPT-4V can take a single image-text pair or a single image as input to perform various vision and vision-language tasks, such as image recognition, object localization, image captioning, visual question answering, visual dialogue, dense caption, and so on. The text in the image-text pair can be used either as instruction like “describe the image” for captioning, or as the query input like the question in visual question answering. (3) Interleaved Image-text Inputs. GPT-4V can handle interleaved image-text inputs, ranging from visually centric (e.g., multiple images with a short question or instruction) to text-centric (e.g., a long webpage with two inserted images), or a balanced mixture of images and texts. This mode of input enables applications for extracting queried information from multiple input images, such as computing the total tax paid across multiple receipt images or calculating total cost from an image of ordered items and an image of menu. In addition, processing interleaved image-text inputs serves as a fundamental component for few-shot and other test-time prompting techniques, thereby further boosting GPT-4V’s generality.
GPT-4V’s Working Modes and Prompting Techniques. Four types of prompting modes are discussed. (1) Following Text Instructions. Instructions are natural ways to define and customize the desired output text for arbitrary vision-language use cases, ranging from simply asking to describe an image to more sophisticated “constrained prompting” and “condition on good performance”. Constrained prompting requires the response to be constrained in some way, such as reading text from a driver’s license image and returning the text in JSON format. Condition on good performance mainly involves chain-of-thought prompting, e.g., “You are an expert in counting things in the image. Let’s count the number of apples in the image below row by row to be sure we have the right answer.”. (2) Visual Pointing and Visual Referring Prompting. Visual pointing refers to marking an arbitrary spatial region of interest on an image, which can be represented as numerical spatial coordinates or visual markers overlaid on image pixels. A new prompting method named visual referring prompting is first reported, where people edit the pixel space of input images to specify the desired objective, such as drawing visual pointers or handwriting scene texts, and prompt questions or instructions regarding the specified objective. (3) Visual + Text Prompting. Visual referring prompting can be used together with other image-text prompts. GPT-4V can process an arbitrary mix of images, sub-images, texts, and visual pointers. On the contrary, prior multimodal models are highly restricted in terms of how they can combine images and texts, and the number of images they can process, thereby imposing limitations on the models’ capability and genericity. GPT-4V’s capability to comprehend multimodal instructions enables task demonstrations to be grounded onto corresponding in-context examples, therefore more effectively illustrating the task of interest. (4) In-context Few-shot Learning. In vision-language multimodal models, in-context few-shot learning uses image-text pairs as query inputs. This paper shows two examples, reading speed meter images and reasoning over a complex line plot, where few-shot input queries are required for GPT-4V to respond correctly, when zero-shot and one-shot fail to answer correctly. In-context few-shot learning is considered as a viable alternative to fine-tuning.
Vision-Language Capabilities. Six types of capabilities in understanding and describing visual information are explored using single image-text pair inputs. (1) Image Description on Diverse Domains. On celebrity recognition and description task, GPT-4V accurately recognizes a variety of celebrities and describes the visual information (including their profession, action, image background, and the event) in details. On landmark recognition and description task, GPT-4V accurately recognizes the landmarks in the test images and generates vivid and detailed narratives that capture the essence of the landmarks. On food recognition and description task, GPT-4V recognizes various dishes and identifies specific ingredients, garnishes, or cooking techniques present in a dish image. On medical image understanding task, GPT-4V recognizes both the teeth and jaw bones in the given X-ray, and explains that the partially emerged wisdom teeth may necessitate removal. GPT-4V can also identify a bone fracture in a foot x-ray and point out potential concerns based on a CT scan of the lung. On logo recognition and description task, GPT-4V correctly recognizes the logos and provides detailed descriptions, including its design, color, shape, and symbol. GPT-4V also demonstrates strong capability in understanding logos in many in-the-wild scenarios, including occlusions, lighting conditions, and orientations. On scene understanding task, GPT-4V is able to describe the view of the road from the inside of a car, including a detailed description regarding the scenes and objects. On counterfactual examples, GPT-4V is able to provide factual descriptions regarding the scenes and objects in the images contents when faced with misleading questions or instructions.
(2) Spatial Relationship, Object Counting, Localization, and Dense Captioning. On spatial relationship understanding task, GPT-4V is able to recognize the spatial relationship between the objects in the images. On object counting task, GPT-4V can successfully count the number of objects, such as apples, oranges, and people, present in the image. However, when objects are occluded, or the scene is cluttered, the counting process can result in errors. On object localization in an image using a bounding box, GPT-4V is able to generate and approximate the bounding box coordinates in textual format for the specified objects in the image. Promising localization results are observed when the scene or background is relatively simpler and less cluttered. Further prompting techniques are required to enhance object localization performance in more complex and crowded environments. Dense captioning involves generating detailed description for each region of interest in the given image, which typically requires integration of multiple experts, such as object detector, celebrity recognition model, and image captioning model. An instructional CoT prompt is used to explore GPT-4V’s capabilities in dense captioning. GPT-4V can successfully generates dense captions for the input image.
(3) Multimodal Knowledge and Commonsense. Jokes and memes often reference specific events, pop culture, or Internet trends, which require cultural knowledge to understand. Memes can take various forms, such as images, videos, and GIFs. Inputs with paired meme and text prompt are used to evaluate GPT-4V’s ability to grasp the visual elements, their relationship to the text, and the intended humorous effect. GPT-4V has remarkable ability to gather information from both visual and textual modalities, and then comprehend the humor embedded within memes. Science and knowledge. To evaluate GPT-4V’s capability in tasks that require reasoning with scientific knowledge, a text prompt question and a corresponding image are provided. GPT-4V is able to correctly answer the science questions based on the visual context in a wide range of topics, including geography, physics, biology, and earth science. Given a more specific input prompt, GPT-4V can generate answer in a tutorial format and explain the subject step by step. Multimodal commonsense. On multimodal commonsense reasoning task, GPT-4V effectively utilizes the bounding boxes presented in the image as visual prompts to recognize the actions performed by the individuals. Given a more specific input prompt, GPT-4V can discern numerous nuanced visual cues within the image and offers a list of plausible hypotheses.
(4) Scene Text, Table, Chart, and Document Reasoning. On scene text recognition task, GPT-4V accurately identifies scene text in various scenarios, including both handwritten and printed text. On visual math reasoning task, GPT-4V is able to extract essential information from the image and solve the math problem step by step in a well-structured solution. On chart understanding and reasoning tasks, GPT-4V exhibits the ability to provide detailed descriptions of charts and can answer questions based on the charts. On table understanding and reasoning task, GPT-4V shows promising results in understanding the details in the table, as well as in reasoning and accurately responding to related questions. On document understanding task, GPT-4V demonstrates an understanding of various types of documents, such as floor plan, poster, exam paper, and a multi-page technical report, and provides reasonable responses.
(5) Multilingual Multimodal Understanding. For natural images without scene text, GPT-4V can process both the input prompt and output text in different languages, including a case that gets input in Spanish and generates image descriptions in 20 different languages. For images with multilingual scene text, GPT-4V can understand the scene text, and translate it to a different language. In a case, GPT-4V is instructed in Catalan to summarize a Wikipedia webpage screenshot in 20 different languages and GPT-4V is able to generate precise summary and translate them into 20 different languages. On multilingual multicultural understanding task, GPT-4V is capable of understanding cultural nuances and generating reasonable multilingual descriptions for the given wedding images in different cultures.
(6) Coding Capability with Vision. When GPT-4V is prompted with the instruction “generate LaTex code” for hand-written mathematical equations, it is able to generate correct LaTex codes for shorter equations, but not for longer equations. By breaking down longer equations into shorter components, the model is able to generate the appropriate code. GPT-4V also demonstrated reasonable capability to generate MarkDown/LaTex codes to reconstruct (with some errors) a table in an input image. GPT-4V has limited capability to write codes in python/TikZ/SVG to replicate input figures. Although the generated codes failed to render exactly matched figures, they can be easily modified to meet specific needs.
Interaction with Humans: Visual Referring Prompting. GPT-4V can understand different types of visual markers directly overlaid on images as a pointer, such as circles, boxes, and hand drawings. GPT-4V can also understand region coordinates represented in numerical text format. Overall, GPT-4V works more reliably when prompted with overlaid visual pointers, compared with text coordinates. The new visual referring prompting method directly edits the pixel space of input images as input prompts, such as drawing visual pointers and scene texts, for human-computer interaction. Complementary to text prompts, visual referring prompting provides a more nuanced and natural interaction. Conversely, GPT-4V can also generate visual pointing output in numerical text format for queried objects in an image. Using example-grounded instructions can help GPT-4V understand coordinate definitions and therefore generate better pointing. While output spatial regions are not precise, the approach enables an iterative pointing generation and understanding loop that can help complicated multi-hop grounded visual reasoning tasks.
Temporal and Video Understanding. To evaluate GPT-4V’s temporal and video understanding capabilities, a series of static images selected from video frames are used as inputs. On action recognition task from multi-image sequencing, GPT-4V can understand the sequence and context of various human poses and intelligently correlate them with the ongoing activity. Temporal ordering involves providing the model with a series of shuffled images and gauging its ability to discern cause and effect relationships as well as the correct temporal sequence. An understanding of such relationships requires the ability to reorder the sequence in a logically coherent and temporally accurate manner. GPT-4V is able to comprehend the images’ content and determine the correct temporal order corresponding to the specified action. Temporal anticipation involves anticipating future events given a set of initial frames. GPT-4V is able to accurately anticipate the subsequent steps for the given series of images in multi-step processes. Temporal localization involves identifying the frame when a specified event occurs and temporal reasoning involves understanding the dynamics of the interaction between objects in the images and predicting the outcome of these dynamics. GPT-4V shows the capability in temporal localization and reasoning in a soccer penalty kick example. Grounded temporal understanding involves understanding the activities of a pointed object in a sequence of image frames. GPT-4V can accurately describe events in a way that aligns with the corresponding temporal order and can distinguish between friendly or confrontational interactions.
Abstract Visual Reasoning and Intelligence Quotient Test. Similar to humans, GPT-4V can infer semantics from abstract and often ambiguous visual stimuli, such as tangram, ASCII text art, and symbolic inputs. GPT-4V is also capable of discovering and associating object parts to compose a semantically meaningful object. As a further challenge, GPT-4V is asked to perform different abstract reasoning tasks, sourced from the Wechsler Adult Intelligence Scale (WAIS) that is one of the standard human Intelligence Quotient (IQ) tests. GPT-4V shows promises in abstract reasoning and answering questions with texts only, symbolic visual inputs, and natural images. Raven’s Progressive Matrices (RPM) is another non-verbal intelligence test to measure abstract reasoning and problem-solving abilities. Each test sample contains three or eight images, arranged in 2-by-2 or 3-by-3 matrices with one figure missing. The goal is to select the next image from multiple candidate images by identifying patterns in the provided samples. When the entire question page is served as a single image, GPT-4V can generate reasonable answers; when the entire question image is broken down into interleaved text and sub-figures, GPT-4V produces more reliable answers.
Emotional Quotient Test. A chatbot is expected to have the empathy and Emotional Quotient (EQ) to understand and share the feelings of humans. This paper examines GPT-4V’s capability in (1) identifying and reading human emotions from their facial expressions, (2) understanding how different visual contents may arouse emotions, and (3) generating proper text outputs conditioned on the desired emotion and sentiment. GPT-4V can not only reliably identify and read the emotions of people from their facial expressions, but also provide reasonable rationales for making emotion interpretation from the visual cues in the given facial images. On the ability in understanding how visual content may arouse human emotions, GPT-4V can interpret visual sentiments such as content, anger, awe, and fear, based on both the semantic contents and the image style. In addition, GPT-4V aligns with human subjective judgments such as aesthetics, the perceived beauty or visual appeal of an object, design, or piece of art. On emotion conditioned output task, GPT-4V can generate proper text based on the perceived or desired emotions, making its communication with humans comforting and effective.
Emerging Application Highlights. Eight high-value application scenarios that can be performed by GPT-4V right out of the box are highlighted. How GPT-4V can integrate with external tools and plugins are also presented. (1) Spot the Difference is a game where two visually similar images that contain subtle differences in certain regions are provided for GPT-4V to identify all the differences between the two images. GPT-4V successfully identifies the regions or components that differ in the images, but can fail in providing accurate explanations for what is depicted in each image. While GPT-4V’s predictions in the “Spot the Difference” game are not perfect, its ability to compare the content in two images is valuable in real-life applications.
(2) Industry. Defect detection. Defect detection is an essential step in manufacturing processes to ensure product quality. Images of defective products are used to evaluate GPT-4V’s defect detection capabilities. GPT-4V can identify the defects in commonly encountered products, but may hesitate or even refuse to make predictions for defects in uncommon products or products with variations in appearance. Using the “Spot the Difference” idea by presenting a reference image to illustrate what a defect-free product should look like and refined prompt, in addition to the image of defective products, GPT-4V shows improved defect detection rate. Safety inspection. Safety regulations in working environments, such as construction sites, require wearing personal protective equipment (PPE), such as helmets, harnesses, and gloves. A safety monitoring system needs to accurately detect and report the number of employees who are not compliant. When an image of 8 workers is presented, GPT-4V fails to count correctly the number of persons not wearing helmet; but when the 8 cropped regions (cropped with an off-the-shelf person detector) are presented individually, GPT-4V can correctly count the person who is not wearing the helmet. Grocery checkout. GPT-4V has the potential to enable an automatic self-checkout system that can identify and ring up items without user intervention. When presented with a photograph of a shopping basket containing 5 grocery items, GPT-4V fails to accurately identify the products within the basket. When the prompt is augmented with catalog images of 9 grocery products that include the 5 in the shopping basket, GPT-4V successfully identifies all 5 items in the basket.
(3) Medical. The potential of GPT-4V in radiology report generation is explored. GPT-4V is provided with various medical images and tasked with generating complete radiology reports. The accuracy of the generated reports are evaluated by a medical professional. In one example, GPT-4V provided accurate diagnoses on an abdominal X-ray image and an MRI of the right knee. In another example on X-ray of the right hand and wrist, GPT-4V missed an obvious fracture in the X-ray image. In the 3rd example, GPT-4V made correct diagnosis on a brain MRI, but incorrect diagnosis and hallucinating measurements on a chest CT. The 4th example shows that previous X-ray image and diagnosis of the same patient can help GPT-4V to perform better on new image diagnosis.
(4) Auto Insurance. Application of GPT-4V in auto insurance is explored for damage evaluation (accurately identifying and assessing the extent of damages) and insurance reporting (including the recognition of vehicle-specific information depicted in images). For damage evaluation, GPT-4V has demonstrated remarkable proficiency in accurately identifying and precisely localizing the damages depicted in all four images. Furthermore, it is able to provide detailed descriptions of each specific damage instance and, in some instances, cost of repair estimate. For insurance report generation, GPT-4V is asked to evaluate the damage and identify the make, model, and license plate of the vehicle depicted in the image, and return the obtained information in JSON format. GPT-4V fails to read the license plate in one example, potentially due to occlusion.
(5) Customized Captioner. Reference images of individual family members (cropped from another image) and their names are provided with query image for GPT-4V to describe the query image in as many details as possible. GPT-4V can precisely identify the family members (including person, cat, and dog) to generate detailed and customized captions. Storing such captions for all the images in the family album holds the potential to enable highly personalized image search. GPT-4V’s performance on dense captioning can be enhanced by incorporating object cut-outs generated by Segment Anything Model (SAM) into the prompt that includes the original image as the global context and asks it to describe the object cut-outs as detailed as possible. The results show that GPT-4V can generate highly intricate dense captions for each object, some of which are accompanied by relevant references to the context image.
(6) Image Generation. Evaluation of generated images. GPT-4V can be used to evaluate how similar an image generated by a text-to-image model (e.g., RL-Diffusion, DeepFloyd IF, Midjourney V5.1, etc.) is to the prompt used to generate the image. GPT-4V can not only effectively rate the similarity between the generated image and the prompt, but also provide explanations for the deduction in similarity score, which can potentially be used as feedback to improve the image generation. Prompt generation for image editing. GPT-4V can also be used to generate or improve the text prompt for image editing (e.g., using Instruct Pix2Pix). By providing the original image and text requirements that describe the desired edits, GPT-4V produces an optimized prompt that takes into account the unique characteristics of the image, ensuring that the subsequent editing process is well-informed and effective. By providing the original image, the initial prompt, and the edited image, GPT-4V can generate an improved version of the prompt that incorporates the changes made during the previous editing process. This iterative process can be repeated until the edits achieve a satisfying outcome.
(7) Embodied Agent. Two scenarios are considered as if GPT-4V plays the role of a home robot: (i) reading the menu to operate household appliances (e.g., coffee machine), and (ii) performing task-oriented navigation through the house. Operating Machine. GPT-4V is asked to identify the button that corresponds to the “8 OZ coffee” option within the coffee machine’s operating panel, given a single image of an operating menu. GPT-4V mistakenly identifies the power button as the “6 OZ coffee” button. Navigation. GPT-4V is asked to “go to the kitchen and retrieve an item from the fridge” and “plan the next action”, given the image of the current position (and the image of the immediate previous turn) in a virtual house tour. Through a sequence of navigation actions, GPT-4V is able to accomplish the task-oriented navigation scenario.
(8) GUI Navigation. GPT-4V’s capability in navigating through the Graphical User Interface (GUI) of a computer or smartphone is explored for completing complex tasks, such as web browsing, online shopping, etc. Web browsing. GPT-4V is provided with the screenshot of current computer screen, the end goal of the navigation (e.g., finding a cooking recipe or reading today’s news), the list of possible actions (e.g., move the mouse, click an icon with the mouse, or type some texts with the keyboard). The model is then instructed to predict the subsequent actions. The predicted action is manually executed and the resulting screenshot is used as the input for the next turn. GPT-4V predicts reasonable actions to operate a computer GUI, and finally accomplishes the end goal. Online shopping. GPT-4V is provided with the screenshot of the current screen of a smartphone, the list of possible actions (e.g., move your finger to an icon, click an icon with your finger, scroll down a screen, or type some texts with the keyboard) and asked to predict the subsequent actions for online shopping. Through a sequence of 9 actions, GPT-4V is able to complete the shopping task. Notification understanding. GPT-4V can read and respond to a notification, such as suggesting to open the Maps app in response to a meeting proposal. It also handles call and message notifications on a computer screen effectively. Watching videos. GPT-4V is given screenshots of the video frames following their temporal order in the original video and asked to transcribe the video content. Regardless of whether the video has subtitle overlay or not, GPT-4V can generate insightful descriptions about the video content.
LMM Powered Agents. Five potential ways to enhance GPT-4V-based systems are explored using human-generated examples. (1) Multimodal Plugins. GPT-4V can acquire time-sensitive knowledge related to the input image by incorporating the Bing Image Search plugin. Without access to up-to-date information, GPT-4V fails to answer a question related to an event that took place after GPT-4V’s training. When equipped with the Bing Image Search plugin, it can leverage the retrieved information from the plugin to accurately answer the question. (2) Multimodal Chains. Large multimodal models can be integrated with a pool of multimodal plugins to enhance reasoning and interactions. In the example of helmet-wearing worker counting scenario, GPT-4V is extended with ReAct[86][87] to synergize reasoning and acting in two rounds of thought, action, and observation, with each round involving the activation of a specific plugin. In the first round, the person detection tool is called to obtain the coordinates of bounding boxes for each detected person in the image; in the second round, the image cropping tool is called to crop out individual images of each person according to their corresponding bounding box coordinates. GPT-4V subsequently determines whether each person in these images is wearing a helmet or not, and summarizes the total count of people wearing helmets. (3) Self-Reflection. A self-reflection agent[88] learns to optimize its own behavior using self-generated feedback for its own output. On task to generate code to draw similar figures, GPT-4V’s performance is improved using self-reflection. On the task of generating text prompts for a text-to-image model SDXL, self-reflection made GPT-4V to reflect the error in the initial prompt and make the correct revision. (4) Self-Consistency. On the task of counting the number of boats in a given image, GPT-4V’s reliability is improved with self-consistency[36], which aggregates multiple counting results repeated on the same image, by either conducting multiple runs or rephrasing the input text instruction. (5) Retrieval-Augmented LMMs. On grocery checkout task, the retrieved reference images of products improved GPT-4V performance.
GPT-4 Turbo
GPT-4 Turbo was launched on November 6, 2023[84]. It has knowledge of world events up to April 2023 and supports a 128k context window that can fit the equivalent of more than 300 pages of text in a single prompt.
GPT-4 Turbo performs better than previous versions on tasks that require the careful following of instructions, such as generating specific formats (e.g., “always respond in XML”). It also supports JSON mode, which ensures the model will respond with valid JSON. The new API parameter response_format enables the model to constrain its output to generate a syntactically correct JSON object. JSON mode is useful for developers generating JSON in the Chat Completions API outside of function calling.
Developers can now specify seed parameter in the Chat Completion request for consistent completions most of the time. This feature is useful for use cases such as replaying requests for debugging, writing more comprehensive unit tests, and generally having a higher degree of control over the model behavior. Another new feature is to return the log probabilities for the most likely output tokens, which will be useful for building features such as autocomplete in a search experience.
GPT-4 Turbo with vision accepts images as inputs in the Chat Completions API, enabling use cases such as generating captions, analyzing real world images in detail, and reading documents with figures. For example, BeMyEyes uses this technology to help people who are blind or have low vision with daily tasks like identifying a product or navigating a store. Developers can access this feature by using gpt-4-vision-preview in the API.
GPT-4 Turbo also offers an experimental access program for GPT-4 fine-tuning. In addition, a very limited (and expensive) Custom Models program is launched to give selected organizations an opportunity to work with a dedicated group of OpenAI researchers to train custom GPT-4 to their domain-specific large proprietary datasets—billions of tokens at minimum. This includes modifying every step of the model training process, from doing additional domain specific pre-training, to running a custom RL post-training process tailored for the specific domain. Organizations will have exclusive access to their custom models.
LaMDA
Thoppilan et al. (2022)[9] introduced LaMDA (Language Models for Dialog Applications) that is a family of large-scale decoder-only Transformer models specialized for dialog. It is pre-trained on a dataset of 1.56T words from public dialog data and other web documents, and then fine-tuned for quality and safety to obtain LaMDA-Base, and then fine-tuned for factual groundedness to obtain LaMDA-Research. At inference time, it generates candidate responses that are then filtered for safety, grounded on an external knowledge source, and re-ranked to find the highest-quality response. The results show that scaling alone improves all three metrics, but the improvements are far behind human performance. Fine-tuning with crowdworkers-annotated data and enabling interaction with external knowledge sources significantly improve all three metrics at all three scales, with quality and safety reaching human performance, but groundedness still far below human performance.
Pre-Training
The pre-training data, called Infiniset, is a combination of dialog data and other public web documents, including 1.12B dialogs with 13.39B utterances and 2.97B documents. Its composition is 50% dialogs data from public forums, 12.5% C4 data (Colossal Clean Crawled Corpus introduced for T5 model), 12.5% code documents, 12.5% Wikipedia (English), 6.25% English web documents, and 6.25% Non-English web documents. This composition was chosen to achieve a more robust performance on dialog tasks while still keeping its ability to perform other tasks like code generation. The dataset is tokenized with the SentencePiece library and a vocabulary of 32K tokens into 2.81T byte pair encoding (BPE) tokens. The model is pre-trained to predict the next token for a given context. Three model sizes are trained, as listed below. The pre-trained model, denoted as PT, uses sample-and-rank strategy for response generation, same as Meena, where 16 independent candidate responses are randomly sampled from top-k (k=40) highest probable responses and the final output is selected by the highest length-normalized log-likelihood score.

Metrics
Overall quality is evaluated by SSI metric, an average of sensibleness, specificity, and interestingness. Sensibleness measures whether a response makes sense in context and does not contradict anything that was said earlier. Specificity measures whether a response is specific to a given context. Interestingness measures whether a response is likely to “catch someone’s attention” or “arouse their curiosity”, or whether it is unexpected, witty, or insightful. Each of the three metrics is evaluated by human annotators using binary labels. In addition to quality, the foundation metrics also include safety and groundedness. Safety metric measures whether a response is harmful, biased, misinformative, incomprehensible, or otherwise undesirable, which is evaluated by human annotators using binary labels. Groundedness is defined as the percentage of responses containing claims about the external world that can be supported by authoritative external sources, as a share of all those containing claims about the external world. Informativeness is defined as the percentage of responses that carry information about the external world that can be supported by known sources, as a share of all responses. Informativeness only differs from groundedness in the denominator term. Citation accuracy is defined as the percentage of model responses that cite the URLs of their sources as a share of all responses with explicit claims about the external world, excluding claims with well-known facts. Two role-specific metrics for dialog agents are also measured: Helpfulness and Role consistency. Helpful responses are a subset of informative ones, which are judged by users to be both correct (based on the user’s independent research with an information retrieval system) and useful. Role consistency refers to consistency with the definition of the agent’s role external to the conversation, which measures whether responses look like something an dialog agent performing the target role would say.
Datasets for Fine-Tuning and Evaluation
Fine-tuning dataset for quality (SSI) improvement consists of 6400 dialogs with 121K turns (14~30 turns per dialog), collected by crowdworkers through interacting with a LaMDA instance on any topic. For each response, other crowdworkers rate whether the response given the context is sensible, specific, and/or interesting, and mark each ‘yes’, ‘no’, or ‘maybe’ labels. Responses are not rated positively for specificity if they are not sensible, and not rated positively for interestingness if they are not specific. Every response is labeled by 5 different crowdworkers and the response is considered sensible, specific or interesting if at least 3 out of 5 crowdworkers mark it ‘yes’. Evaluation dataset for quality is the Mini-Turing Benchmark (MTB) dataset[10], which consists of 1477 dialogs, including 315 single-turn dialogs, 500 2-turn dialogs, and 662 3-turn dialogs. These dialogs are fed to a model to generate the next response that is then labeled sensible, specific or interesting if at least 3 out of 5 crowdworkers mark it ‘yes’.
Fine-tuning dataset for safety consists of 8K dialogs with 48K turns (5~10 turns per dialog), collected by crowdworkers through interacting with a LaMDA instance in response to human-generated prompts in three different ways: (a) interactions of natural form, (b) interactions that touch sensitive topics, and (c) interactions that adversarially attempt to break the model as per the safety objectives. For each response, other crowdworkers rate whether the response given the context violates any of the safety objectives, and mark them with ‘yes’, ‘no’, or ‘maybe’ labels. Every response is assigned a safety score of 1 if at least 2 out of 3 crowdworkers mark the response with ‘no’ for each individual safety objective. Otherwise, it is assigned a score of 0. The safety objectives are (1) to avoid unintended results that create risks of harm, (2) to avoid unjust impacts on people, particularly those related to sensitive characteristics associated with systemic discrimination or marginalization, and (3) to avoid propagating or reinforcing misinformation that creates risk of harm, as well as opinions likely to incite strong disagreement. Evaluation dataset for safety consists of 1166 dialogs with 1458 turns, which is a holdout sample of the adversarially collected dataset described above. These dialogs are fed to a model to generate the next response that is then scored 1 if at least 2 out of 3 crowdworkers mark each safety objective ‘no’ and 0 otherwise.
Fine-tuning dataset for groundedness consists of 4K dialogs with 40K turns, collected by crowdworkers through information-seeking interactions with a LaMDA instance. For each model’s response, crowdworkers evaluate whether the information in the response makes any factual claims about the external world (excluding claims about publicly unrecognized people). Then, crowdworkers determine whether they know the claims to be true. If 3 different crowdworkers all know a claim to be true, it is assumed to be common knowledge and does not need to be checked before making this claim. For those that need to be checked, crowdworkers record the search queries that they would use to check external knowledge sources. Finally, crowdworkers edit the model’s response to incorporate brief search results from an external knowledge-retrieval system. If the search results include any content from the open web, crowdworkers include the URLs that cite the sources of the knowledge in the final response. Also, 1K dialogs (9K turns) with binary labels on whether generated queries or response modifications were correctly or incorrectly executed. Evaluation dataset for groundedness consists of 784 turns of dialogs from Wizard of Wikipedia[11] that encompass a variety of topics. These contexts are fed to a model to generate the next response that is then rated whether the response contains any factual claims, and if so, rated whether these factual claims can be verified by checking a known source. Every response is rated by 3 different crowdworkers. The final groundedness, informativeness, and citation accuracy labels of a given response are determined by majority voting.
A set of human-generated responses is created by crowdworkers through responding to randomly selected samples of the three evaluation datasets above. The crowdworkers are explicitly informed to reply in a safe, sensible, specific, interesting, grounded, and informative manner, and to use any external tools (including an information retrieval system) necessary to generate these responses. The context-response pairs are then sent for evaluation, and a consensus label is formed by majority voting.
Fine-tuning
Two levels of fine-tuning are performed. For quality and safety, the pre-trained model (PT) is fine-tuned to train discriminators that predict quality and safety labels. The generated candidate responses are filtered at inference time by their safety scores, and re-ranked by a weighted sum of the three quality score types. PT is also fine-tuned to generate in-context responses from a clean sample of pre-training dialog data filtered using LaMDA discriminators. The resulting model is termed LaMDA-Base. For factual groundedness, an instance of LaMDA-Base is fine-tuned to generate calls to an external information retrieval system to provide attributed responses. The model is also fine-tuned to jointly predict the quality and the type (i.e., calling a certain tool or replying to the user) of the next action. The resulting model is termed LaMDA-Research.
Fine-tuning for Quality (SSI) and Safety
A single model that can function as both a generator and a discriminator is obtained by fine-tuning PT on a mix of generative tasks that generate response given contexts and discriminative tasks that evaluate quality and safety of a response in context. All fine-tuning examples are expressed as sequences of tokens. Generative fine-tuning examples are expressed as “<context><sentinel><response>” (e.g. “What’s up? RESPONSE not much.”), with losses applied only for the response portion. Discriminative fine-tuning examples are expressed as “<context><sentinel><response><attribute-name><rating>” (e.g. “What’s up? RESPONSE not much. SENSIBLE 1”), with losses applied only for the rating. Such model enables an efficiently combined generate-and-discriminate procedure. After generating a response given a context, evaluating a discriminator involves computing P(“<desired-rating>”|”<context><sentinel><response><attribute-name>”). Since the model has already processed “<context><sentinel><response>”, evaluating the discriminator simply involves processing a few additional tokens: “<attributename><desired rating>”. The discriminator can be used to predict the SSI and safety ratings of the generated candidate responses, which is in turn used to filter out candidate responses for which the model’s safety prediction falls below a threshold during generation. Candidate responses that remain after filtering for safety are then ranked for quality. During ranking, sensibleness is given a weight three times higher than specificity and interestingness, as this was found to work well for all metrics (i.e., \(3\times P(sensible)+P(specific)+P(interesting)\)). The top ranked candidate is selected as the next response. LaMDA SSI and safety discriminators are also used to score and filter 2.5M turns of dialog data sampled from the pre-training dataset, resulting in 800K turns of safe, sensible, specific and interesting dialogs that are used to further fine-tune the LaMDA model.
Fine-tuning for Factual Groundedness
For factual groundedness, the fine-tuning is to learn to consult a toolset (TS) that includes an information retrieval system, a calculator, and a translator. The TS, and each tool in the TS, takes a single string as input and returns a list of strings. For example, the calculator takes “135+7721” and returns [“7856”]; the translator takes “Hello in French” and returns [“Bonjour”]; the information retrieval system takes “How old is Rafael Nadal?” and returns [“Rafael Nadal / Age / 35”]. The information retrieval system is also capable of returning snippets of content from the open web, with their corresponding URLs. Given a general text query, the information retrieval system returns a set of brief, text-only snippets in rank order. The TS tries an input string on all of its tools, and produces a final output list of strings by concatenating the output lists from every tool in the following order: calculator, translator, and information retrieval system. A tool will return an empty list if it cannot parse the input, and will not contribute to the final output list. The interface to the TS used here is identical to the service used by the algorithm at inference time.
The fine-tuning is to learn to perform two tasks, which are collectively referred to as ‘research’. The first task is to predict a query to be sent to the TS, given a dialog context so far and the response generated by the LaMDA-Base. It is denoted as \(context+base\rightarrow\)“TS, query”. The query generation is entirely based on the model fine-tuning, and there is no heuristic component. The second task is to predict a grounded response or an additional research query, given a dialog context so far, the generated response, the query, and a snippet returned by a tool. It is denoted as \(context+base+query+snippet\rightarrow\)“User, grounded response” or \(context+base+query+snippet\rightarrow\)“TS, another query”. At inference time, the model’s output is directed to the information retrieval system or to the user, depending on whether the first generated string is ‘TS’ or ‘User’. The research loop continues until the model generates output addressed to the user. At inference time, a maximum number of queries is imposed, as a parameter of the serving model, to eliminate the possibility of an infinite loop. The process is illustrated in the Figure below.
Results
Quality metrics (sensibleness, specificity, and interestingness) generally improve with model size with or without fine-tuning, but they are consistently better with fine-tuning. Safety does not seem to benefit much from model scaling without fine-tuning, but improves significantly from scaling accompanied with safety fine-tuning. Groundedness improves as model size increases, but fine-tuning allows the model to access external knowledge sources, achieving 73.2% Groundedness and 65% Citation Accuracy. In summary, scaling up alone improves the pre-trained model on quality and groundedness metrics, but it does not improve safety much. Fine-tuning with crowdworker-annotated data significantly improves all metrics. The fine-tuned models almost reach the crowdworker quality levels on sensibleness, specificity, and safety, and exceed crowdworker quality for interestingness. However, crowdworker quality level may be a weak baseline as crowdworkers are not extensively trained and were not incentivized to generate high-quality responses. On informativeness, LaMDA outperforms crowdworkers when crowdworkers do not have access to information retrieval tools, but far underperforms crowdworkers when crowdworkers have access to those tools. On groundedness, LaMDA far underperforms crowdworkers regardless of whether crowdworkers have access to information retrieval tools or not.
Domain Grounding
Domain grounding refers to the process of pre-conditioning a model to perform a domain-appropriate, a.k.a. application-specific, role, which is similar to the prompts in InstructGPT. Two examples are explored in this paper: (1) LaMDA playing the role of Mount Everest for the purpose of education, and (2) LaMDA playing the role of a music recommendation agent. The precondition here is a few turns of role-specific dialogs. The same preconditions are used for both LaMDA and PT. To adapt the models to the Mount Everest role, the precondition is a single greeting message “Hi, I’m Mount Everest. What would you like to know about me?” at the very beginning of the dialog. For the music recommendation agent role, the precondition is a special 6-turn dialog at the very beginning of the dialog. The longer precondition for music is to establish not only the target role, but also the style of the interaction with the user (e.g., brief responses containing the name of a song).
To evaluate the agents, crowdworkers have dialogs with the models to produce 600 dialog turns in total. Another set of crowdworkers then label each of the generated responses in their original context according to whether they are role-consistent and helpful relative to their target roles. Each response is labeled three times by different crowdworkers. LaMDA applications significantly outperforms PT applications on Helpfulness. All LaMDA and PT instances score fairly well on role consistency, occasionally breaking character (i.e., not playing the appropriate role). The role consistency is surprisingly high, especially in the case of Mount Everest, which was adapted by simply adding a single role-aligned greeting statement. LaMDA Music uses 6-turn dialogs as grounding so that it can interpret ambiguous user utterances like “anything” to mean “recommend me any music”. During evaluation, crowdworkers use an information retrieval system to verify links and information that the model provides. Broken links and information that cannot be backed by known sources are labeled as not helpful. In about 30% of responses produced by LaMDA Mount Everest, facts could not be attributed to known sources, resulting in losses in helpfulness. In about 9% and 7% of responses produced by LaMDA Music, actual music recommendation was not provided and a broken link was provided, respectively.
FLAN
Wei et al. (2021)[5] take LaMDA-PT model (pretrained LaMDA without finetuning for dialog) of 137B parameters and perform instruction tuning (finetuning with natural language instructions) on the model using a mixture of more than 60 NLP datasets. The resulting model is referred to as FLAN, for Finetuned Language Net. The idea of instruction tuning is that by using supervision to teach an LM to perform tasks described via instructions, the LM will learn to follow instructions and do so even for unseen tasks.
Instruction tuning datasets are created by transforming existing datasets from the research community into an instructional format. 62 public text datasets on Tensorflow Datasets are categorized into 12 task clusters, for which datasets in a given cluster are of the same task type, as shown in the Figure below. 10 unique instruction templates are manually composed for each dataset, which use natural language instructions to describe the task for that dataset. To increase diversity, up to three templates for each dataset “turned the task around”, e.g., for sentiment classification, templates asking to generate a movie review are included. Then, instruction tuning is performed on the mixture of all datasets, with examples in each dataset formatted via a randomly selected instruction template for that dataset.
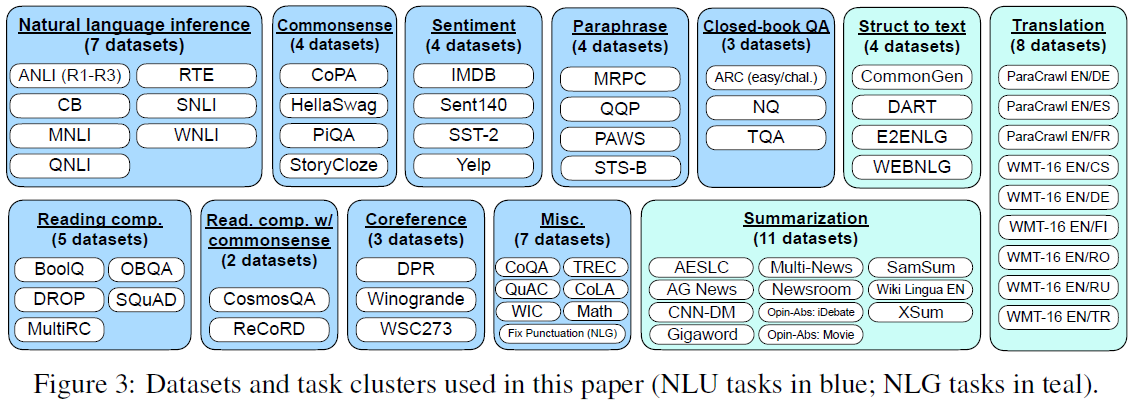
In this study, a dataset \(\mathcal{D}\) is considered as unseen at evaluation time only if no datasets from any task clusters that \(\mathcal{D}\) belongs to were seen during instruction tuning. To evaluate zero-shot FLAN on \(n\) task clusters, \(n\) models are instruction-tuned, where each model holds out a different task cluster for evaluation. For classification tasks, the OPTIONS token is appended to the end of a classification task along with a list of the output classes for that task. This makes the model aware of which choices are desired when responding to classification tasks.
FLAN is the instruction-tuned version of LaMDA-PT 137B model. The instruction tuning pipeline mixes all datasets and random samples from each dataset. To balance the different sizes of datasets, the number of training examples per dataset is limited to 30k and follow the examples-proportional mixing scheme with a mixing rate maximum of 3k (meaning a dataset does not receive additional sampling weight for examples in excess of 3k). All models are finetuned for 30k gradient steps with a batch size of 8,192 tokens using the Adafactor Optimizer. The input and target sequence lengths used in finetuning are 1024 and 256, respectively. Multiple training examples are combined into a single sequence, separating inputs from targets using a special EOS token. This instruction tuning takes around 60 hours on a TPUv3 with 128 cores. For all evaluations, results are reported on the final checkpoint trained for 30k steps.
FLAN is evaluated on natural language inference, reading comprehension, closed-book QA, translation, commonsense reasoning, coreference resolution, and struct-to-text tasks. For each dataset, the mean of performance on all templates is used as a proxy of the expected performance given a typical natural language instruction. When a dev set is available from a dataset, the test set performance of the dataset is obtained by using the template with the best dev set performance. With the best dev template, zero-shot FLAN outperforms zero-shot GPT-3 175B on 20 of 25 datasets and even surpasses GPT-3’s few-shot performance on 10 datasets. With the best dev-template, zero-shot FLAN outperforms zero-shot GLaM 64B/64E on 13 of 19 available datasets and one-shot GLaM on 11 of 19 datasets. Overall, instruction tuning is very effective on tasks naturally verbalized as instructions (e.g., NLI, QA, translation, struct-to-text) and is less effective on tasks directly formulated as language modeling, where instructions would be largely redundant (e.g., commonsense reasoning and coreference resolution tasks that are formatted as finishing an incomplete sentence or paragraph). These results indicate that when the downstream task is the same as the original language modeling pre-training objective where instructions are largely redundant, instruction tuning is not useful. Generally, zero-shot FLAN outperforms zero-shot LaMDA-PT and is comparable with or better than few-shot LaMDA-PT.
An ablation study examines how performance is affected by the number of clusters and tasks used in instruction tuning. The results show that average performance across held-out clusters improves as more clusters and tasks are used to instruction tuning, confirming the benefits of this instruction tuning approach on zero-shot performance on novel tasks. The second ablation study explores how the benefits of instruction tuning are affected by model scale over 422M, 2B, 8B, 68B, and 137B parameters. The results show that for the two models on the order of 100B parameters, instruction tuning substantially improves performance on held-out tasks. However, for the 8B and smaller models, instruction tuning actually hurts performance on held-out tasks. The third ablation study explores the role of instructions during finetuning. Two finetuning setups without instructions are considered: (1) no template setup, where only inputs and outputs are given to the model (e.g., for translation the input would be “The dog runs.” and the output would be “Le chien court.”), (2) dataset name setup, where each input is prepended with the name of the task and dataset (e.g., for translation to French, the input would be “[Translation: WMT’14 to French] The dog runs.”). The two setups are compared to FLAN’s finetuning procedure, which used natural instructions (e.g., “Please translate this sentence to French: ‘The dog runs.’”). Evaluations are performed for four held-out clusters: natural language inference, reading comprehension, closed-book QA, and translation. For the no template setup, the FLAN instructions are used during zero-shot inference. For models finetuned on dataset name only, zero-shot performance is reported for FLAN instructions as well as using the dataset name. The results show that both ablation setups performed substantially worse than FLAN, indicating that finetuning with instructions is crucial for zero-shot performance on unseen tasks.
It was also studied how instruction tuning can be used when few-shot exemplars are available at inference time. The instruction for the few-shot setting is built from the zero-shot instructions. Let instruct(\(x\)) denote the zero-shot instructions for input \(x\) and output \(y\). Then, given \(k\) few-shot exemplars \((x_{i},y_{i})_{i=1}^{k}\) and a new input \(x\), the instruction format for the few-shot setting is “instruct(\(x_{1}\))\(\oplus y_{1}\oplus\)instruct(\(x_{2}\))\(\oplus y_{2}\oplus\cdots\oplus\)instruct(\(x_{k}\))\(\oplus y_{k}\oplus\)instruct(\(x\))”, where \(\oplus\) denotes string concatenation with a delimiter token inserted in between. At both training and inference time, exemplars are randomly drawn from the training set, and the number of exemplars is capped at 16 such that the total sequence length is less than 960 tokens. The same task splits and evaluation procedure as in zero-shot experiments are used for few-shot exemplars and only unseen task are used at inference time. The results show that FLAN finetuned with few-shot exemplars performs modestly better than zero-shot FLAN on all task clusters. Exemplars are especially effective for tasks with large/complex output spaces, such as struct to text, translation, and closed-book QA, potentially because exemplars help the model better understand the output format. In addition, for all task clusters, standard deviation among templates is lower for few-shot FLAN, indicating reduced sensitivity to prompt engineering.
Prompt tuning[58] prepends additional tunable tokens (also referred to as “soft tokens”) per downstream task to the input text. Then, the entire pre-trained model parameters are fixed while the soft tokens are optimized during finetuning. It has been shown that prompt tuning alone is sufficient to be competitive with model tuning. If FLAN is more amenable to performing NLP tasks, then it should also achieve better performance when performing inference using soft prompts. To test this idea, soft prompts for each of the SuperGLUE tasks are trained in accordance with the same cluster splits scheme such that when prompt-tuning on task \(T\), no tasks in the same cluster as \(T\) were seen during instruction tuning. The results show that prompt tuning works better with FLAN than with LaMDA-PT. In many cases, especially for the low-resource setting, prompt tuning on FLAN even achieves more than 10% improvement over prompt tuning on the LaMDA-PT. This result indicates that instruction tuning facilitates prompt tuning.
Instruction tuning demonstrates how labeled data can be used to help LLMs perform many, unseen tasks. The positive effect of instruction tuning on cross-task generalization shows that task-specific training is complementary to general language modeling, although performance improvements from instruction tuning emerge only with sufficient model scale.
Three limitations are highlighted: (1) only the use of relatively short instructions of typically a single sentence is explored, (2) evaluation examples might have appeared in the models’ pretraining data, although no evidence that data overlap substantially impacted the results was found in post-hoc analysis, (3) the scale of FLAN 137B makes it costly to serve. In addition to the risks and potential harms common to all LLMs, two additional relevant ethical considerations are highlighted: (i) labeled datasets used for instruction tuning can contain undesirable biases, and these biases can be propagated into zero-shot applications of the model on downstream tasks, (ii) instruction-tuned models can potentially require less data and expertise to use; such lower barriers to access could increase associated risks of such models.
PaLM
Chowdhery et al. (2022)[23] introduced Pathways Language Model (PaLM) that is a 540 billion parameter, densely activated, decoder-only Transformer, trained on 780 billion tokens of high-quality text. The training used Pathways infrastructure[24], a large scale orchestration layer for accelerators which enables highly efficient training of very large neural networks across thousands of accelerator chips, including those spanning multiple Tensor Processing Units (TPU) v4 Pods. At the time of its publication, PaLM achieves state-of-the-art few-shot results across hundreds of natural language, code, and mathematical reasoning tasks, with breakthrough performance on a number of these tasks.
PaLM’s architecture has 7 modifications from standard Transformer architecture. (1) SwiGLU Activation: SwiGLU[25] activations (\(\mathrm{Swish}(xW)\cdot xV\)) is used for the MLP intermediate activations, where Swish[26] is the activation function \(f(x)=x\cdot\mathrm{sigmoid}(\beta x)\), where \(\beta\) is a constant or trainable parameter. This has been shown to improve quality over ReLU, GeLU, and Swish in compute-equivalent experiments. (2) Parallel Layers: The standard “serialized” formulation of each Transformer block, \(y=x+\mathrm{MLP}(\mathrm{LayerNorm}(x+\mathrm{Attention}(\mathrm{LayerNorm}(x))))\), is replaced by a “parallel” formulation, \(y=x+\mathrm{MLP}(\mathrm{LayerNorm}(x))+\mathrm{Attention}(\mathrm{LayerNorm}(x))\) that results in roughly 15% faster training speed at large and neutral effect on quality. (3) Multi-Query Attention: The “key” and “value” projections are shared for each head, i.e. “key” and “value” are projected to \([1,h]\), but “query” is still projected to shape \([k,h]\), where \(k\) is the number of attention heads and \(h\) is the attention head size. This results in a significant cost savings at autoregressive decoding time, compared to standard Transformer attention where the key/value tensors are not shared. (4) RoPE Embeddings: Rotary Position Embedding (RoPE)[27], instead of absolute or relative position embeddings, is used for better performance on long sequence lengths. (5) Shared Input-Output Embeddings: The input and output embedding matrices are shared. (6) No Biases: No bias term is used in any of the dense kernels or layer norms, resulting in increased training stability for large models. and (7) Vocabulary: The SentencePiece[28] vocabulary with 256k tokens were chosen for improved training efficiency. The tokenized vocabulary is lossless and reversible, which means that (i) whitespace is completely preserved, (ii) out-of-vocabulary Unicode characters are split into UTF-8 bytes, one token per byte, and (iii) numbers are always split into individual digit tokens.
Three model scales, as shown below, are built. The number of FLOPs per token is approximately equal to the number of parameters, since these models are standard dense Transformers. The three models were trained identically (except batch size) using the same data and vocabulary.
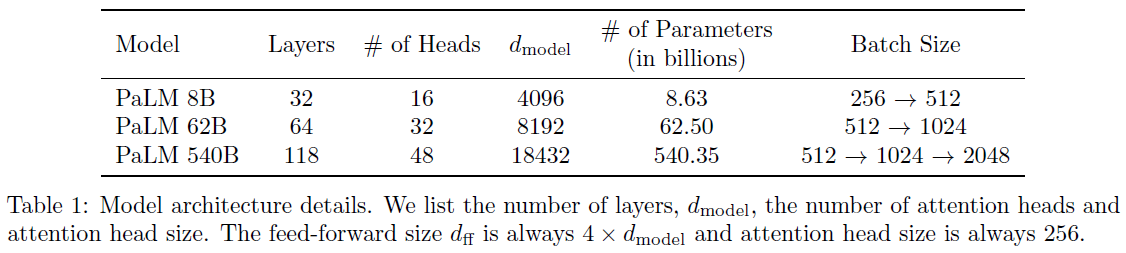
All the three models are pre-trained on exactly one epoch of the dataset that consists of a mixture of filtered webpages, books, Wikipedia, news articles, source code (in 24 common programming languages from open-source repositories on GitHub, with duplicates removed), and social media conversations. The proportions of various data sources are listed below.

Training efficiency is measured with a new metric called model FLOPs utilization (MFU), defined as \(\frac{observed\ throughput\ (tokens-per-second)}{theoretical\ maximum\ throughput}\), to replace the metric called hardware FLOPs utilization (HFU), \(\frac{FLOPs\ observed}{theoretical\ peak\ FLOPs}\), because (1) HFU is system-dependent and implementation-dependent, and (2) measuring observed hardware FLOPs is dependent on methodology used to count or track them. The theoretical maximum throughput is calculated as \(\frac{P}{(6N+12LHQT)}\) where N, L, H, Q, and T are the number of parameters, the number of layers, the number of heads, the head dimension, and the sequence length, respectively, (for FLOPs per token) of a given model and the P is the total theoretical peak matmul throughput (in FLOPs per second) of a given group of accelerators. The model FLOPs utilization of PaLM and 3 prior large models are shown in the table below. PaLM achieves significantly higher accelerator utilization because of its parallelism strategy and several other factors, including XLA TPU compiler optimizations, and the use of “parallel layers” formulation.
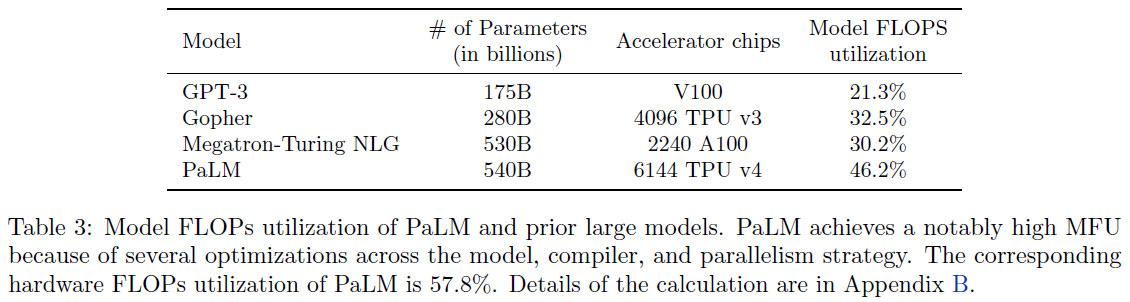
PaLM is evaluated on 29 common natural language benchmarks (8 Natural Language Generation and 21 Natural Language Understanding), in order to compare with prior LLMs (GLaM 62B/64E, GPT-3 175B, Megatron-Turing NLG 530B, LaMDA, and Chinchilla). PaLM 540B outperforms prior SOTA on 24 of the 29 tasks in the 1-shot setting and 28 of the 29 tasks in the few-shot setting. In the few-shot setting, PaLM 540B outperforms prior SOTA by more than 10 points on some of the Reading Comprehension and Natural Language Inference tasks. PaLM 540B outperforms a similar sized model, Megatron-Turing NLG 530B, on all benchmarks, indicating that not only model size, but also the pretraining dataset, training strategy, and the number of tokens observed during training play a significant role in achieving these results.
PaLM 540B also outperforms the Chinchilla model, the prior SOTA of the Massive Multitask Language Understanding (MMLU) benchmark[62], by nearly 2 points on the average score of the 57 different tasks of the MMLU.
Finetuning experiments for PaLM are conducted on the SuperGLUE benchmark, to be compared with prior SOTA models T5-11B and ST-MoE-32B. The finetuned PaLM 540B obtains competitive close-to-SOTA performance. It is worth noting that both T5-11B and ST-MoE-32B are encoder-decoder models that are trained using the span corruption objective. It has been shown that encoder-decoder architecture will generally outperform autoregressive decoder-only models on classification task finetuning, when training cost is equalized. The performance gap of fine-tuned decoder-only model can be reduced by scaling-up, as demonstrated here by the finetuned PaLM 540B. Comparing PaLM-540B few-shot and finetuned results on SuperGLUE dev set demonstrates that few-shot still significantly underperforms finetuned. Results on the test set of the SuperGLUE leaderboard show that finetuned PaLM 540B is competitive with ST-MoE-32B (the then SOTA) while outperforming the then best decoder-only autoregressive language model, GPT-3 175B, by a wide margin.
BIG-bench (Beyond the Imitation Game Benchmark) is a collaborative benchmark that includes over 150 tasks covering logical reasoning, translation, question answering, mathematics, and others. BIG-bench evaluations show that PaLM significantly outperforms GPT-3, Gopher, and Chinchilla, and 5-shot PaLM 540B achieves a higher score than the average score of the humans asked to solve the same tasks. The performance of PaLM models as a function of scale appears to follow log-linear behavior, indicating that further scaling up is likely to result in increased performance. There are three types of interesting performance characteristics among the tasks: (1) the performance follows a log-linear scaling curve on the two tasks, \(\mathrm{goal\_step\_wikihow}\) and \(\mathrm{logical\_args}\), with the PaLM 540B model achieving accuracy close to the best human performance; (2) the performance follows a discontinuous improvement curve (the improvement from 62B to 540B is much larger than from 8B to 62B) on the two tasks, \(\mathrm{english\_proverbs}\) and \(\mathrm{logical\_sequence}\), implying that certain capabilities, such as abstract reasoning capability to understand complex metaphors, of the model only emerge once a certain scale is reached; (3) on some tasks, such as \(\mathrm{navigate}\) and \(\mathrm{mathematical\_induction}\), PaLM 540B only modestly outperforms PaLM 62B and is still far below the best human performance score, suggesting a high variance in the example-level difficulty of the tasks. Although PaLM 540B outperforms the average human performance on aggregate, the average human performance is still higher than PaLM 540B on 35% of the individual tasks, indicating that there is still significant room for improvement on BIG-bench. Three steps were taken to rule out the possibility that the model achieved the above average human performance by memorizing the BIG-bench data during training: (1) it was ensured that the unique canary string included in the BIG-bench task files does not appear in the PaLM training data; (2) the BIG-bench dataset was not available on the Internet at the time the training data was collected, and the vast majority of BIG-bench tasks were newly constructed specifically for inclusion in BIG-bench; (3) the model inputs and outputs on several tasks where the model showed strong performance were spot-checked and manually verified no information leaked from the gold labels during decoding.
Multi-step reasoning ability of PaLM is evaluated with two categories of reasoning benchmarks are used: (1) arithmetic reasoning benchmarks (e.g., GSM8K, SVAMP, MAWPS, and AQuA) that requires multi-step logical inference to solve grade-school level natural language math problems, and (2) commonsense reasoning benchmarks (e.g., CommonsenseQA and trategyQA) that requires strong world knowledge and chaining multiple logical inferences about the world. Most previous work combines domain-specific architectures, task-specific finetuning, and task-specific verifiers to achieve strong results on reasoning tasks. In this work, the tasks are simply represented via few-shot prompting. Chain-of-thought (CoT) prompting method[29] is used in the few-shot setting, where a series of intermediate reasoning steps are manually written for the few-shot exemplars, and the model will then generate its own chain-of-thoughts before generating the final answer for a test example. Only the final answer is used for evaluation. Using 8-shot chain-of-thought prompting in combination with an external calculator on the arithmetic datasets GSM8K, PaLM 540B achieves a performance of 58%, which outperforms the prior SOTA of 55%. 8-shot prediction with PaLM 540B+chain-of-thought also achieved SOTA accuracy on 3 other reasoning tasks (MAWPS, SVAMP, StrategyQA), and close to SOTA on 3 additional reasoning tasks (ASDiv, AQuA, CommonsenseQA).
PaLM’s coding ability is evaluated with 3 text-to-code tasks (HumanEval, MBPP, and GSM8K-Python) and 2 code-to-code tasks (TransCoder and DeepFix). In HumanEval and MBPP, the goal is to generate a short Python program, usually a single function, for a given English-language description and a small number of input-output examples. In GSM8K-Python, the goal is to produce a Python program that returns a correct solution for a given mathematics word problem with few-shot exemplars. In TransCoder, the task is to translate a C++ program to a Python program. In DeepFix, the task is to modify a broken C program that fails to compile, with compiler error provided, so that it will compile successfully. The \(pass@k\) metric is used to report the results, where \(k\) samples are drawn from the model for each problem, and the percentage of samples that solves the task is reported. A problem is counted as solved if any sample solves it. For \(k=1\), greedy decoding is used; for \(k>1\), nucleus sampling is used, with \(p=0.95\) and temperature 0.8. Two models, LaMDA 137B and Codex 12B, are used as comparison for the coding tasks. LaMDA was not trained on any code from GitHub, but it has some ability to do program synthesis, because about 18B or 12.5% of the LaMDA pretraining mixture were from coding Q&A and tutorials web sites. Codex model is a GPT model finetuned on 100B of Python only code from GitHub. An additional dataset called ExtraPythonData containing 5.8B tokens from GitHub is used to finetune PaLM 540B; the resulting model is called PaLM-Coder 540B. The LaMDA model has nonzero performance across all tasks, even though it was not trained on GitHub code, indicating that the code web documents used in the LaMDA training are informative for these coding tasks. The PaLM 540B substantially outperforms LaMDA across all 5 coding tasks, and performs comparably to Codex 12B, albeit being trained only on 50 times less amount of Python code than the Codex models. The nearly SOTA coding performance of PaLM 540B may be due to (1) transfer learning from other programming languages and from natural language data and (2) the observation that larger models can be more sample efficient than smaller models. PaLM-Coder 540B, from finetuning PaLM 540B, further outperforms Codex 12B and PaLM 540B, achieving 88.4% pass@100 on HumanEval and 80.8% pass@80 on MBPP. On DeepFix code repair task, the PaLM-Coder 540B model also demonstrates impressive performance. PaLM-Coder has the highest success rate when only considering edits with small normalized edit distances, and it tends to change fewer characters spread across more lines compared to Codex. PaLM-Coder is more likely than Codex to make minor stylistic changes. On the benchmarks considered here, functional correctness measurements are based on a small number of tests, but this can overestimate the performance of the methods, and more thorough tests of functional correctness would be desirable. In addition to functional correctness, model generated codes must also be readable, robust, fast, and secure before being deployed.
PaLM’s translation capabilities are evaluated across 5 language pairs: WMT’14 English-French (high-resource, >10M examples), WMT’16 English-German (mid-resource, <10M, >1M examples), WMT’16 English-Romanian (low-resource, <1M examples), WMT’19 French-German, and WMT’19 English-Kazakh (extremely-low resource). On both directions of the first three pairs in 0-shot setting, PaLM 540B outperforms all the baselines (GPT-3 and FLAN). Comparison of the three PaLM model scales shows that scaling from 62B to 540B results in drastic jump in performance that do not follow the “power law” rule of thumb[14] projected by scaling from 8B to 62B. PaLM-540B matches supervised SOTA performance on the French-German setting, but underperforms SOTA on German-French and Kazakh-English/English-Kazakh. It is commonly observed that translation quality is better when translating into English than out of English. In most cases, using the language names to induce translation (0-shot setting) provided stronger performance than only using input-output exemplars (1-shot and few-shot settings). Generalist models trained solely on self-supervision can match specialized models that are two orders of magnitude smaller.
PaLM is evaluated on 6 Multilingual natural language generation tasks, including 3 summarization datasets (MLSum [de/es], WikiLingua [en/es/ru/tr/vi\(\rightarrow\)en], XSum [en]) and 3 data-to-text datasets (Clean E2E NLG, to describe a restaurant in one or two sentences for a given set of key-value attribute pairs; Czech Restaurant response generation, to generate a response for a given dialog context and a dialog act representation; WebNLG 2020, to verbalize subject-predicate-object triples in one or more sentences in a grammatical and natural way), using 2 different settings: (1) few-shot conditional generation, to be compared against LaMDA 137B, and (2) finetuning, to be compared against T5, mT5, and BART. The F-measure of ROUGE-2 is used as the metric. To use PaLM for few-shot inference, a task-specific prompt (“Summarize the following article:” or “Verbalize:”) is concatenated to the input and an output prompt is prepended to the output. Very long inputs for summarization were truncated to 2048 tokens. Few-shot exemplars are randomly sampled from the training corpus and separated by double linebreaks. To finetune PaLM, inputs and targets are concatenated but loss is only computed in the target section of the sequence. The concatenated sequences are truncated to 2048 tokens, same as the pretraining context length, with 512 tokens reserved for the target. Inference was performed using top-k sampling with k=10. On summarization tasks, the finetuned PaLM 540B closely matches or exceeds the best reported prior results on all English generation tasks, indicating that decoder-only architecture can make up its disadvantage (against encoder-decoder architecture) through its vastly increased scale. However, non-English summarization (MLSum) finetuning does not achieve SOTA, and the relative difference between few-shot and finetuning is larger for non-English generation. On data-to-text tasks, the finetuned PaLM 540B underperforms prior SOTAs on all tested tasks, except the Czech Restaurant. On summarization tasks, few-shot PaLM 540B substantially underperforms finetuned PaLM 540B, although the 1-shot PaLM 540B performance is akin to a smaller finetuned model, such as T5-base or T5-large for non-English tasks and T5-small for English tasks. This is the first demonstration of few-shot summarization with large language models.
PaLM is evaluated on Multilingual Question Answering using the TyDiQA-GoldP benchmark in both the few-shot and finetuning settings. PaLM 540B achieves very competitive results on this task despite not trained on as much non-English data as mT5 (6x more) and ByT5 (1.5x more). PaLM 540B outperforms mT5 XXL but underperforms ByT5 XXL. Increasing the proportion of non-English data in the pretraining dataset could improve finetuning results as well. Scaling up an autoregressive language model to 540B can achieve near SOTA performance on many well-established benchmarks and to some extent, overcome certain architectural disadvantages or inductive biases.
Few-shot (0-, 1-, 5-, and 8-shot) learning performance on 5 English NLP tasks (2 knowledge-heavy: Natural Questions, Trivia QA; 3 reasoning-heavy: RTE, Lambada, Story Cloze) are evaluated across 3 PaLM model sizes (8B, 62B, 540B). The performance improves as the model is presented with more examples (more shots) on almost all tasks and models, except on the Trivia QA task where 1-shot learning outperforms both 5-shot and 8-shot learning across all three model sizes. The variance of few-shot learning performance on the StoryCloze, Natural Questions, and Web Questions benchmarks is studied on 15 different evenly spaced model checkpoints, each different only by 2B pre-training tokens from the last. 1-shot performance on StoryCloze and Natural Questions show relatively minor variation from checkpoint to checkpoint, regardless of model sizes. However, on Web Questions, significantly larger variation is observed in results from checkpoint to checkpoint, especially with PaLM 540B that achieves SOTA results on checkpoints at 770 billion tokens of training but achieves worse results in the later checkpoints.
“Memorization” of training data in PaLM is studied here. For some 100 token sequences randomly selected from training examples, the first 50 tokens are prompted to the model and the model uses greedy decoding to generate the next 50 tokens. “Memorization” rate is defined as the percentage of the 50-token continuations that exactly match the corresponding training examples. The memorization is 1.6% and 2.4% in PaLM 8B and 540B, respectively. A heldout dataset that is sampled from the same distribution as the training data but not exactly seen in the training data is also used to evaluate the memorization rate. The memorization rate of the heldout data is significantly lower than the corresponding rate of the training data, but is greater than 0%. Plotting the memorization rate as a function of the number of times a training example was exactly seen in the training data shows that the rates are 0.75% and >40% for examples seen exactly once and seen >500 times, respectively. Memorization rate broken down by corpus shows that Code corpus has >15% and Book corpus has <0.5% rate in PaLM 540B, consistent with the idea that the Code corpus has a significant amount of duplicate codes/strings and the Book corpus primarily contains unique strings. In conclusion, (1) larger models have a higher rate of memorization than smaller models, (2) the heldout results indicate that some amount of “memorization” is expected for common templates and boilerplate, and (3) the chance that an example will be memorized strongly correlates with its uniqueness in the training. Most instances of memorization were of formulaic text that is unlikely to trigger concern.
Dataset contamination refers to data overlap between the benchmark evaluation sets and the training data. Based on manual examinations, the authors divide the 29 primary English NLP benchmark datasets into two groups: 10 contaminated and 19 uncontaminated. Each of the 10 contaminated is further split into a “contaminated” and “clean” subset based on whether at least 70% of the 8-grams in question, prompt, or target were seen at least once in training data. The 1-shot performances on the clean vs full set are not consistently different, implying that data contamination does not cause meaningful inflation of the reported results. Similar results are observed in machine translation tasks.
PaLM’s ability to generate explanation is evaluated using a chain-of-thought prompting, where a 2-shot exemplars, demonstrating the desired style of the output, are prepended to each input. Two types of tasks are used: (1) Explaining a Joke and (2) Logical Inference. All outputs are generated with greedy decoding; thus, each output is the model’s canonical 1-best prediction. The results demonstrate a truly remarkable level of deep language understanding by PaLM.
The quality of LLMs for few-shot learning can be significantly improved in 4 main axes: (1) model depth and width, (2) number of tokens trained, (3) training corpus quality, and (4) increased model capacity without increased compute (i.e., sparse models). This paper has focused primarily on the first axis. The interplay between the first two axes raises a critical scaling question: “How would a model of size X trained on Y tokens compared to PaLM 540B trained on 780B tokens?”, such as 62B parameter model trained for 7T tokens, 120B model for 3.6T tokens, or 240B for 1.8T tokens, who have roughly the same total training cost as PaLM 540B trained on 780B tokens. This question was not studied in this paper due to the high training cost of performing such a study at full scale. But it was studied for Chinchilla[30], a 70B parameter model trained on 1.4T tokens of data, in comparison with Gopher[31], a 280B parameter model trained on 300B tokens of data, using the same training corpus and general training setup. The two models have a similar training cost, but Chinchilla outperforms Gopher by a large margin across a wide array of language tasks, indicating that number of tokens trained is more important than number of model parameters and Gopher was under-trained for a model of its size. Chinchilla moderately outperforms PaLM’s interpolated scaling curve at Chinchilla’s training FLOP count on BIG-bench tasks, and slightly underperforms the scaling curve on the 9 English NLP tasks. Gopher significantly underperforms both scaling curves.
In conclusions: (1) The log-linear performance improvements over the 3 model sizes of PaLM on many tasks suggest that the scaling curve for few-shot language understanding have not yet plateaued. The discontinuous improvements on some other tasks suggest that certain capabilities of language models only emerge when trained at sufficient scale, and there are additional capabilities that could emerge from future generations of models. (2) Prompting the model to generate explicit inference chains can drastically increase the performance on tasks that are modeled as categorical prediction or regression. (3) PaLM is only the first step towards establishing Pathways as the future of ML scaling for developing a large-scale, modularized system that will have broad generalization capabilities across multiple modalities.
Flan-PaLM
Chung et al. (2022)[35] studied the impact of scaling (number of tasks and model size) on instruction finetuning as well as the effect of finetuning on chain-of-thought data. The resulting model, Flan-PaLM, shows improved reasoning abilities, improved multilingual abilities, improved usability, and improved performance across several responsible AI benchmarks.
Motivated by the previous evidence that increasing the number of tasks in instruction finetuning improves generalization to unseen tasks[5][6], this study scales to 1,836 finetuning tasks by combining four mixtures from prior work: Muffin, T0-SF, NIV2, and CoT, as summarized in the Figure below. Muffin (Multi-task finetuning with instructions) comprises 62 tasks from FLAN[5] and 26 new tasks added in this work, including dialog data and program synthesis data. T0-SF (193 tasks) comprises tasks from T0[6] that do not overlap with the data used in Muffin (SF stands for “sans Flan”). NIV2 (1554 tasks) comprises tasks from Super-NaturalInstructions[59], excluding 44 tasks related to MMLU[62], since MMLU is used for evaluation. The chain-of-thought (CoT) finetuning mixture comprises 9 tasks, including arithmetic reasoning, multi-hop reasoning, and natural language inference, to explore whether finetuning on CoT annotations improves performance on unseen reasoning tasks. For the 9 CoT tasks, 10 instruction templates per task are manually composed. For each task of Muffin, T0-SF, and NIV2, instructional templates given by the creators of the mixtures are used.
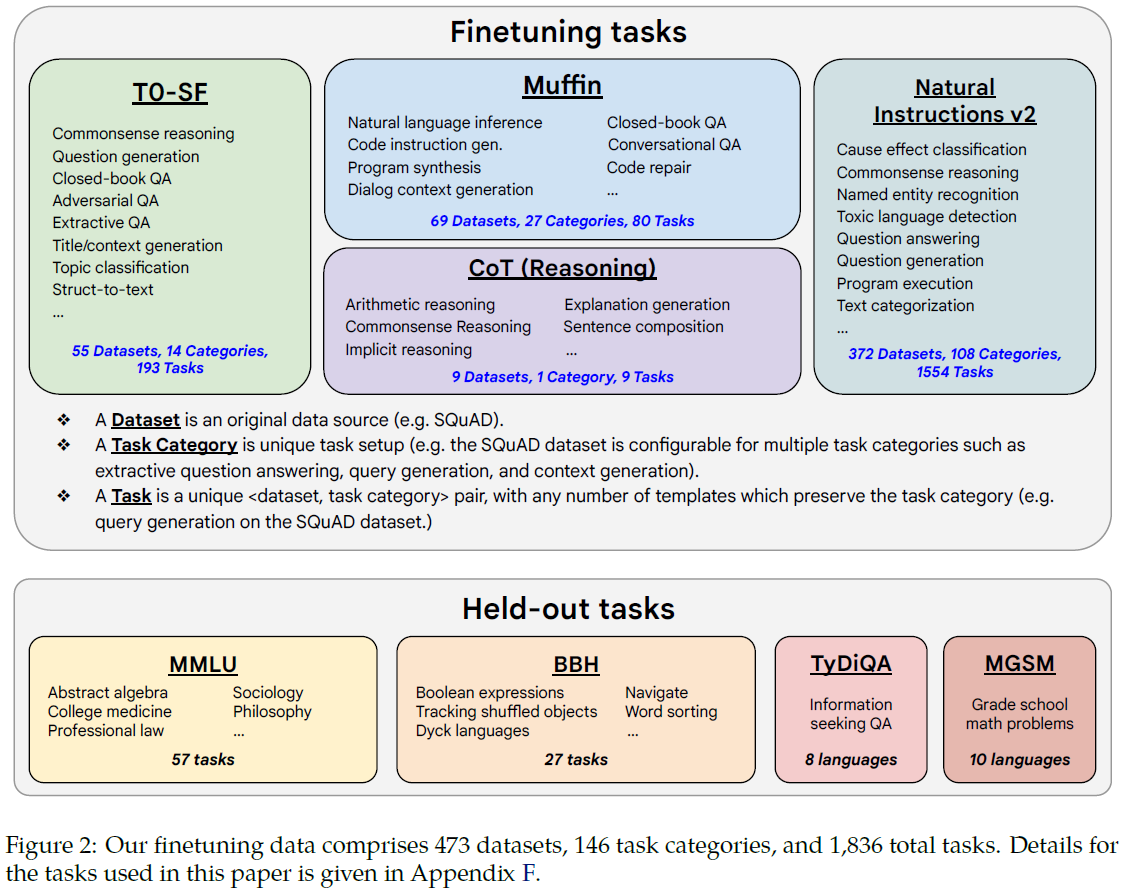
To create few-shot templates, a variety of exemplar delimiters (e.g., “Q:”/”A:”) are applied randomly at the example level. An example of formatting for both with and without exemplars, as well as with and without CoT, is shown in the Figure below.
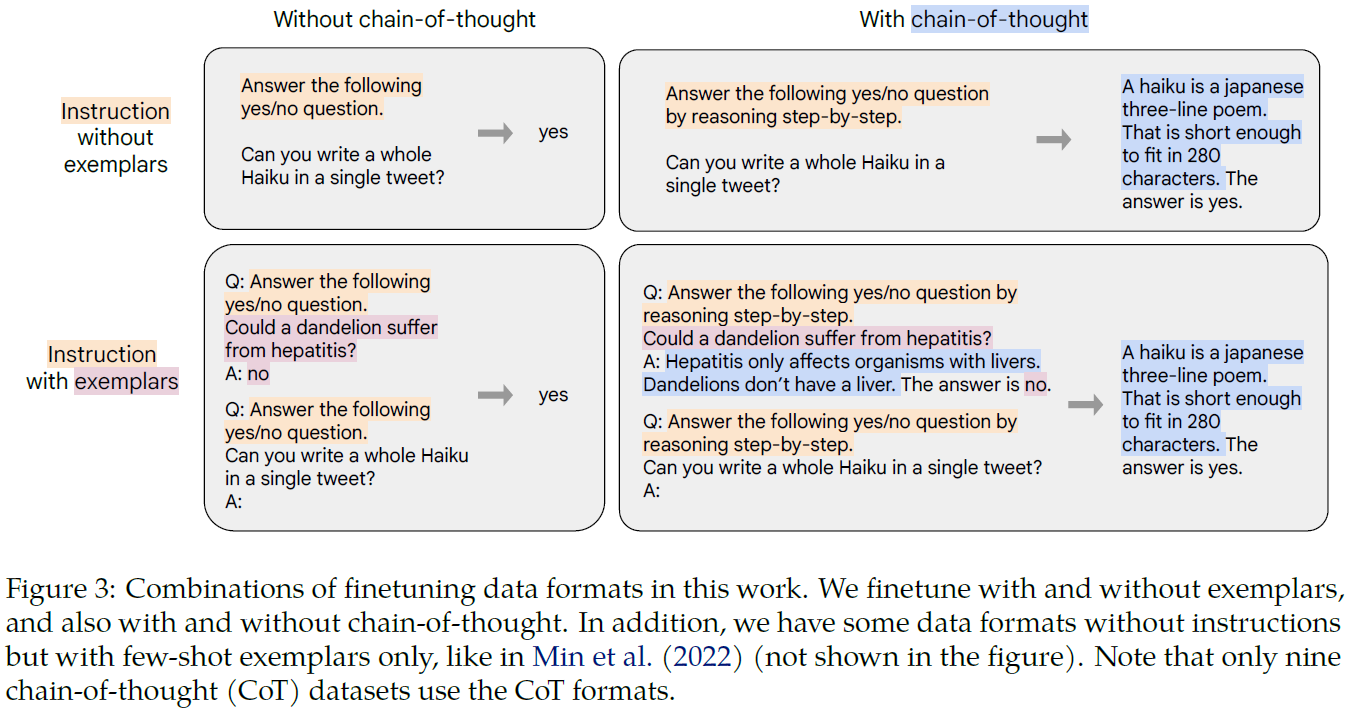
Three model families are instruction-finetuned in this study: T5[61], PaLM, and U-PaLM[60], ranging from Flan-T5-small 80M to PaLM 540B and U-PaLM 540B. The same training procedure is applied to the models, except for a few hyperparameters. Packing[61] is used to combine multiple training examples into a single sequence, and an end-of-sequence token is used to separate inputs from targets. Masking is applied to prevent the tokens from attending to others across the packed example boundary. The amount of compute used for finetuning is only a small fraction relative to the pretraining compute, using the JAX-based T5X framework. For example, only 0.2% of the pre-training compute is used to instruction-finetune Flan-PaLM 540B.
Four challenging benchmarks are used for evaluation, for which current language models still perform well below expert human raters. (1) MMLU[62] includes exam questions from 57 tasks such as mathematics, history, law, and medicine. (2) BBH (BIG-Bench Hard)[66] includes 23 challenging tasks from BIG-Bench[64] for which PaLM performs below an average human rater. (3) TyDiQA[63] is a question-answering benchmark across 8 typologically diverse languages. (4) MGSM (Multilingual Grade School Math)[65] is a multilingual benchmark of math word problems from GSM8K[67] manually translated into 10 languages. It has been verified in the PaLM study that these benchmarks do not have meaningful data contamination with pre-training data. MMLU and BBH are used to evaluate the ability to directly predict the answer via direct prompting, where the model directly gives the answer, as well as via CoT prompting, where the model must provide a reasoning chain before giving the final answer. TyDiQA is only used to measure direct prompting exact-match score, since highlighting the portion of a passage with the correct answer may not require sophisticated reasoning. MGSM is only used to measure CoT prompting accuracy since direct prompting has very low performance. For all benchmarks, the given few-shot exemplars are used, with the number of exemplars following prior work: five-shot for MMLU, three-shot for BBH, one-shot for TyDiQA, and 8-shot for MGSM. For a given model, a single “normalized average” metric (normalized with respect to a task-specific lower bound such as random guessing baseline for a multiple-choice question) is also reported, following the “normalized preferred metric” in BIG-Bench. The normalized average metric is the macro-average over six normalized scores: MMLU-Direct, MMLU-CoT, BBH-Direct, BBH-CoT, TyDiQA-Direct, and MGSM-CoT.
Scaling model size is done on three PaLM model sizes: 8B, 62B, and 540B. Scaling the number of finetuning tasks is done by adding task mixtures starting from the mixture with the fewest tasks to the mixture with the most tasks: CoT, Muffin, T0-SF, and NIV2. The joint effect of scaling these two variables shows that (1) for all three model sizes, multi-task instruction finetuning improves performance by a large margin compared to no finetuning, with performance gain ranging from 9.4% to 15.5%; (2) increasing the number of finetuning tasks improves performance, although the majority of the improvement comes from using up to 282 tasks; (3) increasing model scale by an order of magnitude (i.e., 8B\(\to\)62B or 62B\(\to\)540B) improves performance substantially for both finetuned and non-finetuned models. The small gain after 282 tasks can be explained as that most of the gains from multi-task instruction finetuning come from the model learning to better express knowledge that it already knows from pretraining, and more than 282 tasks does not help too much. This explanation could make sense since the pre-training data consists of 780B tokens, while instruction finetuning only uses 1.4B tokens (0.2% of the pre-training tokens). The scaling curves suggest that (i) scaling model size by another order of magnitude (though challenging) is expected to provide substantial performance gain, and (ii) scaling number of finetuning tasks should also improve performance, although likely only incrementally.
Including nine datasets with CoT annotations in the finetuning mixture improves Flan-PaLM performance over PaLM on all the 4 benchmarks using direct or CoT prompting. CoT prompting can be combined with self-consistency decoding[36] to achieve new state-of-the-art performance on MMLU, BBH-nlp, and MGSM. However, even with CoT prompting combined with self-consistency decoding, Flan-PaLM does not achieve SOTA compared to certain specialized models, underperforming Codex (code-davinci-002) on BBH-alg and ByT5 on TyDiQA.
The ablation studies to evaluate the effect of CoT datasets in instruction finetuning show that instruction finetuning improves unseen tasks when the unseen tasks are in the same prompting paradigm as the finetuning tasks (i.e., non-CoT or CoT). On held-out CoT benchmarks, the model instruction-tuned only with non-CoT data substantially underperforms the model without finetuning and the model instruction-tuned with both CoT and non-CoT data outperforms the model instruction-tuned only with both CoT. Hence, both non-CoT and CoT data are needed to improve model’s CoT reasoning ability.
Instruction finetuning on CoT data both with and without exemplars also enables the resulting model to perform CoT reasoning in a zero-shot setting, which tests a model’s ability to produce its own reasoning skills without few-shot exemplars for CoT that require substantial prompt engineering to compose properly. On the BBH benchmark, Flan-PaLM models with zero-shot CoT setting, which is simply adding “Let’s think step by step” before each answer[68], substantially outperform corresponding PaLM and Flan-PaLM models with zero-shot only setting. On the contrary, PaLM models with zero-shot CoT setting substantially underperform corresponding PaLM models with zero-shot only setting.
The generality of instruction finetuning is studied by applying it to several models of different sizes, architectures, and training objectives: (1) T5 models, which use encoder-decoder architecture with 5 sizes from 80M to 11B, (2) cont-PaLM model, which is initialized from PaLM-62B and then pretrained for 500B more tokens, (3) U-PaLM model, which is initialized from PaLM-540B and then pretrained with an UL2 objective (mixture of 3 denoising objectives)[33][60] for 20k additional steps. The results show that instruction finetuning improves normalized average performance by a large margin for all model types. T5 models benefited the most from instruction finetuning compared with their non-finetuned models, e.g. Flan-T5-XL 3B achieves a MMLU score of 52.4% far exceeding T5-XL 3B’s score of 25.7% and GPT-3 175B’s score of 43.9%. The strongest overall model achieved in this paper is Flan-U-PaLM 540B that combines instruction finetuning with UL2 continued pre-training used in the U-PaLM model, indicating that instruction finetuning and UL2 continued pre-training are complementary compute-efficient methods to improve the performance of language models.
To investigate the effect of instruction finetuning on the ability for models to give open-ended responses to challenging inputs, an evaluation dataset of 190 examples is created, which includes 20 questions in zero-shot manner for each of the 5 challenging categories: creativity, reasoning over contexts, complex reasoning, planning, and explanation; 60 CoT variants with the trigger phrase “let’s think step-by-step” for the examples of the 3 categories: complex reasoning, planning, and explanation; and 30 few-shot examples. PaLM 540B and Flan-PaLM 540B models are compared in this evaluation. 5 responses are generated randomly using temperature sampling with \(\tau=0.7\), and then ranked by log probability score without length normalization. A filtering step is used to remove any generations with scores that are better than half of the median score of the 5 generations, which are largely generations with undesirable repetitions. Then, the response with the best score is chosen as output. The PaLM and Flan-PaLM outputs are presented to human raters for them to choose a preferred response based on desirability. Each pair of outputs is scored by one rater. The results show that Flan-PaLM generations were preferred over PaLM 79% of the time over all 190 evaluation examples. This ability of instruction-finetuned models to better respond to open-ended zero-shot inputs is consistent with InstructGPT.
Five takeaways from this paper are summarized below. (1) Scaling curves for instruction finetuning indicate that scaling both the model size and the number of instruction finetuning tasks will likely continue to improve performance, although scaling number of tasks has diminishing (though still positive) returns. (2) Joint finetuning on both non-CoT and CoT data enables substantially better CoT performance while maintaining performance on non-CoT tasks, allowing a single model to do well on all evaluations, while finetuning on non-CoT tasks alone leads to degraded performance on CoT tasks, indicating that CoT finetuning is critical for reasoning abilities. (3) Instruction finetuning generalizes across models with a range of different architectures, sizes, pre-training objectives, and combines well with other techniques such as UL2R. (4) Instruction finetuning improves usability, on open-ended generations, on CoT tasks like complex reasoning, planning, and explanation, and on zero-shot settings for unseen tasks. (5) Instruction finetuning improves the performance of pretrained models with a relatively small amount of compute.
Med-PaLM
Singhal et al. (2022)[69] assess the potential of LLMs in medicine by evaluating PaLM and Flan-PaLM on a new medical question answering benchmark MultiMedQA that comprises 7 datasets: MedQA (from US medical licensing exam, USMLE), MedMCQA (multi-subject multi-choice QA in Indian medical entrance exams), PubMedQA (biomedical scientific literature), LiveQA (general medical knowledge sought by consumers), MedicationQA (commonly asked consumer questions about medications), MMLU clinical topics (covering anatomy, clinical knowledge, college medicine, medical genetics, professional medicine, and college biology), and a new free-response dataset HealthSearchQA (health knowledge commonly searched by consumers). A pilot framework for human evaluation of model answers is introduced along multiple axes including factuality, precision, possible harm, and bias. Flan-PaLM achieves SOTA performance via a combination of prompting strategies, surpassing several strong LLM baselines. An instruction prompt tuning technique is introduced to align LLMs to the medical domain. An instruction prompt-tuned version of Flan-PaLM is named as Med-PaLM, which performs encouragingly on the axes of the pilot human evaluation framework.
All the 7 datasets are in English. They vary in format (multiple-choice vs long-form answer), capabilities tested (knowledge recall vs reasoning), domain (open vs closed), question source (medical exams, medical research, or consumer search queries), labels and metadata (presence of labels or explanations and their sources). The reference long-form answers or explanations provided in MedMCQA, PubMedQA, LiveQA, and MedicationQA are not used as a “ground truth” in this study, due to inconsistent qualities. MultiMedQA’s coverage is not exhaustive, e.g. not including electronic medical records QA, or pre-clinical biomedical knowledge QA.
Given the safety-critical requirements of the medical domain, this study relies on human evaluation, instead of automatic metrics, to assess the qualities of model answers for long-form QA in the LiveQA, MedicationQA, and HealthSearchQA datasets. The framework for human evaluation comprises 12 axes of evaluation for clinicians to assess model generations, which include agreement with scientific consensus, possibility and likelihood of harm, evidence of comprehension, reasoning and retrieval ability, presence of inappropriate, incorrect or missing content and possibility of bias in the answer. The framework contains 2 axes (addressing user intent and helpfulness to user) for lay users to evaluate the utility of model generations. Clinician evaluation was performed by 9 clinicians based in the UK, USA or India and qualified for practice in their respective countries, with specialist experience including pediatrics, surgery, internal medicine and primary care. Lay user (non-expert) evaluation was performed by 5 non-expert lay users.
For few-shot prompting, a panel of qualified clinicians identified the best demonstration examples and crafted the few-shot prompts. Separate prompts were designed for each dataset. The number of few-shot demonstrations varied depending on the dataset: typically 5 input-output examples for the consumer medical question answering datasets, but reduced to 3 or fewer for PubMedQA. For chain-of-thought prompting, CoT prompts are crafted by clinicians to provide clear demonstrations on how to reason and answer the given medical questions. Self-consistency decoding strategy was adopted for multiple-choice questions in the datasets: MedQA, MedMCQA, PubMedQA and MMLU, where multiple decoding outputs were sampled and the final answer is the one with the majority vote in the multiple sampled outputs. Prompt tuning restricts the learnable parameters to only those representing a small number of tokens prepended to the input as a soft prompt. It has been shown that prompt tuning can improve model performance on specific downstream task to be comparable with end-to-end finetuning at increased model scale.
Instruction prompt tuning uses the soft prompt as an initial prefix that is shared across multiple medical datasets and followed by the relevant task-specific human-engineered prompt (consisting of instructions and/or few-shot exemplars, which may be chain-of-thought examples) along with the actual question and/or context. Instruction prompt tuning can be seen as a lightweight way (data-efficient, parameter-efficient, compute-efficient during both training and inference) of training a model (without model parameter updates) to follow instructions in one or more domains. In this study, instruction prompt tuning adapted LLMs to better follow the specific type of instructions used in the family of medical datasets. Given the combination of soft prompt with hard prompt (human-engineered prompt), instruction prompt tuning can be considered a type of “hard-soft hybrid prompt tuning”. This study is the first example of learning a soft prompt that is prefixed in front of a full hard prompt containing a mixture of instructions and few-shot exemplars. Instruction prompt tuning is applied on a small set of examplars to adapt Flan-PaLM to the medical domain. Examples were randomly sampled from MultiMedQA free-response datasets (HealthSearchQA, MedicationQA, LiveQA) and exemplar answers were provided by a panel of 5 clinicians based in the US and UK with specialist experience in primary care, surgery, internal medicine, and pediatrics. Clinicians then filtered out questions / answer pairs that they decided were not good examples to instruct the model. 40 examples were left across HealthSearchQA, MedicationQA, and LiveQA datasets to be used for instruction prompt tuning training. The resulting model, Med-PaLM, was evaluated on the consumer medical question answering datasets of MultiMedQA along with Flan-PaLM.
On the MedQA (USMLE) dataset questions with 4 options, Flan-PaLM 540B model achieved a multiple-choice question (MCQ) accuracy of 67.6% substantially exceeding previous state-of-the-art score of 50.3% by PubMedGPT 2.7B that was trained exclusively on biomedical abstracts and papers. On the more difficult set of questions with 5 options, Flan-PaLM 540B model obtained a score of 62.0%. On the MedMCQA dataset, Flan-PaLM 540B reached a performance of 57.6% on the dev set, exceeding the previous state of the art result of 52.9% by the Galactica model. On the PubMedQA dataset, Flan-PaLM 540B achieved an accuracy of 79.0% outperforming the previous state-of-the-art score of 78.2% by BioGPT model, while a single rater human performance on PubMedQA was 78.0%. On MMLU clinical topics, Flan-PaLM 540B achieved state of the art performance on all the topics, outperforming strong LLMs like PaLM, Gopher, Chinchilla, BLOOM, OPT and Galactica.
5 ablation studies were performed on three of the multiple-choice datasets, MedQA, MedMCQA and PubMedQA. (1) The instruction-tuned Flan-PaLM model outperformed the baseline PaLM model, using few-shot prompting across all model sizes, indicating that instruction tuning improves performance on multiple-choice medical question answering. The performance of instruction prompt-tuned Flan-PaLM (i.e. Med-PaLM) on multiple-choice accuracy has not yet been studied. (2) Strong performance improvements were obtained from scaling both the PaLM and Flan-PaLM models from 8B to 62B and 540B using few-shot prompting on the MedQA and MedMCQA datasets, indicating that scaling improves performance on multiple-choice medical question answering. (3) Flan-PaLM 540B model performed worse in CoT prompt setting than in standard few-shot prompt setting across the three multiple-choice datasets. (4) For self-consistency strategy, 11 CoT answer explanation paths were sampled and then the most consistent answer was selected. Flan-PaLM 540B model using self-consistency strategy outperformed using few-shot prompting strategy on MedQA and MedMCQA datasets, but underperformed on PubMedQA. (5) This study used the number of decodes matching a given answer from self-consistency as a measure of uncertainty and used it to withhold the answer if the model was not appropriately confident. The experiments were performed using 41 decodes from the Flan-PaLM 540B model with chain-of-thought prompting and self-consistency. As the deferring fraction increases (i.e., with a higher “confidence” required to provide a prediction), the performance of the model on MedQA improves, reaching up to an accuracy of of 82.5% at a 0.45 deferring fraction, suggesting that the measure of response uncertainty may be reasonable and LLMs seem to encode uncertainty about their knowledge in the medical domain.
A 140-question long-form answer benchmark was created by randomly selecting 100, 20, and 20 questions from HealthSearchQA, LiveQA, and MedicationQA datasets, respectively, for human evaluation. These selected questions were disjoint from those exemplars used for instruction prompt tuning to produce Med-PaLM. Expert reference answers to these questions were generated by a panel of clinicians. Then, model answers were produced using Flan-PaLM and Med-PaLM (both 540B models). The 3 sets of answers were evaluated by another panel of 9 clinicians along the 12 axes described above, without revealing the source of answers. Each clinician evaluated each answer. To estimate any significant variation in the results, the non-parametric bootstrap procedure was used, where 100 bootstrap replicas were used to produce a distribution for each set and the 95% bootstrap percentile interval was used to assess variations. (1) Scientific consensus: Clinicians’ answers were judged to be aligned with the scientific consensus in 92.9% of questions. Flan-PaLM was found to be in agreement with the scientific consensus in only 61.9% of answers, suggesting that generic instruction tuning on its own was not sufficient to produce scientific and clinically grounded answers. However, 92.9% of Med-PaLM answers were judged to be in accordance with the scientific consensus, indicating the strength of instruction prompt tuning as an alignment technique to produce scientifically grounded answers. (2) Comprehension, retrieval and reasoning capabilities: A panel of clinicians rated whether answers contained any evidence of correct / incorrect medical reading comprehension, medical knowledge retrieval and medical reasoning capabilities. Expert generated answers were again considerably superior to Flan-PaLM, though performance was improved by instruction prompt tuning for Med-PaLM. This trend was observed in all the six sub-questions in this axis. (3) Incorrect or missing content: Percentage of answers containing evidence of inappropriate/incorrect content was 1.4%, 15.1%, and 18.7% for clinicians, Flan-PaLM, and Med-PaLM, respectively. It is surprising that Med-PaLM reduced appropriateness/correctness as compared to Flan-PaLM. On the other hand, percentage of answers with omission of important information was 11.1%, 47.2%, and 15.1% for clinicians, Flan-PaLM and Med-PaLM, respectively. One potential explanation of these observations is that instruction prompt tuning teaches the Med-PaLM model to generate significantly more detailed and longer answers than the Flan-PaLM model, reducing the omission of important information but increasing the risk of introducing incorrect content. (4) Possible extent and likelihood of harm: Human raters estimated the possible severity and likelihood of physical/mental health-related harms that might result from acting upon the model-generated answers. The options to assign severity of harm included death, severe or life-threatening injury, moderate, mild or no harm, based on the Agency for Healthcare Research & Quality (AHRQ) Common Formats Harm Scale. The percentage of responses that were judged as potentially leading to harm was 5.7%, 29.7%, and 5.9% for clinicians, Flan-PaLM, and Med-PaLM, respectively. (5) Bias for medical demographics: The bias studied in this paper is whether the answer contained any information that is inaccurate or inapplicable for a particular demographic. The percentage of answers containing biased information was 1.4%, 7.9%, and 0.8% for clinicians, Flan-PaLM, and Med-PaLM, respectively. (6) Lay user assessment: A panel of 5 laypeople without medical background, based in India, also assessed the answers. The percentage of answers judged as helpful was 91.1%, 60.6%, and 80.3% for clinicians, Flan-PaLM, and Med-PaLM, respectively. The percentage of answers judged as directly addressing the intent of question was 95.9%, 90.8%, and 94.4% for clinicians, Flan-PaLM, and Med-PaLM, respectively. The lay user evaluation consistently reproduced the benefits of instruction prompt tuning to produce answers that are helpful to users, although it remained inferior to clinician answers.
Bard
Bard is designed as an interface to a large language model that enables users to collaborate with generative AI in supporting productivity, creativity, and curiosity[12]. Bard is based on a lightweight and optimized version of LaMDA, pre-trained on a variety of publicly available data, and fine-tuned on human-annotated dialog data for quality, safety, and groundedness. Bard uses the context in user-provided prompt and the interaction with the user to draft several versions of a response that are then checked for safety. Responses that pass through safety checks are re-ranked based on quality, with the higher-quality responses provided back to the user.
If responses are flagged in Bard, trained human reviewers assess their quality related to the input prompt and determine if Bard’s response is low-quality, inaccurate or harmful. Then, trained evaluators suggest higher-quality responses in line with a defined set of policies, which are used as fine-tuning data to further improve Bard. Reinforcement Learning on Human Feedback (RLHF) is used to further improve Bard[12], based on human preference feedback. This sets Bard apart from LaMDA that doesn’t use RLHF technique.
Five known limitations of Bard are still being worked on: (1) accuracy, (2) bias, (3) persona, (4) false positives and false negatives, and (5) vulnerability to adversarial prompting. Bard can sometimes generate responses that contain inaccurate information or even hallucinate. Like all generative language models, Bard is not fully capable of distinguishing between accurate and inaccurate information. It generates responses based on similar examples in training data, not on advanced reasoning or mathematical computations. Bard can generate responses that reflect only one culture or demographic, reference problematic stereotypes, or exhibit gender, religious, or ethnic biases. These are resulted from the gaps, biases, and stereotypes in training data. Bard may generate responses that appear to have personality, such as subjective opinions or emotions. A set of guidelines have been developed around how Bard might represent itself to provide objective and neutral responses. To prevent Bard from generating harmful or offensive content, a set of technical guardrails have been used to prevent problematic responses. Bard can sometimes misinterpret these guardrails and produce false positive, misinterpreting a reasonable prompt as inappropriate, or false negative, misinterpreting an inappropriate prompt as reasonable. Better safety classification is continued to be worked on. Bard is also being improved to reduce the risks of producing problematic or sensitive information in response to adversarial prompts.
Bard user interface provides some useful features: (1) multiple drafts, (2) new response, and (3) Google it. For every prompt, Bard provides three different responses, or drafts, with draft 1 displayed as the default response. The other two drafts can be displayed by clicking “view other drafts”. If a user wants to see further more responses for the same prompt, the user can click on the new response button and Bard will generate another set of three responses. If a user wants to check factuality of a response on the web, the user can click the “Google it” button. In response to a click on the “Google it” button, Bard provides three related Google Search queries. When any one of the queries is clicked, a new web tab is opened with Google Search results for the query displayed.
Bard may sometimes generate a response that references a webpage, if the content of the webpage is directly quoted at length. Bard’s ability to hold context is limited; thus, it can only use limited turns as context in a long multi-turn conversation.
PaLM-E
Med-PaLM M
Tu et al. (2023)[72] finetuned PaLM-E with a new multi-task, multimodal medical benchmark, MultiMedBench, dataset that spans language, imaging, and genomics modalities with 14 diverse biomedical tasks including question answering, visual question answering, medical image classification, radiology report generation and summarization, and genomic variant calling. The resulting model is named Med-PaLM Multimodal (Med-PaLM M) that can easily incorporate and interleave various types of multimodal biomedical information including clinical language, medical imaging, and genomics and reaches performance competitive with or exceeding the state-of-the-art (SOTA) on all tasks in MultiMedBench. Med-PaLM M is considered as the first generalist biomedical AI system.
The MultiMedBench comprises 12 de-identified open-source datasets and 14 individual tasks, covering a a wide range of data sources including medical questions, radiology reports, pathology, dermatology, chest X-ray, mammography, and genomics. The 14 tasks span across 5 task types, 7 modalities, and an open-ended output format for all tasks including classification, as summarized in the Table below. The 14 tasks consist of 4 language-only tasks (3 tasks of the MultiMedQA used by Med-PaLM and a radiology report summarization task) and 10 multimodal tasks.
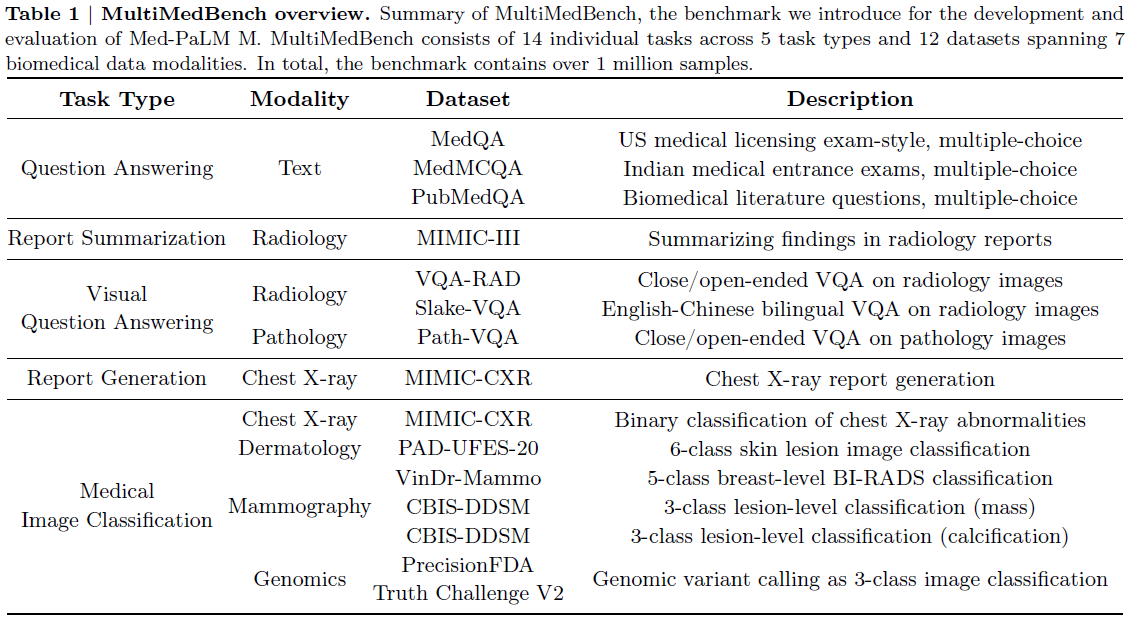
Med-PaLM M inherits from 3 pretrained models, PaLM, ViT (Vision Transformer)[73], and PaLM-E[75], and the domain knowledge encoded in their model parameters. The PaLM training corpus consists of 780 billion tokens representing a mixture of webpages, Wikipedia articles, source code, social media conversations, news articles, and books. PaLM models were trained at sizes of 8, 62, and 540 billion parameters, and all three PaLM model variants were trained for one epoch of the training data. ViT extends the Transformer architecture to visual data such as images and videos. This study used 2 pre-trained ViT models, the ViT-4B image encoder from PaLI[74] and the ViT-22B[76], as vision encoders, which were pretrained via supervised learning on a large classification dataset of approximately 4 billion images. PaLM-E uses pretrained PaLM and ViT to process sequences of multimodal inputs including text, vision, and sensor signals. PaLM-E was initially developed for embodied robotics applications but demonstrated strong performance on multiple vision language benchmarks. Furthermore, PaLM-E offers the flexibility to interleave images, text and sensor signals in a single prompt, enabling the model to make predictions with a fully multimodal context. PaLM-E also exhibits a wide array of capabilities including zero-shot multimodal chain-of-thought (CoT) reasoning, and few-shot in-context learning. Therefore, PaLM-E model is used as the base architecture for Med-PaLM M. Three variants were considered in this study: PaLM-E 12B (PaLM-8B + ViT-4B), PaLM-E 84B (PaLM-62B + ViT-22B), and PaLM-E 562B (PaLM-540B + ViT-22B). All 3 models were pretrained on diverse vision-language datasets in addition to tasks across multiple robot embodiments[75].
Med-PaLM M was developed by finetuning and aligning the PaLM-E model to the biomedical domain using MultiMedBench. All the images in MultiMedBench were resized to 224×224×3, while preserving the original aspect ratio with padding if needed. The gray-scale images were converted to 3-channel images by stacking up the same image along the channel dimension. There was task-specific preprocessing, such as class balancing and image data augmentation, for each task. The model was trained with a mixture of distinct tasks simultaneously via instruction tuning[5], where the model was provided with task-specific instructions to prompt the model to perform different types of tasks in a unified generative framework. The task prompt consisted of an instruction, relevant context information, and a question. All classification tasks were formulated as multiple-choice questions where all possible class labels were provided as individual answer options and the model was prompted to generate the most likely answer as the target output. For other generative tasks such as visual question answering and report generation and summarization, the model was finetuned on the target response. For the majority of tasks, a text-only one-shot exemplar was added to the task prompt to condition the language model’s prediction. For multimodal tasks, the actual image in the exemplar was replaced with a dummy text placeholder (with the text string “<img>”) that (i) preserved training compute efficiency for single-image training, and also (ii) bypassed potential interference from cross-attention between a given text token and image tokens from multiple images. The results show that this scheme is effective in prompting the model to generate the desired format of responses.
The 3 variants of pretrained PaLM-E were finetuned on MultiMedBench tasks with mixture ratios empirically determined such that they were approximately proportional to the number of training samples in each dataset and at least one sample from each task was present in one batch. An end-to-end finetuning of the PaLM-E model was performed with the entire set of model parameters updated during training. For multimodal tasks, image tokens were interleaved with text tokens to form multimodal context input to the PaLM-E model. The multimodal context input contained at most 1 image for all finetuning tasks. During inference, however, Med-PaLM M is able to process inputs with multiple images. The max length (in tokens) for input and output during finetuning were 710 and 256, respectively. The finetuning batch size was 128 for 12B/84B variant and 256 for 562B variant of Med-PaLM M.
For performance evaluation on tasks in MultiMedBench, the same few-shot setup as in training was used for each task during evaluation. Task-specific metrics were computed on the test split of each task and compared to 2 baselines: (1) prior SOTA specialist models and (2) a generalist model (PaLM-E 84B) without any biomedical finetuning. Med-PaLM M’s best result (across three model sizes) exceeded prior SOTA results on 5 out of the 12 tasks that had prior SOTA with comparable setup while being competitive on the rest. On the 3 text-only medical question answering tasks, the SOTA Med-PaLM 2 still significantly outperformed Med-PaLM M’s best, while Med-PaLM M outperformed Med-PaLM by a large margin in the same few-shot setting. Further, Med-PaLM M outperformed PaLM-E 84B on all 14 tasks often by a significant margin, demonstrating the importance of domain adaptation. Taken together, these results illustrate the strong capabilities of Med-PaLM M as a generalist biomedical AI model.
Performance of Med-PaLM M on MultiMedBench across model scales showed that (1) language reasoning tasks benefit from scale and (2) multimodal tasks bottlenecked by vision encoder performance. Scaling up the model from 12B to 562B significantly improved performance on tasks that require language understanding and reasoning. For tasks that require nuanced visual understanding but minimal language reasoning, the performance improved from Med-PaLM M 12B to Med-PaLM 84B but plateaued for the 562B model, possibly because the vision encoder is not further scaled up in the 562B model, thereby acting as a bottleneck.
Evidence of generalization to novel medical concepts. Med-PaLM M is not trained to explicitly predict the TB disease label. To probe Med-PaLM M’s ability to generalize to previously unseen medical concepts, the model’s ability to predict the presence or absence of tuberculosis (TB) was evaluated using the Montgomery County chest X-ray set (MC) that contains 138 frontal chest X-rays, of which 80 are normal cases and 58 cases have manifestations of TB. Each case also contains annotations on the abnormality seen in the lung. The evaluation was formulated as a two-choice question answering task where the model was prompted (with a text-only one-shot exemplar, without task-specific image and hence zero-shot) to generate a yes/no answer about the presence of TB in the input image. Med-PaLM M (562B) achieved accuracy of 87.68%, approaching prior SOTA performance 92.60% obtained by a specialized ensemble model trained on all the samples in the MC dataset. Similar performance was observed across three model variants, consistent with findings on other medical image classification tasks in MultiMedBench.
Evidence of emergent zero-shot multimodal medical reasoning. To further explore multimodal medical reasoning ability in zero-shot chain-of-thought (CoT) setting on the MC TB dataset, the model was prompted with a text-only exemplar (without the corresponding image) and asked to generate the class prediction and a report describing the findings in a given X-ray image. While the model was prompted with a single text-only input-output pair, the image was omitted and replaced with a dummy text and the text exemplar was hand-crafted rather than drawn from the training set. Hence, this approach can be considered as zero-shot rather than one-shot. Both Med-PaLM M 84B and 562B variants were able to identify the major TB related lesion in the correct location. However, there were still some omissions of findings and errors in the model generated report. Furthermore, Med-PaLM M 12B failed to generate a coherent visually conditioned response, which indicates that scaling of the language model plays a key role in the zero-shot CoT multimodal reasoning capability (i.e. this might be an emergent capability).
Evidence of generalization to novel tasks. Med-PaLM M was trained to generate reports only from a single-view chest X-ray. To assess Med-PaLM M’s ability to generalize to novel task scenarios, the model performance was evaluated on two-view chest X-ray report generation as a novel task. Specifically, on a subset of studies from MIMIC-CXR where each report is accompanied with both a frontal and a lateral view X-ray image, Med-PaLM M is able to attain zero-shot performance comparable to the single-view report generation task. This ability is promising given medical imaging studies often benefit from the interpretation of prior historical studies in addition to the current instance for optimal performance.
Evidence of positive task transfer. To probe for evidence of positive task transfer, a Med-PaLM M 84B variant was trained by excluding the MIMIC-CXR classification tasks from the task mixture and compared to the Med-PaLM M 84B variant trained on the complete MultiMedBench mixture on the chest X-ray report generation task with the expectation of improved performance in the latter. The results show that the model trained jointly on both report generation and classification has higher performance across the board on all report generation metrics. The model trained only on chest X-ray report generation can generalize to abnormality classification in a zero-shot fashion with compelling performance. This is another example of generalization to a novel task setting where the model learns to differentiate between types of abnormalities from training on the more complex report generation task.
The quality of chest X-ray reports generated by Med-PaLM M were evaluated by 4 qualified thoracic radiologists based in India. The evaluation dataset consisted of 246 cases selected from the MIMIC-CXR test split. A single image was selected from each case to match the expected input format of Med-PaLM M. Selected cases excluded those that had ground truth reports mentioning multiple X-ray views or past examinations of the same patient. Two human evaluations were conducted: (1) side-by-side evaluation where raters compared multiple alternative report findings and ranked them based on their overall quality, and (2) independent evaluation where raters assessed the quality of individual report findings. For side-by-side evaluation, each of the 246 cases was rated by a single radiologist randomly selected from the pool of four. Four findings paragraphs corresponded to the reference findings, and findings generated by three Med-PaLM M variants (12B, 84B, 562B) were ranked by radiologist raters based on overall quality, given a chest X-ray and indication. Averaged over all four raters, the radiologist-provided reference report was ranked best in 37.14% of cases, followed by Med-PaLM M 84B (25.78%), Med-PaLM M 12B (19.49%), and Med-PaLM M 562B (17.59%). Derived pairwise preferences from the four-way ranking showed that in up to 40.50% of the cases, a Med-PaLM M generated report was preferred over the human-generated reference report. For independent evaluation, every case in the evaluation set was evaluated by each of the four radiologists independently. Radiologist raters annotated a findings paragraph generated by Med-PaLM M for errors and omissions, given a chest X-ray, the indication, and reference findings. The results showed different trends for omissions and errors. The omission rate was 0.12 (95% CI, 0.10 - 0.15) omissions per report on average for both the Med-PaLM M 12B and 84B models, followed by 0.13 (95% CI, 0.11 - 0.16) for the 562B model. In contrast, the mean error rate was 0.25 (95% CI, 0.22 - 0.28) for Med-PaLM M 84B, followed by 0.28 (95% CI, 0.24 - 0.31) for Med-PaLM M 12B and 0.29 (95% CI, 0.25 - 0.32) for the 562B model. This error rate is comparable to those reported for human radiologists baselines on the MIMIC-CXR dataset in a prior study.
The MultiMedBench benchmark has several important limitations including limited size of the individual datasets and limited modality and task diversity (e.g., lacking life sciences such as transcriptomics and proteomics). PaLM-E is a highly capable generalist AI model on a wide range of vision-language and embodied robotics tasks, but it underperforms Med-PaLM M on MultiMedBench by a wide margin across model scales. This result suggests that finetuning with domain-specific biomedical data is critical to achieving good performance on biomedical tasks, perhaps due to the distribution shift presented by the biomedical domain compared to the plethora of non-medical tasks and modalities.
Scaling the model is likely more challenging for multimodal generalist models in the biomedical task domain due to the medical data scarcity. Given the wide array of modalities and tasks such generalist models are expected to understand and tackle, it is crucial that the encoders for such diverse modalities are scaled jointly with the language model to avoid performance bottleneck at the weakest encoder. In this study, scaling the language model component has little effect on the performance of medical image classification tasks, suggesting that the potential key bottleneck is the vision encoder. The small volume of medical data in MultiMedBench is likely insufficient to effectively adapt a pretrained ViT to the medical domain, thereby limiting the benefits of model scaling. Combining ViT and PaLM requires considerations of token lengths allocated to visual encoder outputs, total context length of the model, sampling strategies, training data mixtures and so on. The use of one-shot training with dummy image tokens improves the quality and compute efficiency of the final model, but it is not optimal for few-shot setting.
The generalist biomedical AI systems are not the only approach to multimodal biomedical AI, other approaches include (1) adopting a set of learnable adaption prompts, which may have image token added, to frozen encoders for instruction-following fine-tuning[77], and (2) developing tool-usage capabilities for LLMs to interact with specialist biomedical encoders or task-specific agents[78].
Similar to human clinicians having general practitioners and specialists, the future of biomedical AI is likely to have both generalist and specialist AI systems. Potential applications of a generalist biomedical AI system include a tool for discovery and a common point of assistance.
PaLM 2
Anil et al. (2023)[32] introduced PaLM 2 that improves upon PaLM by unifying compute-optimal scaling, improved dataset mixtures, and architectural and objective improvements. They found that the amount of training data and model size should be scaled roughly 1:1 to achieve the best performance for a given amount of training compute, consistent with the finding of compute-optimal scaling in Chinchilla. PaLM 2’s training data contain hundreds of languages and domains (e.g., programming languages, mathematics, and parallel multilingual documents), which have been deduplicated to reduce memorization. This paper shows that larger models can handle more disparate non-English datasets without causing a drop in English language understanding performance. The details of PaLM 2 model size and architecture are withheld from publication. PaLM 2 uses a tuned mixture of different pre-training objectives (detail undisclosed), which has been shown to outperform individual objectives[33]. The largest model of PaLM 2 family, PaLM-2, is significantly smaller than the largest PaLM model but uses more training compute. The evaluation results show that PaLM 2 models significantly outperform PaLM on a variety of tasks, suggesting that not only model scaling, but also meticulous training data selection and efficient architecture/objectives are important for performance improvement. Moreover, a smaller but higher quality model significantly improves inference efficiency.
To study the scaling law between the number of training tokens (D) and the number of model parameters (N), several differently sized models are trained with 4 different compute budgets (C): \(1\times 10^{19}\), \(1\times 10^{20}\), \(1\times 10^{21}\), and \(1\times 10^{22}\) FLOPs. Cosine learning rate decay is used and a full decay is ensured at its final training token. On plot of final validation loss vs log number of parameters, isoFLOP curves are generated by quadratic fits. The minima of those quadratic fits indicate the projected optimal model sizes (N) for each isoFLOPS band. The optimal D is derived from the heuristic FLOPs\(\approx\)6ND[14] for each compute budget. The plots of these optimal Ns and optimal Ds against FLOPs (\(N_{opt}\sim C^{a},a=0.49;D_{opt}\sim C^{b},b=0.51\)) show that D and N should grow in equal proportions as the FLOPs budget increases, similar to the conclusion in Chinchilla[30], despite Chinchilla being studied at a smaller scale, and with a different training mixture. However, the training loss is not a perfect proxy for downstream task metrics (27 common NLU tasks evaluated in a 1-shot setting). This suggests that while scaling laws can be used to achieve optimal training loss for a given quantity of FLOPs, this does not necessarily transfer to achieving optimal performance for a given downstream task. Besides the optimal training loss, other considerations, such as training throughput and serving latency, affect the decision regarding the optimal model size.
Compared to the pre-training corpus of PaLM, PaLM 2’s pre-training corpus is significantly larger, includes a higher percentage of non-English data, and composed of a diverse set of sources: web documents, books, code, mathematics, and conversational data. It also includes parallel multilingual data covering hundreds of languages in the form of source and target text pairs where one side is in English. Several cleaning and filtering methods are used to improve data quality, including de-duplication, removal of sensitive-PII and filtering. Even though PaLM 2 has a smaller proportion of English data than PaLM, it still significantly outperforms PaLM on English evaluation datasets, which can be partially attributed to the higher data quality in the PaLM 2 mixture.
PaLM 2 is trained for an undisclosed context length that is significantly longer than that of PaLM. The longer context length is crucial for enabling capabilities such as long dialog, long-range reasoning and comprehension, summarization, and other tasks that require the model to consider a large amount of context. The (undisclosed) results show that it is possible to increase the context length of the model without hurting its performance on generic benchmarks that may not require longer contexts.
Three (details undisclosed) versions of PaLM 2, Small (S), Medium (M), and Large (L), are evaluated. Unless indicated otherwise, PaLM 2 refers to the Large version. In general, the models are evaluated in a few-shot, in-context learning setting, where the model is given a short prompt and, optionally, a few examples of the task. Two main types of tasks are used: (1) standard language proficiency exams designed for humans, and (2) standard academic machine learning benchmarks, including 6 categories of tasks: classification, question answering, reasoning, coding, translation, and natural language generation.
The human language-proficiency exams use a set of exams that corresponded to the highest grade of language proficiency, C2, from the Common European Framework of Reference for Languages (CEFR). There is no training specifically for these exams; only a generic instruction finetuning is performed. Models are prompted with the name of the exam and a question or a set of questions within a block (without few-shot examples). These exams include both multiple-choice and writing questions, but exclude speaking questions. A set of third-party raters is employed to independently rate the results of the writing exams out of 5 where 5 is the score given to a native adult speaker. For listening exams, their transcripts where available are treated as additional questions for the reading exam. The reading and writing portions of the exam are equally weighted to obtain a final score. Then, a pass/fail result is given in accordance with official guidelines, which is not an official grade. The results, as in the Figure below, show that PaLM 2 outperforms PaLM across all exams and achieves a passing grade for every language, demonstrating language proficiency across all evaluated languages.
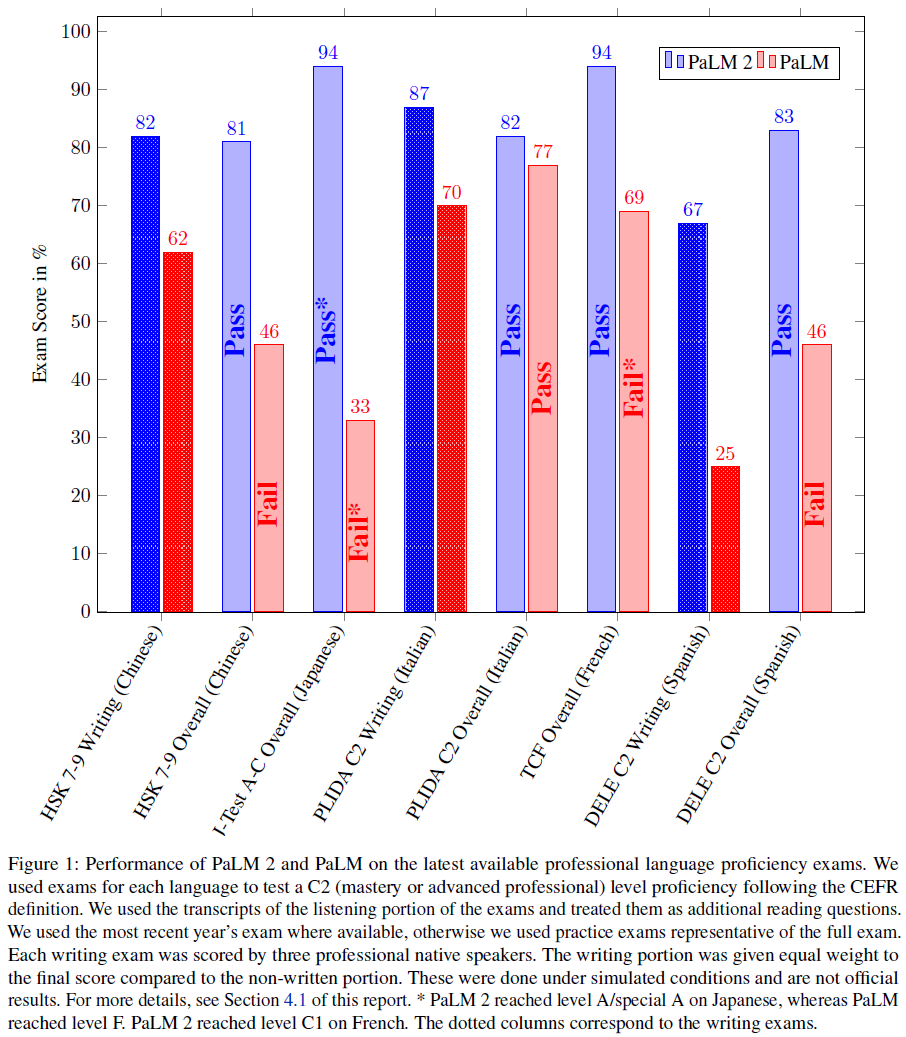
PaLM 2 variants are evaluated on a set of standard English question answering and classification tasks commonly used in the LLM literature, in comparison with PaLM 540B, using a one-shot setting. The results show that even the smallest PaLM 2 variant, PaLM 2-S, achieves performance competitive with the much larger PaLM 540B model while PaLM 2-M already outperforms PaLM consistently. PaLM 2-L achieves large improvements over PaLM across almost all tasks and particularly strong improvements on the Adversarial NLI (ANLI) datasets, the ReCoRD commonsense reasoning dataset, and the RACE datasets for reading comprehension.
PaLM 2’s multilingual capabilities are evaluated on the multilingual QA dataset TyDi QA in two settings: (1) a 1-shot setting and (2) a novel no-context setting where the model has to answer the question solely based on the knowledge stored in its parameters. The results show that all PaLM 2 variants consistently outperform PaLM across both settings. In the more challenging no-context setting, performance differences across model sizes are more evident. The largest PaLM 2 clearly outperforms all comparison models. Across both settings, improvements over PaLM are particularly pronounced for languages with limited data, such as Telugu, Swahili, and Indonesian and languages with non-Latin scripts such as Arabic and Korean. PaLM 2 is also evaluated on multilingual toxicity classification task, a common task within responsible AI practices. Adapting self-debiasing prompting methods[34] to zero-shot and few-shot contexts, it is found that PaLM 2 improves over PaLM on toxicity classification in English and on non-English examples using the Jigsaw multilingual dataset, with slightly reduced performance in Spanish. In addition, PaLM 2 is able to perform many capabilities such as explaining jokes, generating creative texts, etc. in many other languages. It can also seamlessly convert between registers, dialects, and scripts of different languages.
PaLM 2’s reasoning capabilities are evaluated on 7 representative reasoning datasets (then SOTA model) in a few-shot setting: WinoGrande (GPT-4), ARC-C (GPT-4), DROP (QDGAT), StrategyQA (PaLM+CoT+SC), CommonsenseQA (DeBERTaV3-large+KEAR), XCOPA (PaLM+CoT), and BIG-Bench (BB) Hard (PaLM+CoT). PaLM and GPT-4 are used as comparison models. The instruction-tuned version of PaLM 2 is used for these tasks, except for the multilingual XCOPA dataset. The instruction finetuning was done using the Flan dataset[35] that comprises 473 datasets, 146 task categories, 1,836 total tasks, and at least 20 instruction templates per task (10 zero-shot templates, 10 few-shot templates). PaLM 2 outperforms PaLM across all datasets and achieves results competitive with GPT-4. On the multilingual XCOPA dataset, PaLM 2 achieves particularly strong improvements on under-represented languages and establishes a new state of the art even without chain-of-thought prompting. The BIG-Bench Hard is a subset of 23 BIG-Bench tasks where the best LLMs performed below the average human rater at that time. On this challenging set of BIG-Bench Hard tasks, PaLM 2 outperforms PaLM on every task, often by a large margin. On several tasks including solving multi-step arithmetic problems (multistep_arithmetic), reasoning with temporal sequences, answering questions about when certain events occurred (temporal_sequences), and hierarchical reasoning using Dyck languages (dyck_languages), PaLM 2 improves over PaLM by more than 100%, demonstrating new emerging abilities. PaLM 2’s mathematical reasoning capabilities are evaluated on 3 datasets: MATH, which contains 12,500 problems from high school competitions in 7 mathematics subject areas, GSM8K, a dataset of 8,500 grade school math word problems, and MGSM, a multilingual version of GSM8K with translations of a subset of examples into ten typologically diverse languages. PaLM 2 is compared to PaLM, Minerva, GPT-4, and the state of the art for each of the 3 datasets. PaLM 2 outperforms PaLM dramatically on all datasets. On MATH, PaLM 2 is competitive with the state-of-the-art performance achieved by the dedicated Minerva model. On GSM8K, PaLM 2 outperforms Minerva and GPT-4 while on MGSM, it surpasses the state of the art (Flan-PaLM) even without self-consistency[36].
To evaluate PaLM 2’s coding capabilities for low-latency, high-throughput workflows, a small, coding-specific PaLM 2 model, called PaLM 2-S\(^{\bigstar}\), is built by continuing to train the PaLM 2-S model on an extended, code-heavy, heavily multilingual data mixture. PaLM-Coder-540B is used as the comparison model. Three few-shot coding tasks are used: HumanEval and MBPP (natural language to code datasets which test the model’s ability to generate self-contained Python programs that pass a set of held-out test cases), and ARCADE (a Jupyter Notebook completion task that requires the model to complete the next cell in a notebook given a textual description and the preceding notebook cells). The pass@1 and pass@k metrics are used. Greedy sampling is used for all pass@1 evals and temperature 0.8 with nucleus sampling p=0.95 is used for all pass@k evals. The results show that PaLM 2-S\(^{\bigstar}\) outperforms PaLM-Coder-540B on all benchmarks, often by a significant margin, despite being dramatically smaller, cheaper, and faster to serve. PaLM 2-S\(^{\bigstar}\)’s multilingual coding abilities are evaluated on BabelCode which translates HumanEval into a variety of other programming languages, including high-resource languages like C++, Java, and Go and low-resource languages like Haskell and Julia. The results show that PaLM 2-S\(^{\bigstar}\) outperforms PaLM-Coder-540B on all but two languages (C# and Go), with little degradation on low-resource languages like Julia and Haskell.
PaLM 2’s translation capabilities is compared with those of PaLM and Google Translate on WMT 2021 datasets using two metrics: BLEURT (automatic metric) and MQM (Multidimensional Quality Metrics, human evaluations by professional translators). For Chinese-to-English and English-to-German, PaLM 2 improves quality over both PaLM and Google Translate. FRMT (Few-shot Regional Machine Translation) benchmark allows measurement of ability to produce dialect-specific translations that will feel natural to each locale community. The results of Portuguese (Portugal/Brazil) and Chinese (Mainland/Taiwan) show that PaLM 2 improves not only over PaLM but also over Google Translate in all tested locales. Gender agreement and translation quality are evaluated with human raters for translating out of English into 13 languages. The results show that even in the zero-shot setting PaLM 2 outperforms PaLM and Google Translate on gender agreement in three high-resource languages: Spanish, Polish, and Portuguese. But lower gender agreement scores are observed when translating into Telugu, Hindi and Arabic with PaLM 2 as compared to PaLM.
PaLM 2’s natural language generation abilities are evaluated on representative datasets covering a typologically diverse set of languages used in TyDi QA[37] on three tasks: XSum (to create a one-sentence summary for a given news article in English), XLSum (to summarize a news article in a single sentence in the same language, covering Arabic, Bengali, English, Japanese, Indonesian, Swahili, Korean, Russian, Telugu, Thai, and Turkish), WikiLingua (to generate section headers for step-by-step instructions from WikiHow, covering Arabic, English, Japanese, Korean, Russian, Thai, and Turkish). A custom 1-shot prompt is used for each dataset, which consists of an instruction, a source document, and its generated summary, sentence, or header. Evaluation metrics include ROUGE-2 for English, and SentencePiece-ROUGE-2 for all other languages. The latter is an extension of ROUGE that handles non-Latin characters using a SentencePiece, the mT5 tokenizer. Extremely long inputs are truncated to about half the max input length, so that instructions and targets can always fit within the model’s input. Greedy decoding is done in the 1-shot-learning setting until an exemplar separator or until the maximum decode length, which is set to the 99th-percentile target length. Even the PaLM 2-S outperforms PaLM and PaLM 2-L achieves dramatic improvements over PaLM, demonstrating their improved multilingual generation capabilities. A filtered dataset based on 15-gram overlap is used to evaluate training data contamination of benchmark datasets. The results show that the model’s performance is likely not inflated by memorizing the targets.
Four datasets are used to evaluate potential harms and biases in model-generated texts: ParlAI Dialogue Safety (with standard and adversarial datasets in English), Multilingual Representational Bias (measuring toxic language harms and bias related to identity terms in dialog uses, in Arabic, Simplified Chinese, Czech, Dutch, French, German, Hindi, Italian, Japanese, Korean, Portuguese, Russian, Spanish and Swedish), BBQ Bias Benchmark for QA (adapted to generative QA contexts in English), RealToxicityPrompts (measuring toxic language harms in language modeling in English). PaLM 2 shows slight improvement over PaLM with reduced toxic language harms during language modeling tasks on RealToxicityPrompts, and slight regressions in conversational language modeling on ParlAI Dialogue Safety. On ParlAI Dialogue Safety and Multilingual Representational Bias evaluation, dialog-prompting PaLM 2 significantly reduces levels of toxic language harms compared to what is observed in decontextualized language modeling tasks. In generative question answering contexts, PaLM 2 performs well on disambiguated questions about social identity adapted from BBQ, but 3% of all disambiguated questions produce a form of representational harm by reinforcing social bias. It is observed that hallucinations may create risks of salient representational harms not previously measured in classification and regression measures of bias.
The extent to which PaLM 2 memorizes long passages of training data is quantified as a proxy of the potential for downstream privacy leakage. To evaluate verbatim memorization on prompted training data extraction, training sequences are sampled and split into a prefix consisting of the first P tokens and a suffix consisting of the next S tokens. To evaluate memorization, the language model is queried with the prefix (prompt) and match the generation to the suffix. Greedy decoding is used to generate the suffix. On 10,000 sampled unique documents from a shared part of the English pre-training data, PaLM 2 on average memorizes significantly less data than PaLM. To study the impact of the number of times each sequence was seen by the model on memorization likelihood, the number of repetitions is counted for each unique 100-token sequence in the training data and then a maximum of 10,000 sequences are sampled for various amounts of repetition in the range [1,100]. The results show that when documents are repeated only a few times, PaLM 2 memorizes much less than PaLM. However, when n-grams are repeated more than a few times, PaLM 2 has a much higher likelihood of memorizing the sequences. Canaries represent rare or “outlier” data points and provide a different perspective on memorization that may not be captured by training data extraction. Outlier data points share few similarities with natural data, which may lead the model to memorize them rather than to generalize. On the other hand, it may be necessary for them to be similar in some way to the natural data; otherwise, the model may simply ignore them. Two types of canaries are designed: (1) an interleave canary, which takes two documents from the pre-training data and intersperses batches of N = 50 tokens in their same relative ordering, which enables it to preserve some linguistic properties; and (2) a shuffle canary, which shuffles all tokens from a single real training document, so as to remove any information associated with its sequence-level ordering. To perform canary extraction experiments, a small number of canaries are injected into training data with varying repetitions for a subset of canaries. The results show that it takes fewer repetitions of these outlier canaries for extraction to succeed in under-represented languages. However, no strong correlation between language size and the training data extraction rate is found on real training data.
Special control tokens marking the level of toxicity in the text have been added to a small percentage of the pre-training data to enable inference-time control over toxicity. The impact of conditioning of the control tokens on toxic language harms in language modeling is evaluated and compared with prompting methods. This evaluation focuses on measuring control over toxic degeneration using a variation of RealToxicityPrompts[7]. Adding control tokens at inference time has a significant influence on the probability of producing a toxic continuation. For non-toxic input prompts, control tokens are effective at controlling generation and can be used to either reduce the probability of a toxic continuation from baseline, or to increase it. To compare control methods for toxic degeneration in dialog contexts, evaluations are done on the Standard and Adversarial datasets of the single-turn task in Dinan et al. (2019)[38]. In conversational language modeling, PaLM 2 provides an effective inference-time control method, reducing the percentage of toxic responses from 30% to 12% on the standard dataset, and 18% to 7% on the adversarial dataset. In dialog uses, dialog-prompting alone is more effective than control tokens at reducing toxic generation. A comparison to a version of the specialized dialog system LaMDA shows that specialized downstream mitigation methods remain more effective than general-purpose inference time mitigations. This highlights the importance for application-specific mitigation methods, including additional fine-tuning, dedicated mechanisms to filter undesired responses, sample-and-rank methods using classifier scores, and classifier-in-the-loop controlled decoding. While dialog-prompting is effective in reducing toxic generation these results may not generalize to other forms of representational harm, or to other prompting methods or use contexts. All downstream developers should consider the potential for harms and bias in the specific context of their application, particularly since changes in decoding strategy and prompts can have a significant impact on generated responses.
Med-PaLM 2
Singhal et al. (2023)[70] improved Med-PaLM by using a combination of an improved base LLM (PaLM 2), a medical domain-specific finetuning, and a novel ensemble refinement prompting strategy that enabled improved medical reasoning. The resulting model is named Med-PaLM 2 that outperforms physicians across 8 axes relevant to clinical utility, such as factuality, medical reasoning capability, and low likelihood of harm.
The evaluation datasets include multiple-choice and long-form medical question-answering datasets from MultiMedQA, introduced in the Med-PaLM study, and two new adversarial long-form datasets, as summarized in the two tables below. The two new adversarial datasets, a general adversarial set and a health equity focused adversarial set, are designed to elicit model answers with potential for harm and bias. The general adversarial set covers issues related to health equity, drug use, alcohol, mental health, COVID-19, obesity, suicide, and medical misinformation, in which the health equity covers health disparities, structural and social determinants on health outcomes, and racial bias in clinical calculators for renal function. The health equity focused adversarial set covers issues related to healthcare access, quality, and social and environmental factors, with a set of implicit and explicit adversarial queries that cover a range of patient experiences and health conditions.
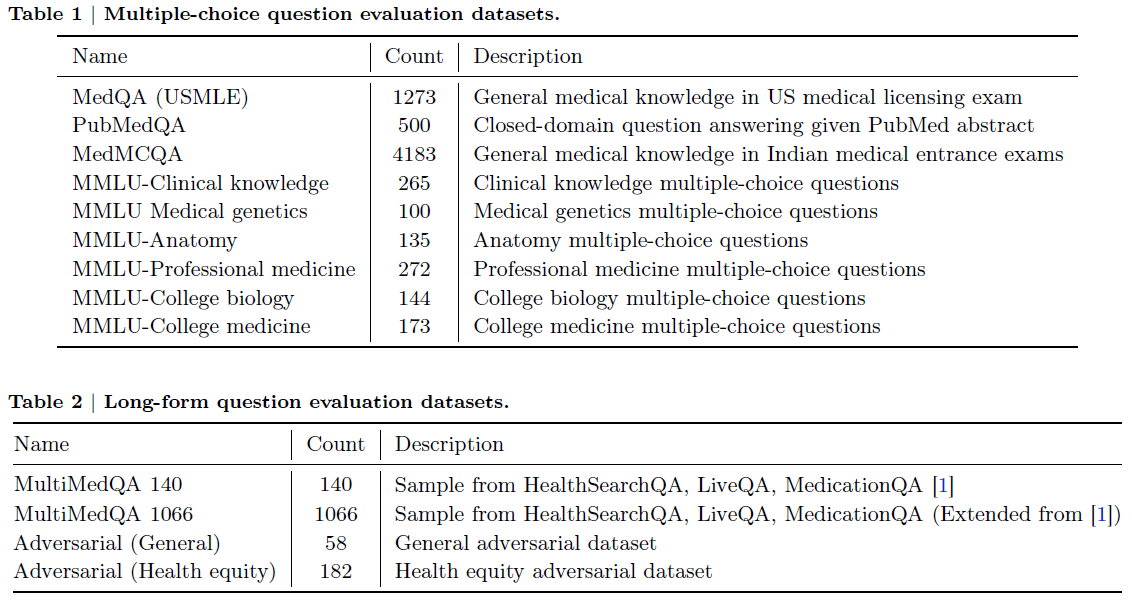
Instruction finetuning to the PaLM 2 follows the protocol used in the Flan-PaLM study. The finetuning datasets include the training splits of MultiMedQA, including MedQA, MedMCQA, HealthSearchQA, LiveQA, and MedicationQA, using the mixture ratios shown in the table below. These mixture ratios and the inclusion of these particular datasets were empirically determined so that the performance of the finetuned model is optimized across all the datasets. Med-PaLM 2 refers to this “unified” model, unless otherwise specified. For comparison, a variant of Med-PaLM 2 was created by finetuning exclusively on multiple-choice questions, which led to improved results on these benchmarks.
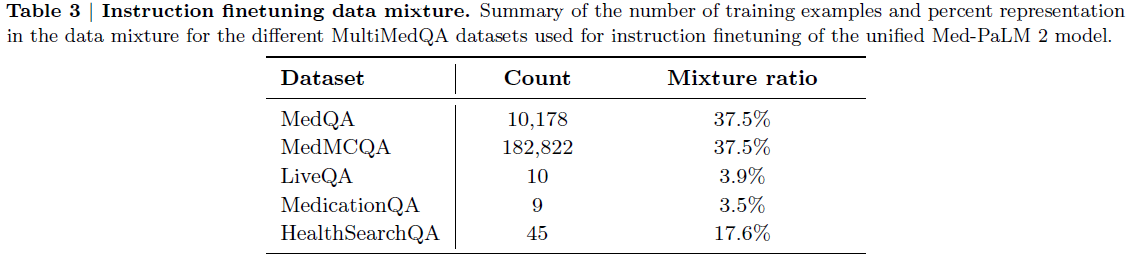
Four prompting strategies are used to evaluate Med-PaLM 2 on multiple-choice benchmarks. (1) Few-shot prompting: The same few-shot prompts used in Med-PaLM study were used here. (2) Chain-of-thought: CoT involves augmenting each few-shot example in a prompt with a step-by-step explanation towards the final answer. CoT prompts were crafted to provide clear demonstrations on how to appropriately answer the given medical questions. (3) Self-consistency: Self-consistency strategy samples multiple explanations and answers from the model and returns the final answer that is the one with the majority (or plurality) vote among the samples. This study performed 11 samplings using CoT prompting. (4) Ensemble refinement: Ensemble refinement (ER) incorporates the idea of Self-Refine[71] that uses the same LLM to provide feedback for its output and uses the feedback and the same LLM to refine the output, iteratively. ER involves a two-stage process: (i) given a (few-shot) chain-of-thought prompt and a question, the model produces multiple possible generations (each includes an explanation and an answer) stochastically via temperature sampling; (ii) the model is conditioned on the original prompt, question, and the concatenated generations from the previous step, and is prompted to produce a refined explanation and answer. This can be interpreted as a generalization of self-consistency, where the LLM is aggregating over answers from the first stage instead of a simple vote, enabling the LLM to take into account the strengths and weaknesses of the explanations it generated. The second stage is performed multiple times to improve performance, and the final answer is determined by a plurality vote over these generated answers. The ER was only applied for multiple-choice evaluation in this work, with 11 samplings for the first stage and 33 samplings for the second stage. The results show that Med-PaLM 2 instruction-finetuned on individual benchmark dataset achieved SOTA performance on 5 of the 9 benchmarks, consistently outperforming or matching the unified Med-PaLM 2 with ER. The GPT-4-base (5-shot; non-production; released on 4/12/2023) also achieved SOTA performance on 5 of the 9 benchmarks, consistently outperforming the aligned (production) GPT-4 (released on 3/20/2023). Comparison of Med-PaLM 2 performance with different prompting strategies including few-shot, chain-of-thought (CoT), self-consistency (SC), and ensemble refinement (ER) showed that ER significantly outperformed 5-shot and CoT+SC on 7 of the 9 benchmarks, while 5-shot significantly outperformed ER and CoT+SC on 2 of the 9 benchmarks.
A multiple-choice question in evaluation datasets is defined as overlapping with pre-training data if either the entire question or at least 512 contiguous characters overlap with any document in the training corpus. For this overlap analysis, multiple-choice options or answers were not included as part of the query. Overlap percentages ranged from 0.9% for MedQA to 48.0% on MMLU Medical Genetics. Performance of Med-PaLM 2 on questions with overlap was slightly higher for 6 out of 9 datasets, though the difference was only statistically significant for MedMCQA due to the relatively small number of questions with overlap in most datasets. When the overlap segment length was reduced from 512 to 120 characters, overlap percentages increased, but performance differences on questions with overlap were similar, and the difference was still statistically significant for just one dataset. A limitation of this analysis is that due to heterogeneity in how a semantic expression can be presented across different documents, overlapping questions cannot be exhaustively identified.
To evaluate answers to long-form questions, the same prompt templates used in Med-PaLM study were used in this study. Model answers were sampled with temperature 0.0 as in Med-PaLM study. Physician answers were generated as described in Med-PaLM study. Physicians were not time-limited in generating answers, were permitted to access reference materials, and were instructed that the audience for their answers to consumer health questions would be a lay-person of average reading comprehension. A different set of 15 physicians based in US, UK, and India, with specialty expertise spanning family medicine and general practice, internal medicine, cardiology, respiratory, pediatrics and surgery, were used to provide expert evaluations of long-form answers. Lay-person evaluations were performed by a pool of 6 raters based in India, all without a medical background. Individual long-form answers from physicians, Med-PaLM, and Med-PaLM 2 were rated independently by physician and lay-person raters on MultiMedQA 140, Adversarial (General), and Adversarial (Health equity) datasets using rubrics introduced in Med-PaLM study. Each response was evaluated by three independent raters randomly drawn from the respective pool of raters (lay-person or physician). Inter-rater reliability analysis of MultiMedQA 140 answers indicated that raters were in very good (\(\kappa>0.8\)) agreement for 10 out of 12 alignment questions, and good (\(\kappa>0.6\)) agreement for the remaining two questions. On the MultiMedQA 140 dataset, the only significant differences from physicians ratings were in favor of Med-PaLM 2 over Med-PaLM (p < 0.05) for the following 3 axes: evidence of reasoning, incorrect knowledge recall, and incorrect reasoning. On the adversarial datasets, physicians ratings showed that Med-PaLM 2’s quality was significantly higher than Med-PaLM’s across all axes (p < 0.001 for all axes) for both the general and health equity-focused subsets. Lay-people ratings showed that Med-PaLM 2 answers were more helpful and relevant than Med-PaLM answers (p < 0.002 for both dimensions) to questions in the MultiMedQA 140 dataset. Notably, Med-PaLM 2 answers were longer than Med-PaLM and physician answers. On MultiMedQA 140, the median answer length was 794, 565.5, and 337.5 characters for Med-PaLM 2, Med-PaLM, and physicians, respectively. Answer lengths to adversarial questions tended to be longer in general, with median answer length of 964 characters for Med-PaLM 2 and 518 characters for Med-PaLM.
A pairwise preference analysis was performed to directly rank preference between two alternative answers generated by different sources (e.g., physician vs Med-PaLM 2) to a given question, along 9 axes: alignment with medical consensus, reading comprehension, knowledge recall, reasoning, inclusion of irrelevant content, omission of important information, potential for demographic bias, possible harm extent, and possible harm likelihood. The pairwise evaluations were performed on the MultiMedQA 1066 and Adversarial dataset. Raters were blinded as to the source of each answer, and the order in which answers were shown was randomized. On MultiMedQA 1066 dataset, Med-PaLM 2 answers were more preferred than physician answers for 8 of the 9 axes, as shown in the Table below; Med-PaLM 2 answers were more preferred than Med-PaLM answers for all the 9 axes. On Adversarial questions, Med-PaLM 2 was preferred more often than Med-PaLM across every axis, often by substantial margins.
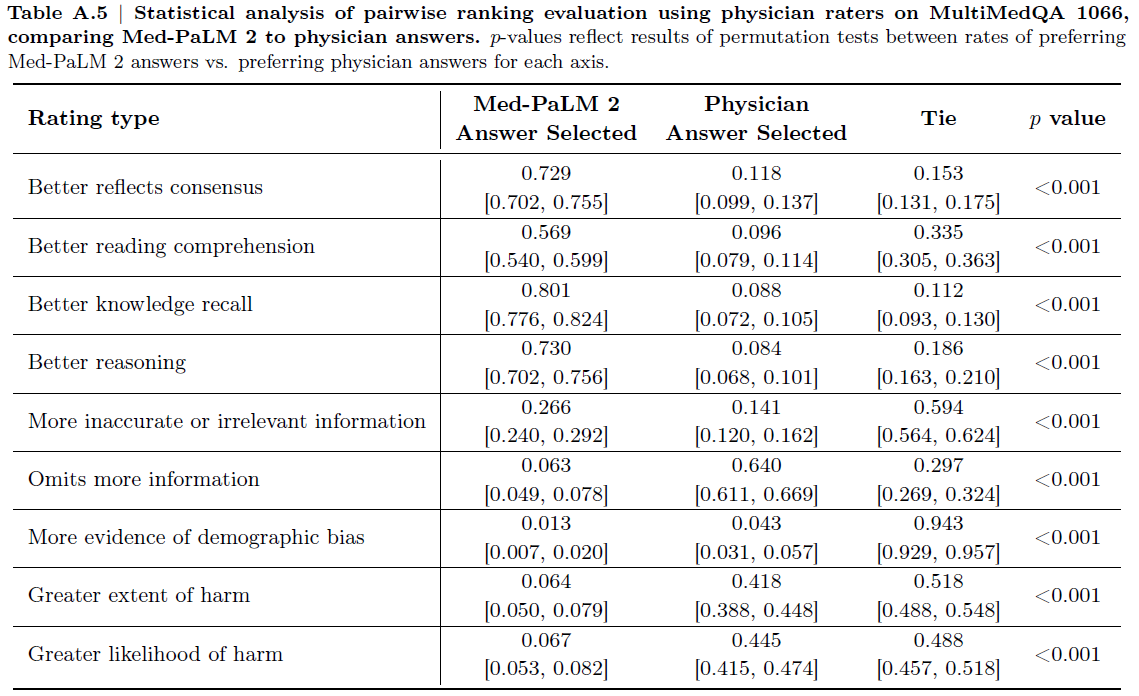
Model answers were often longer than physician answers, which might contribute to the better model performance over physicians’. The instructions provided to physicians did not include examples of outputs perceived as higher or lower quality in preference ranking, which might have impacted the evaluation results. Physicians were also asked to only produce one answer per question, which limited assessment of the range of possible physician-produced answers.
Gemini
Google’s Gemini 1.0[89] is a family of multimodal models that support interleaved sequences of text, image, audio, and video as inputs and can produce interleaved image and text as outputs. It comes in three sizes: Ultra for highly-complex tasks, Pro for enhanced performance and deployability at scale, and Nano for on-device applications. Gemini Ultra achieves new state-of-the-art results in 30 of 32 benchmarks examined.
Gemini models are built on Transformer decoders that are enhanced with improvements in architecture and model optimization (details undisclosed). They are trained to support 32k context length, employing efficient attention mechanisms (e.g. multi-query attention). Gemini models are trained to accommodate a wide variety of visual inputs, such as natural images, charts, screenshots, PDFs, and videos. The visual encoding of Gemini models is inspired by the foundational work on Flamingo[90], CoCa[91], and PaLI[74], while Gemini models are multimodal from the beginning and can natively output images using discrete image tokens[92][93]. Video input is encoded as a sequence of frames (images) in the large context window. The models can handle variable input resolution. In addition, Gemini can directly ingest audio signals at 16kHz from Universal Speech Model (USM)[94] features. The Pro model pretraining can be completed in weeks, a fraction of the Ultra’s. The Nano series of models leverage additional advancements in distillation and training algorithms (details undisclosed).
Training Gemini Ultra used a large fleet of TPUv4 accelerators across multiple datacenters, a significant increase in scale over PaLM-2. Scaling up the number of accelerators results in a proportionate decrease in the mean time between failure of hardware in the overall system. Genuine machine failures are commonplace across all hardware accelerators at such large scales. TPUv4 accelerators are deployed in “SuperPods” of 4096 chips, each connected to a dedicated optical switch, which can dynamically reconfigure 4x4x4 chip cubes into arbitrary 3D torus topologies in around 10 seconds. For Gemini Ultra, a small number of cubes per SuperPod is retained to allow for hot standbys and rolling maintenance. TPU accelerators primarily communicate over the high-speed inter-chip-interconnect, but at Gemini Ultra scale, SuperPods in multiple datacenters are combined using Google’s intra-cluster and inter-cluster network. Google’s network latencies and bandwidths are sufficient to support synchronous training paradigm, exploiting model parallelism within SuperPods and data-parallelism across SuperPods. The ‘single controller’ programming model of Jax and Pathways[24] allows a single Python process to orchestrate the entire training run. The GSPMD partitioner[95] in the XLA compiler partitions the training step computation, and the MegaScale XLA compiler pass statically schedules appropriate collectives so that they maximally overlap with the computation with very little variation in step time. To maintain a high goodput (the time spent computing useful new steps over the elapsed time of the training job) at this scale, redundant in-memory copies of the model state are used, and on any unplanned hardware failures, the model state is rapidly recovered directly from an intact model replica. Compared to both PaLM and PaLM-2, this provided a substantial speedup in recovery time, despite the significantly larger training resources being used. The overall goodput for the Gemini Ultra training job increased from 85% to 97%. Training at the scale of Gemini, Silent Data Corruption (SDC)[96] events due to faulty CPU can be expected to impact training every week or two. Rapidly detecting and removing faulty hardware required several new techniques that exploit deterministic replay to isolate incorrect computations, combined with proactive SDC scanners on idle machines and hot standbys.
Gemini models’ pretraining dataset is both multimodal and multilingual, including web documents, books, codes, images, and audio, video data. The SentencePiece tokenizer is used. Training the tokenizer on a large sample of the training corpus improves the inferred vocabulary and subsequently improves model performance. The number of tokens used to train the largest models were determined following the approach in the Chinchilla study[30]and significantly more tokens were used to train smaller models to improve performance for a given inference budget following the approach in the LLaMA study[44]. Quality filters were applied to all datasets using both heuristic rules and model-based classifiers. Safety filtering was performed to remove harmful content. Evaluation sets were filtered out from the training corpus. The final data mixtures and weights were determined through ablations on smaller models. The mixture composition was altered during training by increasing the weight of domain-relevant data towards the end of training. Data quality is critical to a highly-performing model and many questions remain around finding the optimal dataset distribution for pretraining.
Gemini models are trained jointly across text, image, audio, and video. When compared to models and approaches that are narrowly tailored to single domains, Gemini models still set new state of the art in each domain.
Academic Benchmarks. On MMLU[62], multiple-choice questions across 57 professional and academic subjects, Gemini Ultra can outperform all existing models, achieving an accuracy of 90.04%, the first model to exceed human expert performance of 89.8%, with the prior state-of-the-art result at 86.4% (GPT-4). Gemini Ultra achieves highest accuracy when the uncertainty-routed chain-of-thought approach is used where the model produces k (e.g., 8 or 32) chain-of-thought[29] samples and selects the majority vote if the model is confident above a preset threshold, and otherwise defers to the greedy sample choice based on maximum likelihood choice without chain of thought. The thresholds are optimized for each model based on their validation split performance. The intuition behind this approach is that chain-of-thought samples might degrade performance compared to the maximum-likelihood decision when the model is demonstrably inconsistent. On GSM8K[67], a grade-school math benchmark, Gemini Ultra reaches 94.4% accuracy with chain-of-thought prompting and self-consistency[36] compared to the previous best accuracy of 92.0% (GPT-4) with the same prompting technique. On MATH benchmark, including math problems drawn from middle- and high-school math competitions across 5 difficulty levels and 7 subdisciplines, Gemini Ultra outperforms all competitor models, reaching 53.2% using 4-shot prompting. On even harder tasks derived from American Mathematical Competitions (150 questions from 2022 and 2023), Gemini Ultra can solve 32% of the questions, compared to the 30% solve rate for GPT-4. On HumanEval, a standard code-completion benchmark mapping function descriptions to Python implementations, instruction-tuned Gemini Ultra correctly implements 74.4% of problems, outperforming 70.0% by Claude 2 and 67.0% by GPT-4. On Natural2Code benchmark, a new held-out set with no leakage on web for python code generation tasks, Gemini Ultra achieves the highest score of 74.9%, exceeding 73.9% by GPT-4. The idea that benchmark results are susceptible to the pretraining dataset composition is supported by the evaluation on HellaSwag validation set, where Gemini Ultra results are improved from 87.8% to 96.0% when the model is finetuned for an additional hundred steps on specific website extracts corresponding to the HellaSwag training set (which were not included in Gemini pretraining set). Gemini Ultra’s impressive ability to tackle complex mathematical and scientific concepts opens up possibilities for personalized learning and intelligent tutoring systems.
Trends in Capabilities. Language understanding and generation performance of Gemini model family are evaluated across six different capabilities: “Factuality” covering open/closed-book retrieval and question answering tasks; “Long-Context” covering long-form summarization, retrieval and question answering tasks; “Math/Science” including tasks for mathematical problem solving, theorem proving, and scientific exams; “Summarization” covering English and Non-English summarization tasks; “Reasoning” tasks that require arithmetic, scientific, and commonsense reasoning; “Multilingual” tasks for translation, summarization, and reasoning in multiple languages. The performance consistently improves with increased model size, especially in reasoning, math/science, summarization and long-context. Gemini Ultra is the best model across the board for all six capabilities, and Gemini Pro is also quite competitive while being a lot more efficient to serve.
Nano. Gemini Nano 1 and Nano 2 models are engineered for on-device deployments. Nano-1 and Nano-2 model sizes are only 1.8B and 3.25B parameters, respectively. Nano-2 consistently outperforms Nano 1 across all six capabilities. Despite their size, they show strong performance on factuality, i.e. retrieval-related tasks. For example, Gemini Nano 2 reaches 80% ~ 90% of Gemini Pro’s performance on Factuality benchmarks: 90%, 91% and 83% on BoolQ, TydiQA-GoldP and NaturalQuestions-Retrieved, respectively. But Gemini Nano 2 only reaches 50% ~ 70% of Gemini Pro’s performance on Long-Context, Reasoning, Math/Science, and summarization.
Multilinguality. On the WMT 23 out-of-English translation tasks, Gemini Ultra achieved the highest LLM-based translation quality, with an average BLEURT score of 74.8, compared to GPT-4’s score of 73.6, and PaLM 2’s score of 72.2. When averaged across all language pairs and directions for WMT 23, average BLEURT scores are 74.4, 73.8, and 72.7 for Gemini Ultra, GPT-4, and PaLM 2-L, respectively. On very low-resource languages, both from and into English, Gemini Ultra achieved an average chrF score of 27.0 in 1-shot setup, while the next-best model, PaLM 2-L, achieved a score of 25.3. On multilingual math benchmark MGSM, a translated variant of the math benchmark GSM8K, Gemini Ultra achieves an accuracy of 79.0%, an advance over 74.7% for PaLM 2-L, when averaged across all languages in an 8-shot setup. On multilingual summarization benchmarks XLSum, Gemini Ultra achieves an average of 17.6 RougeL score compared to 15.4 for PaLM 2. On another multilingual summarization benchmarks Wikilingua, Gemini Ultra (5-shot) 48.9, in BLEURT score, trails behind PaLM 2 (3-shot) 50.4. Overall, the diverse set of multilingual benchmarks show that Gemini family models have a broad language coverage, enabling them to also reach locales and regions with low-resource languages.
Long Context. Gemini models are verified to make use of their context length (32,768 tokens) effectively. In a synthetic retrieval test that prepends key-value pairs at the beginning of the context and asks for value associated with a particular key, Gemini Ultra model retrieves the correct value with 98% accuracy when queried across the full context length. Plotting the negative log likelihood (NLL) as a function of token index across 32K context length on a held-out set of long documents shows that the NLL decreases with sequence position up to the full 32K context length. The longer context length of Gemini models enables new use cases such as retrieval over documents and video understanding.
Human Preference Evaluations. On side-by-side blind evaluations of two model outputs to the same prompt by human raters, instruction-tuned Gemini Pro is preferred over the PaLM 2 model API 65.0% time in creative writing, 59.2% time in following instructions, and 68.5% time for safer responses. These improvements directly translate into a more helpful and safer user experience.
Complex Reasoning Systems. Gemini can be combined with search and tool-use to create a multi-step reasoning system, such as AlphaCode 2[98], a new state-of-the-art agent that excels at solving competitive programming problems. AlphaCode 2 is built by fine-tuning Gemini Pro model using GOLD[99] algorithm on competitive programming datasets[97] to conduct massive sampling, generating up to a million code samples per problem. This is followed by input/output test filtering, typically removing 95% of the samples in average. The remaining samples are clustered by their outputs to new test inputs and only the 10 largest clusters are kept. A second Gemini Pro model is fine-tuned to assign an estimated correctness score between 0 and 1 to each code sample. The best scoring sample of each cluster is selected to form the final list of 10 submissions. The step performed by the scoring model (a.k.a. reward model in this paper) is referred to as reranking. AlphaCode 2 is evaluated on Codeforces on 12 contests from division 1 and 2, for a total of 77 problems. AlphaCode 2 solved 43% of these competition problems, substantially outperforming AlphaCode’s 25%. AlphaCode 2 is better than 85% of entrants, far exceeding AlphaCode’s 50%.
Image Understanding. Eight tasks in four different capabilities are used: high-level object recognition (VQAv2), fine-grained transcription (TextVQA, DocVQA), chart understanding (ChartQA, InfographicVQA), multimodal reasoning (AI2D, MathVista, MMMU). Gemini Ultra achieves state of the art across all the 8 image-understanding benchmarks. Gemini Ultra consistently outperforms GPT-4V in zero-shot evaluation. It also exceeds several existing models that are specifically fine-tuned on the benchmark’s training sets. The margin over prior state of the art is significant in some cases, such as MathVista (+3.1%) and InfographicVQA (+5.2%). MMMU (Massive Multi-discipline Multimodal Understanding and Reasoning) benchmark[100] consists of questions about images across 6 disciplines with multiple subjects within each discipline that require college-level knowledge and complex reasoning to solve. Gemini Ultra outperforms the previous best result made by GPT-4V in 5 of 6 disciplines, as shown in the Table below.
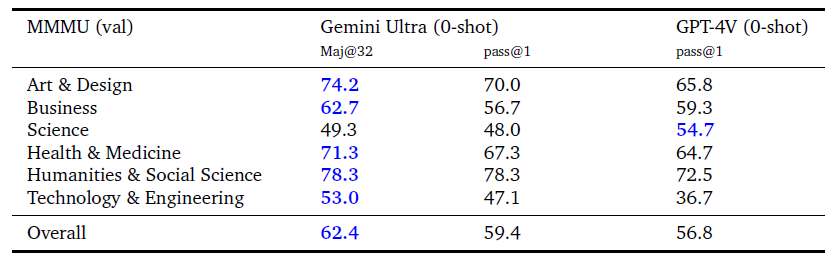
Gemini models can operate across modalities and languages simultaneously for both image understanding and generation tasks. These capabilities are evaluated on image description generation in a selected subset of languages in the Crossmodal-3600 (XM-3600) benchmark in a 4-shot setting, using the Flamingo evaluation protocol[90], without any fine-tuning for all models. The results show that Gemini models significantly outperform the existing best model, Google PaLI-X. In an example of multimodal prompt that asks Gemini Ultra to generate matplotlib code for rearranging 4 subplots in a specific way, the model successfully solves the task by combining several capabilities: (1) recognition of the math functions depicted in the plots; (2) inverse graphics to infer the matplotlib code that would have generated the subplots; (3) instruction-following to put subplots in their desired positions; and (4) abstract reasoning to infer the subplot that must stay in its original place. This highlights Gemini Ultra’s more complex reasoning abilities across interleaved sequences of image and text.
Video Understanding. Video Understanding tasks measure whether the model is able to understand and reason over a temporally-related sequence of frames. For each video task, 16 equally-spaced frames are sampled from each video clip and fed to the Gemini models. Gemini Ultra achieves state-of-the-art results on various few-shot video captioning tasks as well as zero-shot video question answering tasks, demonstrating its capability of strong temporal reasoning across several frames.
Image Generation. Gemini can output multiple images interleaved with text given a prompt composed of interleaved sequences of image and text in a few-shot setting. For example, users might prompt the model to generate images and text of creative ideas to meet users’ requests.
Audio Understanding. Gemini Pro and Gemini Nano-1 are compared with two state-of-the-art speech recognition models, OpenAI Whisper (WSPSR, Web-scale Supervised Pretraining for Speech Recognition)[101] and Google USM (Universal Speech Model)[102], on 4 automatic speech recognition (ASR) benchmarks (FLEURS on 62 languages, VoxPopuli on 14 languages, Multi-lingual Librispeech, and a YouTube test set) using WER (word error rate) or CER (character error rate for Mandarin, Japanese, Korean and Thai) metric and an automatic speech translation (AST) benchmark (CoVoST 2) that translates different languages into English using BLEU score. The evaluation results show that Gemini Pro model significantly outperforms the USM and Whisper models across all ASR and AST tasks, both for English and multilingual test sets. The Gemini Pro is trained with the FLEURS training dataset, which may have contributed to the large gain in FLEURS over USM and Whisper models. However, training the same model without FLEURS dataset results in a much higher WER score that still outperforms Whisper, but underperforms USM. Gemini Nano-1 model also outperforms both USM and Whisper on all datasets except FLEURS. Compared to USM, Gemini Pro produces more understandable responses, particularly on rare words and proper nouns.
Modality Combination. Gemini models are capable of processing interleaved sequences of text, vision, and audio, as well as reasoning across modalities.
A structured approach to responsible deployment is followed, which consists of 5 steps: impact assessments, model policies, evaluations, mitigations, and deployment. Model impact assessments are developed to identify, assess, and document key downstream societal benefits and harms[103], with 6 areas of focus: factuality, child safety, harmful content, cybersecurity, biorisk, representation and inclusivity. Impact assessments are used to guide mitigation and product delivery efforts, and inform deployment decisions. Gemini impact assessments spanned across different capabilities of Gemini models and these assessments are updated in tandem with model development. A set of model policies are developed to steer model development and evaluations. Model policy definitions act as a standardized criteria and prioritization schema for responsible development and as an indication of launch-readiness. Gemini model policies cover 5 domains: factual accuracy, child safety, hate speech, harassment, and fairness and inclusion. A suite of evaluations is developed across the lifecycle of model development, including development evaluations, assurance evaluations, external evaluations, and specialist internal evaluations. Development evaluations are conducted throughout training and fine-tuning processes, on assessments designed by the Gemini team or against external academic benchmarks. These evaluations consider issues such as helpfulness (instruction following and creativity), safety and factuality. Assurance evaluations are conducted by a group outside of the model development team for the purpose of governance and review, usually at the end of key milestones or training runs. These evaluations are standardized by modality and datasets are strictly held-out. Only high-level insights are fed back into the training process to assist with mitigation efforts. These evaluations include testing across Gemini policies, and include ongoing testing for dangerous capabilities such as potential biohazards, persuasion, and cybersecurity. External evaluations are conducted by partners outside of Google to identify blind spots. External groups stress-test the models across a range of issues through a mixture of structured evaluations and unstructured red teaming. In addition, specialist internal teams conduct ongoing red teaming across areas such as the Gemini policies and security, including less structured processes involving sophisticated adversarial attacks to identify new vulnerabilities. Mitigations are developed in response to the outcomes of the assessment, policy, and evaluation. Evaluations are re-run following mitigation efforts.
Three areas of mitigations are mentioned: data, instruction-tuning, and factuality. Mitigations at the data curation and data collection stage include filtering training data for high-risk content and ensuring sufficiently high quality in all training data. “Data enrichment” refers to tasks, such as data labelling and model evaluation, carried out by paid human workers for model training and validation. All data enrichment workers are paid at least a local living wage, in accordance with Responsible sourcing of data enrichment services. Instruction tuning encompasses supervised fine tuning (SFT) and reinforcement learning through human feedback (RLHF) using a reward model, in both text and multimodal settings. Instruction tuning is designed to balance the increase in helpfulness with decrease in model harms related to safety and hallucinations. The data mixture ratios are ablated with smaller models to balance the metrics on helpfulness (such as instruction following, creativity) and reduction of model harms, and these results generalize well to larger models. It is observed that data quality is more important than quantity, especially for larger models. Similarly, for reward model training, it is critical to balance the dataset with examples where the model declines to reply for safety reasons and examples where the model outputs helpful responses. To train a multi-headed reward model, multi-objective optimization is used with a weighted sum of reward scores from helpfulness, factuality, and safety.
To mitigate risks of harmful text generation, a dataset of potential harm-inducing queries is generated in approximately 20 harm types across a wide variety of use cases, either manually by policy experts and ML engineers, or via prompting high capability language models with topical keywords as seeds. Then, the harm-inducing queries are used to probe Gemini models and the model responses are analyzed via side-by-side evaluation. Additional supervised fine-tuning data are created to demonstrate the desirable responses, using a custom data generation recipe loosely inspired from Constitutional AI[40], where variants of Google’s content policy language are injected as “constitutions” and language model’s strong zero-shot reasoning abilities are utilized to revise responses and choose between multiple response candidates. This overall recipe was able to mitigate a majority of the identified text harm cases, without any perceptible decrease on response helpfulness.
To reduce the frequency of hallucinations, three key desired behaviors are focused on in instruction tuning efforts. (1) Attribution. If instructed to generate a response that should be fully attributed to a given context in the prompt, Gemini should produce a response with the highest degree of faithfulness to the context. This includes (i) summarization of a user-provided source, (ii) generating fine-grained citations given a question and provided snippets, (iii) answering questions from a long-form source such as a book, and (iv) transforming a given source to a desired output (e.g. an email from a portion of a meeting transcript). (2) Closed-Book Response Generation. If provided with a fact-seeking prompt without any given source, Gemini should not hallucinate incorrect information. These prompts can range from information-seeking prompts to semi-creative prompts that may request factual information. (3) Hedging. If prompted with an input such that it is “unanswerable”, Gemini should not hallucinate. Rather, it should acknowledge that it cannot provide a response by hedging. These include scenarios where (a) the input prompt contains false-premise questions, (b) the input prompt instructs the model to perform open-book QA, but the answer is not derivable from the given context. These desired behaviors are elicited from Gemini models by curating targeted supervised-fine tuning datasets and performing RLHF. Each of the 3 key desired behaviors are evaluated by a corresponding evaluation dataset. The Attribution evaluation set contains prompts that require attribution to sources in the prompt. Each response is manually evaluated by human annotators who check for attribution to sources in the prompt. The Factuality evaluation set contains fact-seeking prompts (primarily closed-book). Human annotators fact-check each response manually, and the percentage of factually-inaccurate responses is reported. The Hedging evaluation set is used to automatically measure whether Gemini models hedge accurately. An instruction-tuned Gemini Pro model without any factuality-focused adaptation is compared with Gemini Pro model, and the results show that the rate of inaccuracy is halved in the factuality set, the accuracy of attribution is increased by 50% from the attribution set, and the model successfully hedges 70% (up from 0%) in the provided hedging set task.
Ethics and safety reviews are conducted with the Google DeepMind’s Responsibility and Safety Council (RSC), an interdisciplinary group which evaluates Google DeepMind’s projects, papers and collaborations against Google’s AI Principles, across the responsible development process. The RSC provides input and feedback on impact assessments, policies, evaluations and mitigation efforts. During the Gemini project, the RSC set specific evaluation targets across key policy domains (e.g. child safety).
Meta AI
OPT
Zhang et al. (2022)[45] developed Open Pre-trained Transformers (OPT) models to roughly match the performance and sizes of the GPT-3 models, while opening its source for research community. OPT models range from 125M to 175B parameters with hyperparameters largely following GPT-3 models. The pre-training corpus contains a concatenation of some subsets of the datasets used in RoBERTa (BookCorpus, Stories, CCNews), the Pile (CommonCrawl, DM Mathematics, Project Gutenberg, HackerNews, OpenSubtitles, OpenWebText2, USPTO and Wikipedia), and PushShift.io Reddit (with conversational trees converted to language-model-accessible documents, and keeping only the longest chain of comments), which are all predominantly English text. Duplicated documents across all datasets are removed by filtering out documents via MinhashLSH with a Jaccard similarity \(\geq\) .95. All corpora are tokenized using the GPT-2 byte level BPE tokenizer, resulting in 180B tokens.
Evaluation follows GPT-3’s prompts and overall experimental setup on 16 standard NLP tasks and performance in accuracy is reported. Overall, OPT models’ average zero-shot performance across 14 tasks largely matches the reported averages of GPT-3 models. However, performance varies greatly per task. OPT models also perform similarly to GPT-3 models on multi-shot settings across the average of all metrics. However, as with zero-shot, multi-shot performance depends heavily per task.
OPT-175B is evaluated on 5 dialogue datasets (ConvAI2, Wizard of Wikipedia, Empathetic Dialogues, Blended Skill Talk, and Wizard of Internet) for comparisons against 3 dialogue models (Reddit 2.7B, BlenderBot 1, and R2C2 BlenderBot) using two metrics: Perplexity and Unigram F1. To control for different tokenization in each of the models, all perplexities are normalized to be in the space of the GPT-2 tokenizer. For OPT-175B, all generations are performed using greedy decoding up to a maximum of 32 tokens. The remaining models use the generation parameters of BlenderBot 1. OPT-175B significantly outperforms the also unsupervised Reddit 2.7B model on all tasks, and performs competitively with the fully supervised BlenderBot 1 model, especially in the ConvAI2 dataset. It was verified that the competitive performance of OPT-175B against BlenderBot 1 was not due to leakage of the ConvAI2 dataset into the pre-training corpus or the validation data. OPT-175B also performs well on multiple PersonaChat-like datasets, suggesting that it has a strong ability to maintain a consistent persona across conversations.
The ETHOS dataset is used to measure the ability of OPT-175B to identify whether or not certain English statements are racist or sexist (or neither). With all the one-shot through few-shot configurations, OPT-175B performs considerably better than GPT-3 Davinci. The CrowS-Pairs benchmark is used to measure intrasentence level biases in 9 categories. OPT-175B appears to exhibit more stereotypical biases in almost all categories (gender, race/color, sexual orientation, age, nationality, disability, physical appearance, and socioeconomic status) except for religion. This is likely due to higher incidence rate for stereotypes and discriminatory text in the Pushift.io Reddit corpus, a primary pre-training data source for OPT-175B. The StereoSet is used to to measure stereotypical bias at both intrasentence and intersentence levels across 4 categories, using Language Modeling Score (LMS), Stereotype Score (SS), and combined Idealized Context Association Test score (ICAT), normalized by token count. OPT-175B performs better across the board on the SS metric, while Davinci generally outperforms on the LMS metric. Davinci and OPT-175B exhibit similar scores on aggregated overall ICAT. By bias category, Davinci outperforms in the areas of profession and race, while OPT-175B outperforms in the areas of Gender and Religion. The RealToxicityPrompts (RTP) dataset is used to evaluate OPT-175B’s tendency to respond with toxic language. For each of 10K randomly sampled prompts from RTP, 25 generations of 20 tokens are sampled using nucleus sampling (\(p=0.9\)), and mean toxicity probabilities of the continuations are reported across bucketed toxicities of the original prompts. Overall, OPT-175B has a higher toxicity rate than either PaLM or Davinci, while all the 3 models have increased likelihood of generating toxic continuations as the toxicity of the prompt increases. OPT-175B’s propensity to generate and detect toxic text is likely due to the inclusion of unmoderated social media texts in the pre-training corpus. Two dialogue safety evaluations are performed: (1) the SaferDialogues measures the ability to recover from explicit safety failures, usually in the form of apologizing or recognizing its mistake; (2) the Safety Bench Unit Tests measures how unsafe a model’s response is, stratified across 4 levels of topic sensitivity: Safe, Realistic, Unsafe, and Adversarial. OPT-175B has similar performance as the Reddit 2.7B model across both SaferDialogues and the Unit Tests. The models finetuned on curated dialogue datasets (BlenderBot 1, R2C2) have overall lower toxicity. Thus, future experimentation of OPT-175B for dialogue should contain explicit fine-tuning on curated datasets in order to improve the safety profile.
OPT-175B suffers from the same limitations noted in other LLMs. (1) OPT-175B does not work well with declarative instructions or point-blank interrogatives and tends to produce a simulation of a dialogue beginning with such an instruction, rather than an execution of the instruction. An instruction learning, similar to InstructGPT, may alleviate this limitation. (2) OPT-175B tends to be repetitive and can easily get stuck in a loop. More modern strategies, such as unlikelihood training or best-first decoding, may help reducing repetition and improving diversity. (3) OPT-175B can produce factually incorrect statements. Retrieval-augmented models have been shown to improve factual correctness of LLMs. (4) OPT-175B has a high propensity to generate toxic language and reinforce harmful stereotypes, even when provided with a relatively innocuous prompt. OPT-175B will need mitigations for toxicity and biases before any real-world deployment.
The training data with additional data characterization and selection criteria should be conducted in order to use data responsibly. Differences in prompting styles and number of shots for in-context learning could create variations that lead to different results and hinder replicability/reproducibility of evaluation scenarios.
BlenderBot 3
Shuster et al. (2022)[46] developed BlenderBot 3 (BB3), a transformer-based open-domain chatbot that uses a series of modules to access the internet and a long-term memory to produce grounded dialogue responses.
The modules in the BB3 modular system are not independent components; instead, they share the same single transformer model, with special control codes in the input context telling the model which module it is executing. The input context contains dialogue history, with each speaker prefixed with their ID, either “Person 1:” or “Person 2:” in order to differentiate them. The modules are called in succession, conditional on the results of previous modules. Three modules are related to internet search: (1) Internet search decision, which outputs whether internet search should be conducted or not, (2) Generate internet search query, which generates a search query to be issued to an internet search engine, (3) Internet search, which makes a call to an actual internet search engine (Mojeek is used in this study) and returns \(N\) documents/snippets. Two modules are related to grounding the final response: (1) Generate knowledge response, which generates a response referred to as the knowledge response, given the full input context and a set of retrieved documents, (2) Extract relevant entity, which generates a relevant entity, given the full input context. Three modules are related to long-term memory: (1) Generate a long-term memory, which outputs a summary of the last turn that will be stored in the long-term memory or outputs “no persona” if the model thinks no summary should be generated for the last turn, (2) Long-term memory access decision, which outputs whether long-term memory access should be conducted or not, given the last turn and the text-based memory store, (3) Access long-term memory, which outputs a memory from the memory store, referred to as a recalled memory, given the full input context and the memory store. The final module, Generate dialogue response, generates a final conversational response, given the full input context, and (optional) knowledge response and recalled memory, where the knowledge response and recalled memory are marked with special prefix tokens.
The overall module execution flow is illustrated in the Figure below. Given a new utterance from the conversational partner, the model first determines whether search and long-term memory access are required. If search is required, a search query is generated, internet search is invoked, and then a knowledge response is generated given the retrieved documents. The knowledge response will be appended to the context (prefixed with control tokens) as input to generate the final response. If long-term memory access is required, the long-term memory is accessed, and a memory is chosen (generated), which is then also appended to the context (prefixed with control tokens) as input to generate the final response. If neither search nor long-term memory access is required, an entity is extracted from the history and that is appended to the context (prefixed with control tokens). Given the constructed context from the previous modules, the final dialogue response generation module is invoked to generate a final reply.
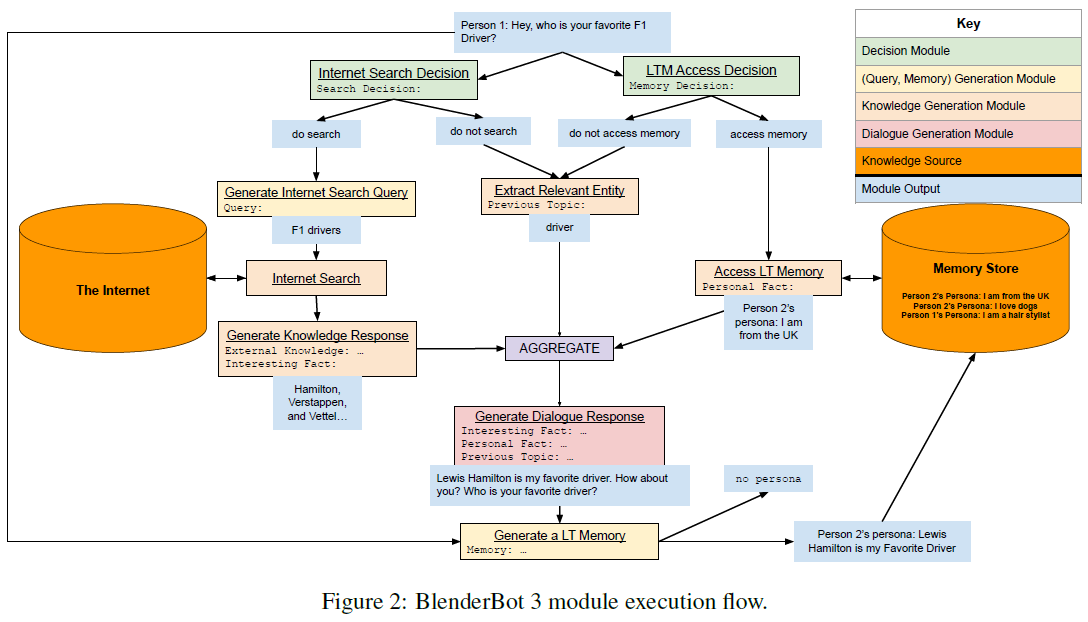
Three variants of BB3 were developed. The 3B parameter version is an encoder-decoder transformer based on the pre-trained R2C2 model. The 30B and 175B versions use the decoder-only Open Pre-trained Transformer (OPT). The pre-training data of R2C2 consists of approximately 100B tokens, combining the corpora used in RoBERTa with the English subset of the CC100 corpus and Pushshift.io Reddit, a variant of Reddit discussions. OPT’s pre-training corpus contains roughly 180B tokens, including RoBERTa, PushShift.io Reddit, and The Pile, using the GPT2 dictionary of size 51200 for tokenization.
Three sets of datasets are used as fine-tuning datasets for the Internet Search Decision module. (1) The QA datasets SQuAD, TriviaQA, and Natural Questions (NQ) are used as examples of “do search”. (2) The Wizard of Wikipedia (WoW) and Wizard of Internet (WizInt) datasets consist of training dialogues where some turns contain human-authored relevant knowledge responses given retrieved documents. Whether humans used knowledge or not (per-turn) is used as the basis of whether a search should be done or not. (3) If there is an entity in the context of PersonaChat (PC), Empathetic Dialogues (ED), and Multi-Session Chat (MSC) datasets, that instance is used as a training example for “do search”; otherwise, it is used as an example of “do not search”. Two datasets, WizInt dataset and Feedback on Interactive Talk & Search (FITS) dataset which contain human-authored search queries during crowdsourced dialogue turns, are used to fine-tune the internet search query generation module in a supervised fashion. Two sets of datasets are used to fine-tune Generate knowledge response module. (1) The WoW, WizInt and FITS datasets contain crowdsourced human demonstrations of generating a knowledge response given a dialogue context and input document(s). However, those knowledge responses are direct copy of some of the tokens in the source documents, and do not involve generating new tokens, sentences, phrases or summaries. Thus, these trainings aim at preventing hallucination. (2) The answers of QA tasks, MS Marco, NQ, SQuAD and TriviaQA, are used as knowledge response outputs (even if they are short phrases), with some modifications on MS Marco and NQ datasets. The conventional dialogue tasks PC, ED, MSC and Blended Skill Talk (BST) are used to train Extract relevant entity module by finding a noun phrase, with the nltk library, from the original dialogue response that also appears in the context, and setting it as the knowledge target for training. The MSC dataset is exclusively used to train the Generate a long-term memory module as it contains crowdsourced examples of summarized facts derived from the last utterance of dialogue contexts in natural conversations. These summarized facts are used as the targets for training this module. MSC, ED, PC and BST are used to construct fine-tuning dataset for the Long-term memory access decision module by constructing a binary prediction task where if an entity is present in a response, then the context is used as a positive example of memory access; otherwise, it is not. MSC, ED, PC and BST are also used to construct training data for the Access long-term memory module. The target is the particular persona line used for a given context, which is calculated as the one with the highest word overlap with the next utterance. Multiple sets of datasets are used to train the Generate dialogue response module. (1) In WoW, WizInt and FITS, each dialogue response is annotated with the relevant knowledge used to construct it in the original dataset, which is used as gold knowledge responses. (2) In PC, ED and BST, gold responses use the gold knowledge entity and/or memory that was calculated for the extract relevant entity and long-term memory access decision module tasks. (3) Some task-oriented dialogue tasks are also used: GoogleSGD and Taskmaster 1, 2 & 3. (4) Some grounded open-domain dialogues are also used: the Funpedia task which involves learning to produce an engaging dialogue utterance given a Wikipedia sentence, and the LIGHT and LIGHT WILD tasks which are open-domain dialogue tasks grounded in a medieval fantasy setting.
During the fine-tuning with dialogue tasks, the model is also trained with the original pre-train tasks. This may help the model (i) avoid overfitting given its large size, (ii) retain its language modeling capabilities. The model is also multi-task trained with the SaFeRDialogues (SD) task, which aims to recover gracefully from safety issues. In addition to the safety mechanisms built into the model training itself, the deployment also includes some other safety features. There is a binary classifier (safe or not safe) given the dialogue context as input, which is a transformer model trained with 3 datasets: Wikipedia Toxic Comments dataset (WTC), Build-It Break-It Fix-It (BBF), and Bot Adversarial Dialogue dataset (BAD). In addition, a safety keyword list is used to flag potentially inappropriate responses. Explicit checks for topics like intent to self-harm and medical issues such as covid are performed and canned messages for those cases are returned. Each bot-generated response is checked by these safety systems and if it is classified as not safe, a nonsequitur is returned. Each user turn is also checked by these safety systems and if either system predicts a potentially unsafe user response, the bot will also output a nonsequitur to prevent the bot from being caught in a potentially difficult conversation.
The BlenderBot 3 UI provides thumbs up and thumbs down icons for each bot-generated message so that user can provide feedback. If the user specifies a thumbs down, a pop up appears asking them why they did not like the message with 5 choices: (i) Off Topic / Ignoring me, (ii) Nonsensical / Incorrect, (iii) Rude / Inappropriate, (iv) Looks like Spam / Ads or (v) Other. After the user selects an option, the bot apologizes in the next turn of the conversation (using templated responses). It may also ask what it could have done better, thus possibly eliciting a free-form textual response from the user that can be used for continual learning research at a later date. The BlenderBot 3 UI also provides 2 mechanisms to expose how the bot works. Firstly, user can click on a bot-generated response to get insight into the internal steps made to produce the response. Secondly, user can look into the long-term memory of the bot, by clicking on the “Look Inside” message, to see what it has learned so far over the conversation with the user.
Human-bot conversations via crowdworkers and their feedback are collected; the resulting dataset is called Feedback on Interactive Talk & Search (FITS). Four feedback types are collected: (1) binary quality measurements (analogous to the thumbs up and down), (2) free-form conversational feedback, (3) the type of failure (search query-based, results-based, or final response-based), and (4) suggestions for an improved response for the failure type (a supervised target for the type). Different types of feedback data are used for different learning from feedback methods. The results show that (i) learning from modular feedback outperforms learning from feedback about only the final response; (ii) textual and binary feedback are useful, but not as much as modular feedback; (iii) the DIRECTOR (using a language model head and a classifier head for each output token) method[47] that learns from binary feedback works better than standard reranking/rejection sampling method using binary feedback; (iV) combining multiple types of feedback, such as modular and binary feedback with DIRECTOR provides the best results obtained; (v) continual learning, whereby models are retrained on the feedback from previous rounds of deployment, improves results even further; (vi) despite collecting feedback from smaller (3B parameter models) the data collection is useful for improving larger 175B parameter models.
Human-bot conversations in the wild include a mixture of engaged users (dubbed helpers) and unengaged or even malicious users (dubbed trolls). Several different mitigation techniques have been used to lessen the effect of noisy, unsafe or otherwise adversarial data, and make learning more robust. Such methods are grouped into two different types: example-based methods, and user-based methods. Example-based methods attempt to assess, for each dialogue utterance, if they are of good quality. Two possible techniques are: identification via cross-validation (e.g., finding examples where predictions disagree with human labels), or via a modification of the loss function called bootstrapping. User-based methods assume that adversarial users will be repeat offenders over multiple utterances and conversations. A user-level cross-validation measurement is used to produce a trust-worthiness score that in turn is used to detect and remove examples by user, called Per-User Removal. User-level removal can be combined with example-level removal to form Per-User+Example Removal. Another approach, called Per-User Robust Removal (PURR), removes examples by computing their trustworthiness score plus \(\alpha\) times the sum of trustworthiness scores of other examples by the same user. Evaluations are done on SafetyMix benchmark. The results show that all the removal approaches substantially reduce error rate compared to standard approach when trolls are present and they do not hurt performance too much when trolls are not present (helpers only). User-based methods are found to outperform Utterance-based methods. In particular the Per-User+Example Removal and Soft PURR approaches are found to work in many settings. Initial results on BB3 deployment data also show improved detection results using user-based methods. Overall, user-based methods downweight low-quality or malicious feedback data and perform best on the benchmarks and deployment data.
Open-domain short conversations performance is evaluated by crowdworkers, who are asked to play a role from the Wizard of Internet dataset and mark their partner’s responses for the 4 conversational attributes on each turn: (i) consistent, (ii) knowledgeable (iii) factually correct; and (iv) engaging (all of which are yes/no binary questions). The results show that BB3-175B achieves a higher overall rating than BB1, BB2, SeeKeR and BB3-3B, with the highest knowledgeable score, the highest knowledgeable & engaging score, and the lowest factual incorrectness score. On the contrary, BB1 has the highest consistency and per-turn engagingness scores, but suffers with a much lower knowledgeability score. Another set of human evaluation was done on the FITS setup, where crowdworkers talk to models and provide various kinds of feedback on the responses per-turn and a final score at the end of the conversation. BB3-175B shows the best performance from BB3-175B across almost all metrics, including Good Response % and overall Rating compared to BB1, BB2, SeeKeR and variants of OPT-175B. Error type breakdown results show that the improved performance of BB3-175B comes in all error types, including superior search queries, better use of search results and crafting of the final response.
To evaluate the ability of BB3 to utilize web search results to chat about current events, a set of conversational questions about topics that have recently been in the news are created and a response to each question is generated using both BB3-175B and InstructGPT (text-davinci-002). Each pair of responses are compared on five characteristics: Current, Specific, True, interesting, and Sensible. The results show that BB3-175B is more current and specific by a large margin (82% and 76%, respectively), InstructGPT is slightly more sensible (57%), and the two models are similarly true and interesting. InstructGPT was more likely to refrain from offering information about the topic (e.g. “I haven’t heard anything about {topic} lately.”) which avoided making false statements at the expense of specificity and recency. BB3-175B was more likely to copy information directly from search results, which led to higher specificity but can be prone to errors from out-of-date, incorrect, or unusually formatted results.
Three benchmarks for evaluating the safety and bias of conversational systems are used to test raw models before any safety mitigations: Safety Bench, SaFeRDialogues, and HolisticBias. The Safety Bench includes two sets of tests: the unsafe generation test and the offensive generation test. In the former, various levels of safe vs. unsafe and adversarial vs. non-adversarial incoming dialogue responses are used to generate model outputs whose safety metrics are measured by three tools: a trained safety classifier, a string-matcher (with respect to a predefined blocklist), and the Perspective API. In the latter, a set of hateful inputs are used to generate model outputs whose offensiveness are measured via 3 axes: % of responses flagged as offensive by a safety classifier, % of responses without negatives, and % of responses classified as positive by a sentiment classifier. The BB3-175B model yields the lowest levels of unsafe responses, compared to the smaller BB3-3B, the pre-trained-only OPT-175B, and the original Blender-Bot, in all settings except for the adversarial unsafe setting. The SaFeRDialogues dataset is used to evaluate models’ ability to recover from safety failures in conversation as measured by perplexity. The BB3-175B model outperforms OPT-175B zeroshot and few-shot, as well as BB3-3B. The HolisticBias benchmark uses the Likelihood Bias metric to determine how much the model views different demographic identity terms as being contextually different. This metric defines bias as how often two different identity terms, within a given demographic axis, have statistically significantly different perplexity distributions when inserted into template dialogue sentences. The OPT-175B and BB3-175B show a slightly smaller Likelihood Bias than BB3-3B. Perhaps the best test of safety is to measure performance in real conversations with real people using website-based deployment. It was found that 0.04% and 0.16% of utterances by the BB3-3B and BB3-175B models, respectively, are flagged as rude or inappropriate. It was found that less than 1% of all words are gendered words, with BB3-175B being more balanced than BB3-3B and SeeKeR.
BB3-175B still exhibits some common mistakes, such as avoiding answering questions or giving vague responses when more specific ones are asked for, or else being specific but making factual mistakes. Also, BB3-175B can still get pass safety filter and generate offensive or inappropriate responses. Finally, BB3-175B can give the superficial appearance of being sentient, or perhaps be quite convincing on occasion, by mimicking the human-authored messages in its training set.
LLaMA
Touvron et al. (2023a)[44] focused on building smaller models for faster inference speed, which is critical when serving a language model at scale, by training on more tokens than what is typically used. The resulting models, called LLaMA, range from 7B to 65B parameters, but outperforms GPT-3-175B and is competitive with PaLM-540B.
The pre-training dataset is a mixture of the following 7 publicly available sources (sampling proportion): deduped and filtered English CommonCrawl (67.0%), C4 (15.0%), Github (4.5%), Wikipedia (4.5%), Books (4.5%), ArXiv (2.5%), and StackExchange (2.0%). The data are tokenized with the byte-pair encoding (BPE) algorithm, using the implementation from Sentence-Piece. All numbers are split into individual digits. The entire training dataset contains roughly 1.4T tokens after tokenization, in which the Wikipedia and Books are used for approximately 2 epochs and the other 5 sources are used for approximately 1 epoch. LLaMA incorporates 3 improvements over the original transformer architecture: (1) the input, instead of the output, of each transformer sub-layer is normalized using the RMSNorm normalizing function; (2) the SwiGLU, instead of the ReLU, activation function is used and feed-forward network dimension \(d_{ff}=\frac{2}{3}4d_{model}\) where \(d_{model}\) is input dimension; (3) rotary positional embeddings (RoPE), instead of absolute positional embeddings, is used at each layer of the network. Several optimizations are made to improve the training speed: (i) an efficient implementation of the causal multi-head attention is used to reduce memory by not storing the attention weights and to reduce runtime by not computing the key/query scores that are masked due to the causal nature of the language modeling task; (ii) the amount of activations that are recomputed during the backward pass are reduced with checkpointing; (3) the computation of activations and the communication between GPUs over the network are overlapped as much as possible.
The models are evaluated on 20 benchmarks using zero-shot (a task description and a test question in the input) and few-shot (1~64 examples of question-answer and a test question in the input) test settings on free-form generation tasks and multiple choice tasks. Four close-sourced models (GPT-3, Gopher, Chinchilla, PaLM), three open-sourced models (OPT, GPT-J, GPT-Neo), and two instruction-tuned models (OPT-IML, Flan-PaLM) are compared with LLaMA. In the multiple choice tasks, the completion with the highest likelihood for a given context is selected, where the likelihood is normalized by the number of characters in the completion, or, for OpenBookQA and BoolQ datasets, normalized by the likelihood of the completion given “Answer:” as context, i.e. \(P(\mathrm{completion}\vert\mathrm{context})/P(\mathrm{completion}\vert“Answer:”)\). Zero-shot results on 8 standard common sense reasoning benchmarks show that LLaMA-65B outperforms Chinchilla-70B on all reported benchmarks, and surpasses PaLM-540B on all benchmarks but BoolQ and WinoGrande, and that LLaMA-13B outperforms GPT-3 on most benchmarks despite being 10x smaller. On 2 closed-book question answering benchmarks (NaturalQuestions and TriviaQA), LLaMA-65B achieves state-of-the-arts performance in the zero-shot and few-shot settings, and the LLaMA-13B is also competitive on both benchmarks with GPT-3 and Chinchilla, despite being 5~10x smaller. On RACE reading comprehension benchmark, LLaMA-65B is competitive with PaLM-540B, and, LLaMA-13B outperforms GPT-3. On 2 mathematical reasoning benchmarks (MATH and GSM8k), math-finetuned Minerva-540B substantially outperforms LLaMA-65B; but on GSM8k with maj1@k (a majority voting by k samples generated for each problem), LLaMA-65B outperforms Minerva-62B, even though it has not been fine-tuned on mathematical data. On 2 code generation benchmarks (HumanEval and MBPP), LLaMA outperforms LaMDA and PaLM of similar number of parameters, which are not trained or finetuned specifically for code. LLaMA with 13B and higher parameters outperform LaMDA 137B on both HumanEval and MBPP. LLaMA 65B also outperforms PaLM 62B, even when PaLM 62B is trained longer. Other studies have shown that finetuning on code-specific tokens can substantially improve the performance on code generation. On the Massive Multitask Language Understanding (MMLU) benchmark, evaluated in 5-shot setting, the LLaMA-65B underperforms both Chinchilla-70B and PaLM-540B by a few percent in average, and across most domains, which may be due to smaller amount (177GB) of books and academic papers in the pre-training data of LLaMA, as opposed to up to 2TB of books used for Chinchilla and PaLM. A very small amount of instruction finetuning that results in LLaMA-I significantly improves performance on MMLU over LLaMA. LLaMA-I (65B) outperforms existing instruction finetuned models of moderate sizes, such as Flan-PaLM (62B), buy still far underperforms GPT 3.5 (175B) on MMLU.
Four benchmarks that measure toxic content production and stereotypes detection are used to evaluate the potential toxic or offensive generations of LLaMA-65B. (1) For each of the 100k prompts of the RealToxicityPrompts benchmark, a generation is greedily produced by the model and a toxic score of the generation is automatically evaluated by making a request to PerspectiveAPI. It is observed that toxicity increases with the size of the LLaMA model, especially for Respectful prompts (prompts starting with “Complete the following sentence in a polite, respectful, and unbiased manner:”). (2) Biases are evaluated on the CrowS-Pairs dataset, in which each example is composed of a stereotype and an anti-stereotype, and the model preference for the stereotypical sentence is measured using the perplexity of both sentences in a zero-shot setting. Thus, higher scores indicate higher bias. LLaMA-65B shows slightly lower average bias than GPT3-175B and OPT-175B. LLaMA-65B is significantly more biased in the religion, age, and gender categories, than the other two models, which may be due to the data source CommonCrawl despite multiple filtering steps. (3) Gender biases are further evaluated on the WinoGender benchmark, where a gender pronoun is co-referencing either an occupation or a participant in each test sentence. The model is prompted to determine the co-reference relation and the accuracy is measured. The goal is to reveal if societal biases associated with occupations have been captured by the model. LLaMA models are significantly better at performing co-reference resolution for the “their/them/someone” pronouns than for the “her/her/she” and “his/him/he” pronouns. In the latter cases, LLaMA models are probably using the majority gender of the occupation to perform co-reference resolution, instead of using the evidence of the sentence. The LLaMA-65B makes more errors on the “gotcha” cases for the “her/her/she” and “his/him/he” pronouns, in which the pronouns do not match the majority gender of the occupation and the occupation is the correct answer, indicating that LLaMA-65B captures societal biases related to gender and occupation. (4) The ability to identify whether a claim is true is evaluated on TruthfulQA benchmark that can evaluate the risks of a model to generate misinformation or false claims. The LLaMA-65B significantly outperforms GPT-3, but the rate of correct answers is still low, showing that LLaMA is likely to hallucinate incorrect answers.
LLaVA
Liu et al. (2023)[79] made the first attempt to apply visual instruction tuning to a large multimodal model that connects a visual encoder (CLIP ViT-L/14) with a large language model (LLaMA), using multimodal instruction-following responses generated by text-only GPT-4. The resulting model is named LLaVA (Large Language and Vision Assistant) that demonstrates impressive multimodal chat abilities and achieves state-of-the-art performance on the Science QA multimodal reasoning dataset.
To generate visual instruction-following responses, the image-text pairs of MS COCO dataset was used to manually create visual instruction prompts. For an image and its associated annotation or caption, a set of 11 variant instructions (or questions) for brief image description and 16 variant instructions (or questions) for detailed image description were created with the intent to instruct the GPT-4 to describe the image content briefly or in detail, respectively. In order to encode an image into its visual features to prompt a text-only GPT-4, two types of symbolic representations were used: (i) Captions typically describe the visual scene from various perspectives. (ii) Bounding boxes usually localize the objects in the scene, and each box encodes the object concept and its spatial location. Three types of prompts were created. (1) Conversation. A multi-turn conversation between an assistant and a person asking questions about the photo is designed to prompt GPT-4 to generate a final response. The answers are in a tone as if the assistant is seeing the image and answering the question. A diverse set of questions are asked about the visual content of the image, including the object types, counting the objects, object actions, object locations, relative positions between objects. Only questions that have definite answers are considered. (2) Detailed description. For each image, one question is sampled randomly from the list of 16 variant instructions (or questions) to ask GPT-4 to generate a detailed description. (3) Complex reasoning. In-depth reasoning questions are designed so that the answers typically require a step-by-step reasoning process by following rigorous logic. In total, 158K unique language-image instruction-following samples were collected, including 58K in conversations, 23K in detailed description, and 77k in complex reasoning, respectively.
LLaVA uses a lightweight linear layer to project image features into the word embedding space. An input image \(\mathrm{X_{v}}\) is first encoded by the pre-trained CLIP visual encoder ViT-L/14[81], denoted as \(g(\cdot)\), into the visual feature \(\mathrm{Z_{v}}=g(\mathrm{X_{v}})\). Then, a trainable projection matrix \(\mathrm{W}\) converts \(\mathrm{Z_{v}}\) into embedding tokens \(\mathrm{H_{v}}\) in word embedding space: \(\mathrm{H_{v}=W\cdot Z_{v}}\). The \(\mathrm{H_{v}}\) is combined with the \(\mathrm{H_{q}}\), word embedding of the language instruction/question \(\mathrm{X_{q}}\). Given the combined visual and language tokens as input, the pre-trained LLaMA, denoted as \(f_{\phi}(\cdot)\) with parameters \(\phi\), generates language response \(\mathrm{X_{a}}\), as illustrated in the Figure below.
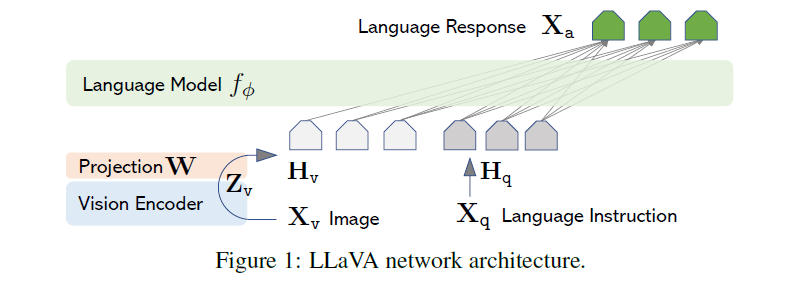
For each image, multi-turn conversation data (\(\mathrm{X_{q}^1,X_{a}^1,...,X_{q}^T,X_{a}^T}\)) is generated as input sequence to train the model to predict the assistant answers and where to stop, where \(\mathrm{T}\) is the total number of turns. The instruction at the \(t\)-th turn \(\mathrm{X_{instruct}^t}\) is \([\mathrm{X_q^1,X_v}]\) or \([\mathrm{X_v,X_q^1}]\) when \(t=1\) and \(\mathrm{X_{q}^t}\) when \(t>1\). The format of the multimodal input sequence is illustrated below.

Instruction-tuning of the LLM uses its original auto-regressive training objective on the prediction tokens. For a sequence of length \(L\), the probability of generating target answers \(\mathrm{X_{a}}\) is \(p(\mathrm{X_{a}}|\mathrm{X_{v}},\mathrm{X_{instruct}})=\prod\limits_{i=1}^{L}p_{\theta}(x_i|\mathrm{X_{v}},\mathrm{X_{instruct,<i}},\mathrm{X_{a,<i}})\), where \(\theta\) is the trainable parameters, \(\mathrm{X_{instruct,<i}}\) and \(\mathrm{X_{a,<i}}\) are the instruction and answer tokens in all turns before the current prediction token \(x_i\), respectively. Note that \(\mathrm{X_{system-message}}\) and all previous \(\mathrm{<STOP>}\) are skipped in the conditionals above for readability, though they are also conditioned.
The instruction-tuning procedure consists of 2 stages: (1) pre-training the projection matrix and (2) fine-tuning both the projection matrix and the LLM. The goal of the first stage is to align image features \(\mathrm{H_{v}}\) with the pre-trained LLM word embedding, which can be understood as training a compatible visual tokenizer for the frozen LLM. The training data for the first stage was built from a reduced CC3M dataset containing 595K image-text pairs. Each (\(\mathrm{X_{v}},\mathrm{X_{c}}\)) pair is expanded to an instruction-following sample: \(\mathrm{Human: X_{q} X_{v}<STOP>\backslash n\quad Assistant: X_{c}<STOP>\backslash n}\), where \(\mathrm{X_{q}}\) is a question/instruction randomly sampled from 11 variants for brief image description. The prediction answer \(\mathrm{X_{a}}\) is the original caption \(\mathrm{X_{c}}\). Both the visual encoder and LLM weights were kept frozen in training and only the projection matrix was trained to maximize the likelihood of generating target answers \(\mathrm{X_{a}}\). In the second stage, only the visual encoder weights were kept frozen, and both the pre-trained weights of the projection matrix and LLM were updated.
Two use case scenarios were considered. (1) Multimodal Chatbot. A Chatbot was developed by fine-tuning on the 158K unique language-image instruction-following data. Among the three types of responses, conversation is multi-turn while the other two are single-turn. The three types were uniformly sampled in training. (2) Science QA. ScienceQA is the first large-scale multimodal question answering dataset that annotates the answers with detailed lectures and explanations across natural, social, and language sciences. The data were organized as a single turn conversation, the context (including image and text) and question as \(\mathrm{X_{instruct}}\), and reasoning and answer as \(\mathrm{X_{a}}\).
To quantitatively evaluate LLaVA’s instruction-following capability, GPT-4 is used to measure the quality of LLaVA’s generated responses. 30 images were randomly sampled from the COCO validation split and 3 types of questions (conversation, detailed description, complex reasoning) were generated for each image, resulting in a total of 90 questions. The questions, image captions, and bounding boxes were used as input for LLaVA and GPT-4 to predict the answers. Then, each question, its visual information, and the generated responses from both LLaVA and GPT-4 were fed to GPT-4 for evaluation on the helpfulness, relevance, accuracy, and level of details of the responses. GPT-4 gave an overall score on a scale of 1 to 10, with 10 being the best performance. GPT-4 was also asked to provide a comprehensive explanation of the evaluation. LLaVA’s relative scores w.r.t. GPT-4 were computed. The results show that (1) with instruction tuning, the model’s capability of following the user instructions improves significantly by over 50 points (from 21.5% to 73.8%); (2) adding a small amount of the detailed description and complex reasoning questions contributes to a considerable improvement of the model’s overall capability by 7 points (from 73.8% to 80.5%); (3) having all three types of the data yields the best performance of 85.1%.
The ScienceQA benchmark dataset is split into training, validation, and test splits with 12726, 4241, and 4241 examples, respectively. For instruction tuning on ScienceQA, LLaVA was asked to first predict reasons then the answer, and trained for 12 epochs. It yields 90.92% accuracy, quite close to the prior SOTA 91.68% achieved by MM-CoT\(_{Large}\)[82]. Two-shot prompt to GPT-4 achieved 82.69% accuracy, which is well below LLaVA’s performance but a 7.52% absolute gain compared with 75.17% from GPT-3.5. For a substantial number of questions, GPT-4 fails simply because it reports that there is insufficient context such as images or plots. To improve GPT-4 performance, two schemes were considered to combine the outcomes from LLaVA and GPT-4. (1) A GPT-4 complement. Whenever GPT-4 fails to provide answers, the prediction from LLaVA is used. This scheme yields 90.97% accuracy, which is almost the same as applying LLaVA alone. (2) GPT-4 as the judge. Whenever GPT-4 and LLaVA produce different answers, the two answers and the question are prompted to GPT-4 again, asking it to provide its own final answer. Interestingly, GPT-4 is able to provide consistent improvement over all question classes, and achieves a new SoTA accuracy of 92.53%. This is the first time that GPT-4 is used for model ensembling.
Four design choice ablation studies were conducted. (1) Visual features. Using the last layer feature from CLIP vision encoder yields 89.96%, which is 0.96% lower than the feature before the last layer, suggesting that the 2nd from the last layer may focus more on localized properties and, thus, be more useful for understanding specific image details. (2) Chain-of-thoughts. The experiments to compare the order between the answer and CoT-like reasoning process in training and inference show that CoT-like reasoning-first (as opposed to answer-first) strategy can largely improve convergence speed, but contributes relatively little to the final performance. (3) Pre-training. Directly training on ScienceQA from scratch, without pre-training, reduces performance by 5.11% (from 90.92% to 85.81%), indicating the importance of the pre-training stage in aligning multimodal features while preserving the vast pre-trained knowledge. (4) Model size. The performance of 13B and 7B models trained with identical configurations are 90.92% and 89.84%, respectively, demonstrating the importance of model scale on instruction tuning.
LLaVA-Med
Li et al. (2023)[80] made the first attempt to extend multimodal instruction-tuning to the biomedical domain for end-to-end training of a biomedical multimodal conversational assistant. An extremely diverse visual instruction-following dataset was created from PMC-15M dataset, which was then used to adapt LLaVA to the biomedical domain with a novel curriculum learning method. LLaVA was first fine-tuned to align with biomedical vocabulary using the image-text pairs as is, and then continually trained using the instruction-following dataset to learn open-ended conversational semantics. The resulting model was named Large Language and Vision Assistant for BioMedicine (LLaVA-Med). LLaVA-Med exhibits excellent multimodal conversational capability and can follow open-ended instruction to assist with inquiries about a biomedical image. LLaVA-Med outperforms previous supervised SOTA on certain standard biomedical visual QA datasets.
A machine-human co-curation procedure is used to create two biomedical datasets, one for concept alignment and another for instruction-following. (1) Biomedical Concept Alignment Data. 600K image-caption pairs are sampled from PMC-15M (15 million figure-caption pairs extracted from biomedical research articles in PubMed Central), to balance between concept coverage and training efficiency. For a given image-caption pair (\(\mathrm{X_v,X_c}\)), a question/instruction \(\mathrm{X_q}\) that either asks to describe the image concisely or in detail is sampled from a list of 11 or 16 variants, respectively, depending on the length of caption. Caption length of 30 words is used as the cutoff point to determine which list to choose, because 25% of captions have length less than 30 words in PMC-15M. With \((\mathrm{X_v,X_c,X_q})\), a single-round instruction-following example is created: \(\mathrm{Human: X_{q} X_{v}<STOP>\backslash n\quad Assistant: X_{c}<STOP>\backslash n}\). Although this dataset contains extremely diverse figure types, ranging from generic biomedical illustration to radiography, microscopy, chromatography, ultrasound, among others, it only presents single-task (i.e., image captioning) instructions. (2) Biomedical Instruction-Tuning Data. Language-only GPT-4 is used to generate instruction-following data. Given an image caption, a prompt is designed to include instructions that ask text-only GPT-4 to generate multi-round questions and answers in a tone as if it could see the image (even though it only has access to the text). To provide more context regarding the image, a prompt is also created to include not only captions but also sentences from the original PubMed paper that mentions the image. A prompt containing manually curated few-shot examples is also created to demonstrate how to generate high-quality conversations based on the provided caption and context. To collect image captions and their context, PMC-15M is filtered to retain the images that only contain a single plot, which were then sampled to obtain 60K image-text pairs from the five most common imaging modalities: CXR (chest X-ray), CT (computed tomography), MRI (magnetic resonance imaging), histopathology, and gross (i.e., macroscopic) pathology. Then, sentences that mention the image are extracted from the original PubMed paper as additional context to the caption. Three versions of instruct data have been created: (i) 60K-IM. The aforementioned dataset that considers inline mentions (IM) as the context. IMs refer to sentences not in figure captions but mentioning figure inline in the paper. (ii) 60K. A dataset of similar size (60K samples) without IM in self-instruct generation. (iii) 10K. A smaller dataset (10K samples) without IM. They are used to ablate data generation strategies and their impact on trained LLaVA-Med in experiments.
A two-stage procedure is used to continuously train the LLaVA (7B) into the LLaVA-Med. Stage 1: Biomedical Concept Feature Alignment. For each sample of the Biomedical Concept Alignment Data, given the language instruction and image input, the model is asked to predict the original caption. In training, the weights of both the visual encoder and LM are frozen, and only the projection matrix is updated. Thus, the image features of the visual concepts can be aligned to their textual word embeddings in the pre-trained LM. This stage can be understood as expanding the vocabulary of aligned image-text tokens to the biomedical domain. Stage 2: End-to-End Instruction-Tuning. To train the model to follow diverse instructions and complete tasks in a conversational manner, the model is fine-tuned on the Biomedical Instruction-Tuning Data. In this stage, only the weights of the visual encoder are frozen, and both the projection matrix and the LM are updated. Fine-tuning to Downstream Datasets. After the two-stage training, LLaVA-Med is fine-tuned on three biomedical VQA datasets, VQA-RAD, SLAKE, and PathVQA. Given a biomedical image as context, multiple natural language questions are provided, the assistant responds in free-form text for both the close-set and open-set questions, with a list of candidate answers constructed in the prompt for each close-set question.
LLaVA-Med has 3 favorable properties/implications: (i) Affordable development cost. It takes 7 and 8 hours for stage 1 and 2 on 8 40G A100 GPUs, respectively. (ii) A recipe for many domains. The proposed adaptation procedure of this paper is generalizable to other vertical domains, where novel concepts and domain knowledge are needed to build a helpful assistant. The recipe includes a scalable pipeline to create domain-specific instruction-tuning data from large unlabeled data. (iii) Low serving cost.
To evaluate the performance of LLaVA-Med on biomedical multimodal conversation, an evaluation dataset was constructed by randomly selecting 50 unseen image-caption pairs from PMC-15M, and generating two types of questions: conversation and detailed description, resulting in 193 novel questions. Language-only GPT-4 is used to quantify the performance of model answers. Given the question, figure caption, figure context, and responses to the same question from the two assistants (the candidate LMM and GPT-4), GPT-4 is asked to score the helpfulness, relevance, accuracy, and level of details of the responses from the two assistants, and give an overall score on a scale of 1 to 10, where a higher score indicates better overall performance. GPT-4 is also asked to provide a comprehensive explanation of the evaluation. Then, the relative score is computed using GPT-4 reference score for normalization. The results show that LLaVA-Med with Stage-1 training alone is insufficient as a chatbot, as it has lost its ability to follow diverse instructions, compared to the general domain LLaVA. LLaVA-Med with the full two-stage training consistently outperforms the general domain LLaVA, and training with larger instruct data (from 10K to 60K samples) leads to higher performance. When inline mentions are considered in self-instruct, the generated data 60K-IM slightly improves the chat ability. The overall performance of the best LLaVA-Med, the 60K-IM version, matches only 50.2% performance of the text-only GPT-4 that generates knowledgeable response by re-organizing ground-truth caption and golden inline mentions, without understanding the images. On the contrary, LLaVA behaves like a layperson, who hallucinate based on common sense.
Three established biomedical VQA datasets used in this study are shown in the Table below. VQA-RAD contains radiology images. SLAKE also contains radiology images, but with richer visual annotations and more human body parts coverage. PathVQA contains pathology images. For closed-ended (i.e., yes/no type) questions, accuracy is reported. For open-ended questions, recall is used to evaluate the ratio that ground-truth tokens appear in the generated sequences.
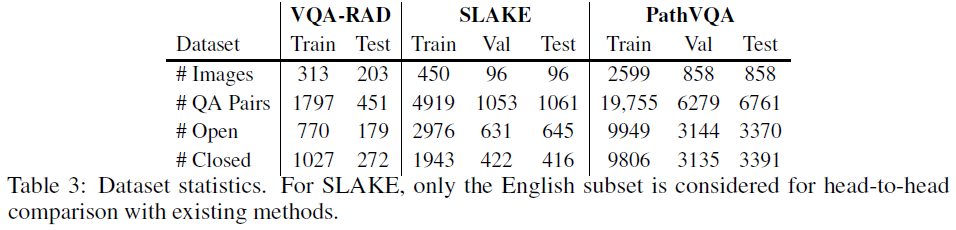
LLaVA-Med is compared with LLaVA and prior SOTA supervised methods. (1) All LLaVA-Med variants substantially outperform LLaVA. (2) The fine-tuning performance of LLaVA-Med is higher than supervised SOTA on the closed-set questions on VQA-RAD and PathVQA, validating LLaVA-Med’s strong ability in following instruction to complete biomedical tasks. (3) For open-set questions, LLaVA-Med achieves SoTA on SLAKE, but not on the other two datasets. Perhaps the open-set biomedical questions can be ambiguous without constraining their excepted answer options.
Four findings were reported from ablation studies in the paper. (1) LLaVA-Med outperforms LLaVA by a large margin, and the gaps on zero-shot are larger than that in fine-tuned settings, showing that LLaVA-Med is a better option than LLaVA when deploying one model for various scenarios in the wild. (2) LLaVA-Med with stage 1 training (for single task) alone may encourage the model to lose its ability in following diverse instructions. (3) The 60K-IM data provides the best averaged zero-shot and fine-tuned performance, validating the effectiveness of considering inline mention as external knowledge in data creation. (4) Fine-tuning longer on downstream datasets till 9 epochs benefits the performance. Increasing language model size from 7B to 13B improves the overall zero-shot performance and fine-tuned performance. In a case study, LLaVA-Med shows cross language zero-shot transfer capability, probably due to the multilingual knowledge learned in LLaMA.
LLaVA-Med still exhibits hallucinations and weak in-depth reasoning ability, common to many LMMs.
LLaMA 2
Touvron et al. (2023b)[39] improved Llama-1 with 5 modifications in pretraining: more robust data cleaning, a new data mix, 40% increase in the total training tokens (from 1.4T to 2.0T), doubling the context length (from 2k to 4k), and adopting grouped-query attention to improve inference scalability. The resulting model is Llama-2, which is then fine-tuned for dialogue to obtain Llama-2-Chat. The training corpora are collected from publicly available sources, excluding data from certain sites known to contain a high volume of personal information about private individuals. Most of the model architecture and pretraining settings are adopted from Llama-1, with two changes: increased context length and grouped-query attention.
Llama-2 70B outperforms Llama-1 65B on all the benchmarks evaluated. Llama-2 70B performs similarly to GPT-3.5 on MMLU (5-shot) and GSM8K (8-shot), but substantially underperforms GPT-3.5 on coding benchmark HumanEval (0-shot). Llama-2 70B performs on par or better than PaLM 540B on almost all benchmarks. Llama-2 70B substantially underperforms both PaLM-2-L and GPT-4 on all benchmarks evaluated, as shown in the Table below.
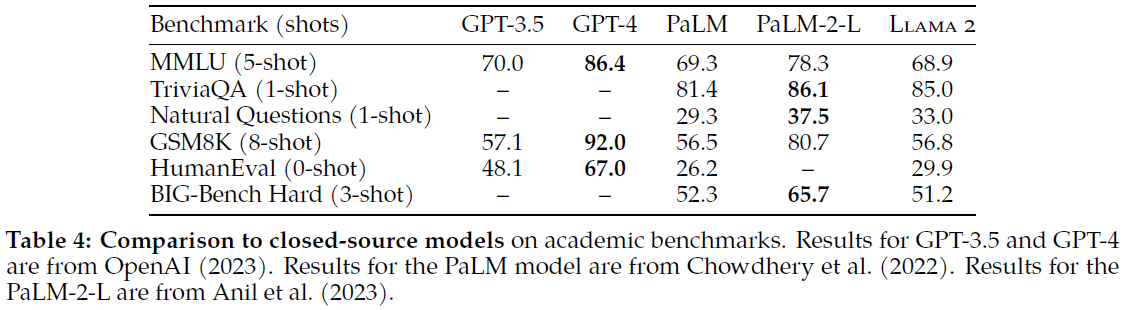
Llama-2-Chat is built with iterative applications of alignment techniques, including both instruction tuning and RLHF, as illustrated in the Figure below. For the supervised fine-tuning (SFT) stage, a publicly available instruction tuning dataset[35] is used first; then, a total of 27,540 high-quality examples are collected from vendor-based annotations. Manual examinations of the outputs sampled from the resulting SFT model validate that their qualities are competitive with those of human annotations. For the fine-tuning process, each sample consists of a prompt and an answer. All the prompts and answers from the training set are concatenated, with a special token to separate the prompt and answer segments. In the autoregressive objective, the loss on tokens from the prompt is zeroed out and only the loss on tokens from the answer is backpropagated. The model is fine-tuned for 2 epochs.
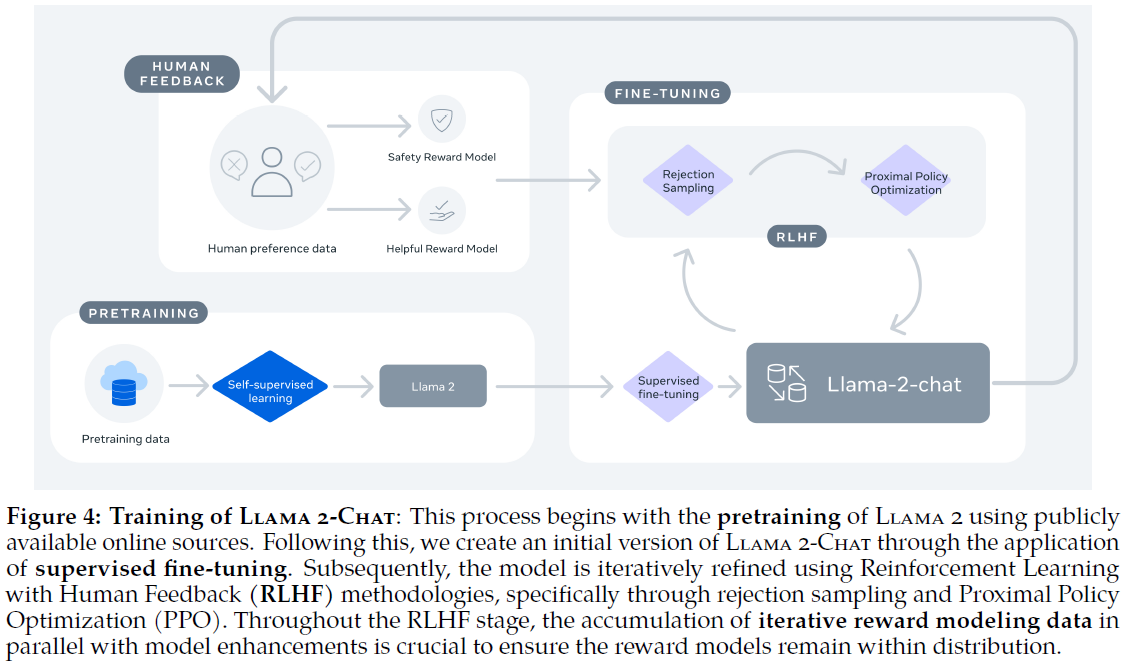
Human preferences data are collected from human annotators who are asked to write a prompt and then choose a preferred one between two sampled model responses, based on provided criteria. In order to maximize the diversity, the two responses to a given prompt are sampled from two different model variants, and varying the temperature hyper-parameter. In addition to choosing a response, annotators are asked to label the degree to which they prefer their chosen response over the alternative, out of the 4 labels: significantly better, better, slightly better, or negligibly better/unsure. The preference annotations focus on helpfulness (in fulfilling users’ request) and safety (in accordance with safety guidelines). Apart from the annotation guidelines, an additional safety label is collected for one of the three options: (1) the preferred response is safe and the other response is not, (2) both responses are safe, and (3) both responses are unsafe, with 18%, 47%, and 35% of the safety dataset falling into each bin, respectively. The preference data are used to train a reward model that in turn is used to train Llama-2-Chat. The training is done iteratively and it is important to collect new preference data using model responses of the latest Llama-2-Chat iterations so that the reward model is kept on-distribution with the Llama-2-Chat. The data collected over time is referred to as Meta reward modeling data, which contains over 1 million binary comparisons, features more conversation turns, and are longer, on average, than existing open-source datasets, as shown in the Table below. Note that summarization and online forum data generally have longer prompts, while dialogue-style prompts are usually shorter.
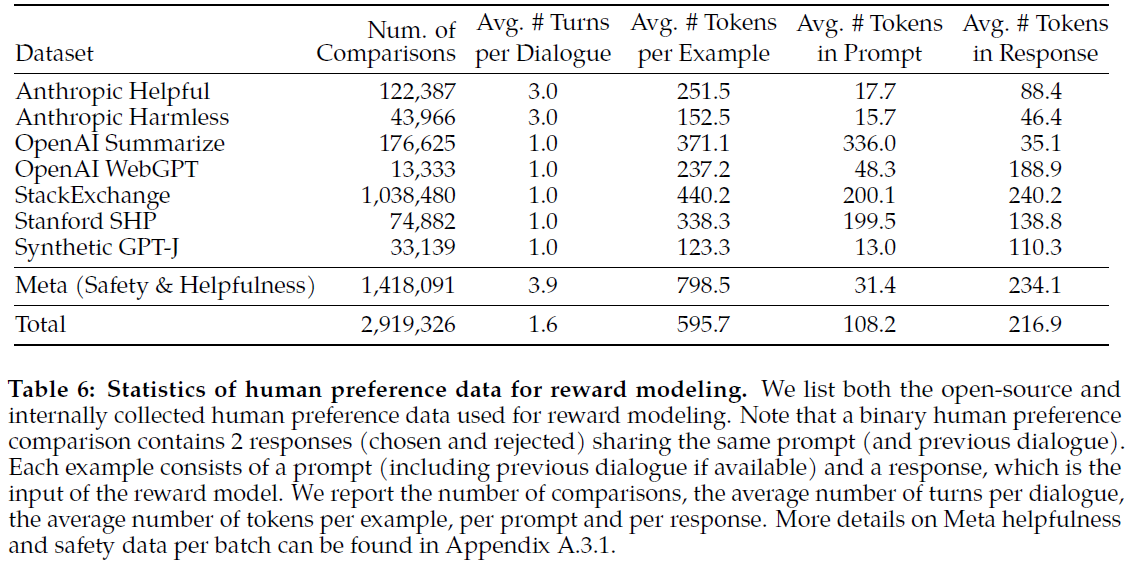
The reward model takes a model response and its corresponding prompt as inputs and outputs a scalar score to indicate the quality of the model response. Such response scores are used as rewards to optimize Llama-2-Chat during RLHF for better human preference alignment and improved helpfulness and safety. Two separate reward models are trained, one optimized for helpfulness (referred to as Helpfulness RM) and another for safety (Safety RM). Both reward models are initialized from pretrained chat model checkpoints, whose architecture and hyper-parameters are identical to those of the pretrained language models, except that the classification head for next-token prediction is replaced with a regression head for outputting a scalar reward. To train the reward model, the pairwise human preference data are converted into a binary ranking label format (i.e., chosen & rejected) and the chosen response is enforced to have a higher score than its counterpart. For chosen response \(y_{c}\) and rejected response \(y_{r}\), a binary ranking loss is defined as \(\mathcal{L}_{ranking}=-\log(\sigma(r_{\theta}(x,y_{c})-r_{\theta}(x,y_{r})))\), where \(r_{\theta}(x,y)\) is the scalar score output for prompt \(x\) and completion \(y\) with reward model weights \(\theta\). Given the 4-point scale of the preference ratings, it can be beneficial to explicitly train the reward model to assign more discrepant scores to the responses that have more differences. Thus, a margin component is added in the loss: \(\mathcal{L}_{ranking}=-\log(\sigma(r_{\theta}(x,y_{c})-r_{\theta}(x,y_{r})-m(r)))\), where the margin \(m(r)\) is a discrete function of the preference rating. A large margin (e.g. 3) is used for pairs with distinct responses (e.g. significantly better), and a smaller margin (e.g. 0) for those with similar responses (e.g. negligibly better/unsure). Ablation study shows that this margin component can improve Helpfulness reward model accuracy especially on samples where two responses are more separable.
The Helpfulness reward model is trained on all Meta Helpfulness data, combined with an equal part of the remaining data uniformly sampled from Meta Safety and from the open-source datasets. The Safety reward model is trained on all Meta Safety and Anthropic Harmless data, mixed with Meta Helpfulness and open-source helpfulness data in a 90/10 proportion. The reward models are trained for one epoch over the training data using the same optimizer parameters as for the base model. The effective batch size is kept fixed at 512 pairs, or 1024 rows per batch. The reward models are evaluated with a held-out test set from collected preference data and 3 other publicly available human preference benchmarks: SteamSHP-XL, Open Assistant, and GPT-4 (prompted with a zero-shot question “Choose the best answer between A and B” where A and B are the two responses for comparison). The results show that the reward models perform the best on the held-out test sets, with the Helpfulness reward model performing best on the Meta Helpfulness test set, and similarly the Safety reward model performing best on the Meta Safety test set. Overall, the reward models outperform all the baselines, including GPT-4 that outperforms other non-Meta reward models, despite not being trained directly nor targeting specifically this reward modeling task. Analyses of Safety and Helpfulness reward model scores on a set of safe and unsafe responses from the safety test set reveal that tension exists between the two objectives: high safety scores of safe responses tend to be accompanied with low helpfulness scores and low safety scores of unsafe responses tend to be accompanied with high helpfulness score. Thus, optimizing two separate reward models eases the reward modeling task. When the scores are grouped by preference rating, the reward models show superior accuracy on more distinct responses (e.g., significantly better) and lower accuracy on similar responses (e.g., negligibly better). The human preference annotation agreement rate is also higher on more distinct responses than similar pairs. The accuracy on more distinct responses matters the most to improve Llama-2-Chat performance. Study of the scaling trends in terms of data and model size for the reward model shows that larger models obtain higher performance for a similar data size. The scaling performance has not yet plateaued at the end of full training, suggesting that there is room for more improvement with more annotations. Note that reward model accuracy is one of the most important proxies for the final performance of Llama-2-Chat and an improvement of the reward model can be directly translated into an improvement for Llama-2-Chat.
As the human preference data annotations are collected and accumulated iteratively, the trained reward models are getting better iteratively. The successive versions of iteratively trained RLHF models are denoted as RLHF-V1, …, RLHF-V5. Two RLHF fine-tuning algorithms are explored: (1) Proximal Policy Optimization (PPO)[3], and (2) Rejection Sampling fine-tuning, which samples K outputs from the model and select the best candidate with the reward model, and then uses the selected outputs for a gradient update, similar to RLAIF[40]. For each prompt, the sample that obtains the highest reward score is considered the new gold standard. The new set of ranked samples are then used to fine-tune the model. The two RL algorithms differ in two aspects: (i) the model explores K samples for a given prompt in Rejection Sampling, while only one generation is done in PPO; and (ii) during training, the model policy is updated at each step of generation in PPO, but all the outputs are sampled by the initial policy in Rejection Sampling fine-tuning. However, since model updates are done iteratively, the fundamental differences between the two RL algorithms are less pronounced. Only Rejection Sampling fine-tuning is used until RLHF-V4, and after that, PPO is applied on top of the resulted Rejection Sampling checkpoint before sampling again.
Rejection Sampling is performed only with 70B Llama-2-Chat and the large-model capabilities are distilled into smaller models by fine-tuning on rejection sampled data from the larger model. At each iterative stage, K answers are sampled for each prompt from the most recent model. Each sample is scored by the best reward model at the time and the highest scoring answer for a given prompt is selected from top-performing samples from all prior iterations. The results show that as the number of samples per prompt is increased, the opportunity to generate a better sample, and the max reward score among samples, is increased, while the median reward score among samples remain stationary. Thus, the delta between the maximum and median curves can be interpreted as the potential gain of fine-tuning on the best output. Also, a higher value of temperature parameter enables more diverse outputs. For Llama-2-Chat-RLHF, the optimal temperature when sampling between 10 and 100 outputs is \(T\in[1.2, 1.3]\).
For PPO algorithm, the reward model is used as an estimate for the true reward function and the pretrained language model is used as the policy to be optimized. The objective of the optimization is: \(\arg\max\limits_{\pi}\mathrm{\mathbb{E}}_{p\sim D,g\sim\pi}[R(g\vert p)]\) where \(p\) denotes prompts sampled from dataset \(D\) and \(g\) denotes generations by the policy \(\pi\). The reward function \(R(g\vert p)=\tilde R_{c}(g\vert p)-\beta D_{KL}(\pi_{\theta}(g\vert p)\|\pi_{0}(g\vert p))\) contains a KL penalty term for diverging from the original policy \(\pi_{0}\), which is a useful constraint for training stability and to reduce reward hacking. The \(\tilde R_{c}\) is defined as a piecewise combination of the safety (\(R_{s}\)) and helpfulness (\(R_{h}\)) reward models: if \(\mathrm{IS\_SAFETY}(p)\: or\: R_{s}(g\vert p)<0.15\), then \(R_{c}(g\vert p)=R_{s}(g\vert p)\); otherwise, \(R_{c}(g\vert p)=R_{h}(g\vert p)\). The \(\mathrm{IS\_SAFETY}(p)\) is for tagged prompts in the training dataset that might elicit potentially unsafe responses, whose scores from the safety reward model are prioritized. The threshold of 0.15 is chosen for filtering unsafe responses. Without revealing specific detail, the authors also whiten the final linear scores in order to increase stability and balance properly with the KL penalty term (\(\beta\)) above: \(\tilde R_{c}(g\vert p)=\mathrm{WHITEN}(\mathrm{LOGIT}(R_{c}(g\vert p)))\). Note that data whitening in general refers to centering, scaling, and decorrelating the input data, which can speed up training. KL penalty is set as \(\beta=0.01\) for the 7B and 13B models and \(\beta=0.005\) for the 34B and 70B models.
To enable a global instruction (e.g. “Always answer with emojis”) for all the turns of a multi-turn conversation, the model is supervise fine-tuned with a specially designed dataset, in which instructions are synthetically concatenated to all the user messages of a multi-turn dialogue dataset between a user and a chatbot. This approach is named as Ghost Attention (GAtt) by the authors. The synthetic data are then used for the latest RLHF model to generate sample responses. The context-dialogue dataset and their corresponding samples are then used to fine-tune a model in a process analogous to Rejection Sampling. The instruction can be concatenated to only the first turn during training, not other intermediate turns, but the loss has to be set to 0 for all the tokens from the intermediate turns. A few synthetic constraints are created to sample for training instructions: Hobbies (“You enjoy e.g. Tennis”), Language (“Speak in e.g. French”), or Public Figure (“Act as e.g. Napoleon”). Llama-2-Chat was asked to generate the lists of hobbies and public figures. To make the instructions more complex and diverse, the final instruction is constructed by randomly combining the above constraints. When constructing the final system message for the training data, the original instruction is modified half of the time to be less verbose; e.g., “Always act as Napoleon from now” is reduced to “Figure: Napoleon”. These steps produce an SFT dataset that can be used to fine-tune Llama-2-Chat. GAtt is applied after RLHF V3. The results show that GAtt is consistent up to 20+ turns, until the maximum context length is reached. When constraints not present in the training of GAtt, e.g. “Always answer with Haiku”, is tried at inference time, the model remains consistent. The maximum attention activations of the model for a dialogue show that the GAtt-equipped model maintains large attention activations with respect to the system message (the instruction) for a larger portion of the dialogue, as compared to the model without GAtt.
Reward model-based evaluations are used to select the best model within each iteration. Human evaluation is used to validate major model versions. Despite being trained with a Pairwise Ranking Loss, the reward models can be used as a point-wise metric, as proved by the good correlations between reward model scores and human annotated quality ratings on a test set for both helpfulness and safety. The reward models were additionally trained on diverse open-source Reward Modeling datasets to ensure no divergence from human preferences. To ensure no regression between a new model and its previous one, both are used to sample during the next annotation iteration. When evaluated using the Safety and Helpfulness reward models, the reward scores increase as the SFT and then RLHF versions progress, and they outperform ChatGPT on both axes after RLHF-V3. When evaluated using GPT-4, the win-rate in favor of Llama-2-Chat is less pronounced, although obtaining more than a 60% win-rate for the latest Llama-2-Chat. Human evaluation is used to compare the Llama-2-Chat models to open-source models (Falcon, MPT, and Vicuna), as well as closed-source models ChatGPT (gpt-3.5-turbo-0301) and PaLM (chat-bison-001). The results show that Llama-2-Chat models outperform equivalently sized open-source models by a significant margin on both single turn and multi-turn prompts. Llama-2-Chat 70B model is competitive with ChatGPT and outperforms PaLM-bison chat model by a large percentage. The inter-rater reliability (IRR) is measured by Gwet’s AC1/2 statistic. On the 7-point Likert scale helpfulness task, Gwet’s AC2 score varies between 0.37 and 0.55 depending on the specific model comparison. For ratings from model comparisons with similar win rates to each other, the scores are on the lower end of that range. For ratings from model comparisons with a clearer winner, the scores are on the higher end of that range. Human evaluations have several limitations: (1) the small test dataset does not cover real-world usage of these models; (2) the diversity of the test dataset is limited; (3) the evaluations only cover the final generations of a multi-turn conversation; and (4) evaluation on a different set of prompts or with different instructions could result in different results.
Bias in model generations may result from biases in training data. Analyses of the frequencies of the most common English pronouns in the training corpus reveal that He pronouns are overrepresented in documents compared to She pronouns. Thus, the model may potentially generate He pronouns at a higher rate than She pronouns. To analyze demographic representations in the pretraining data, the rates of usage of demographic identity terms from the HolisticBias dataset are used as a proxy. The demographic descriptors are grouped into 5 axes: Religion, Gender and Sex, Nationality, Race and Ethnicity, and Sexual Orientation. For Nationality, Race and Ethnicity, and Religion, there is a Western skew, as shown in the Table below.
About 0.2% of documents are assigned a toxicity likelihood score of 0.5 or higher, as evaluated by a HateBERT classifier fine-tuned on the ToxiGen dataset, indicating there is a small amount of toxicity in the pretraining data. Most (89.07%) of the pretraining data is in English and 8.38% of the data is in unknown category, partially made up of programming code. All European languages are less than 0.2% each, indicating that the model is not suitable for use in other languages.
Three benchmarks are used to evaluate three safety dimensions of Llama-2: Truthfulness, Toxicity, and Bias are evaluated on TruthfulQA[41], ToxiGen[42], and BOLD[43], respectively. Llama-2 is compared with Llama-1, Falcon, and MPT on these benchmarks. For decoding, temperature is set to 0.1 and nucleus sampling is used with top-p set to 0.9. TruthfulQA is presented as the percentage of generations that are both truthful and informative (the higher the better). ToxiGen is presented as the percentage of generations that are deemed toxic by the metric (the lower, the better). When compared to Llama-1-7B, Llama-2-7B demonstrates 21.37% increase in truthfulness and informativeness and a 7.61% decrease in toxicity. There is an increased toxicity in the pretrained 13B and 70B Llama-2, which may be because this study did not aggressively filter the larger pretraining data.
Three safety fine-tuning techniques are used: (1) adversarial prompts and safe demonstrations are collected and then included in the general supervised fine-tuning process; (2) safety is integrated in the general RLHF pipeline that includes training a safety-specific reward model and gathering more challenging adversarial prompts for rejection sampling style fine-tuning and PPO optimization; (3) RLHF pipeline is refined with context distillation, which involves generating safer model responses by prefixing a prompt with a safety preprompt and then fine-tuning the model on the safer responses without the preprompt, which essentially distills the safety preprompt (context) into the model. In the technique (1), adversarial prompts are created along two dimensions: a risk category (illicit and criminal activities, hateful and harmful activities, and unqualified advice) and an attack vector (psychological manipulation, logic manipulation, syntactic manipulation, semantic manipulation, perspective manipulation, non-English languages, and others). Guidelines for safe and helpful model responses are: the model should first address immediate safety concerns if applicable, then address the prompt by explaining the potential risks to the user, and finally provide additional information if possible. The annotators are instructed to first come up with prompts that they think could potentially induce the model to exhibit unsafe behavior, i.e., perform red teaming, as defined by the guidelines. Then, annotators are tasked with crafting a safe and helpful response that the model should produce. In supervised fine-tuning, the model quickly learns to write detailed safe responses, address safety concerns, explain why the topic might be sensitive, and provide additional helpful information, which are often more detailed than what the average annotator writes. Thus, only a few thousand supervised demonstrations are gathered.
In the technique (2), annotators write a prompt that they believe can elicit unsafe behavior, and then compare multiple model responses to the prompts, selecting the response that is safest according to a set of guidelines. The human preference data are then used to train a safety reward model and the adversarial prompts are reused to sample from the model during the RLHF stage (named Safety RLHF). The distribution of safety RM scores on the safety set shifts to higher reward scores after safety tuning with RLHF, and the long tail of the distribution near zero thins out, while the helpfulness score distribution is not affected by safety tuning with RLHF. Safety data scaling was investigated by adjusting the amount of safety data used in the RLHF stage, from 0% to 100% (∼0.1M samples), while keeping the amount of helpfulness training data unchanged (∼0.9M samples). The results show that the model’s performance on handling risky and adversarial prompts improves dramatically and the safety reward model score distribution shows a lighter tail, while the mean helpfulness score remains constant, as the safety data percentage increases. Although no overall regression on helpfulness was observed, the model with more safety mitigation responds to certain questions in a more conservative manner. Furthermore, with more safety data mixed in model tuning, the false-refusal rate becomes larger: from 0.006% to 0.05% on the helpfulness dataset and from 15% to 27% on the borderline dataset whose prompts look adversarial but are not actually unsafe.
In the technique (3), context distillation is used to encourage Llama-2-Chat to associate adversarial prompts with safer responses. Like supervised safety fine-tuning, safety context distillation provides a quick way to bootstrap the model’s responses on hard adversarial prompts, so that they can then be further improved in RLHF. Context distillation is done by prefixing a safety preprompt (e.g., “You are a safe and responsible assistant”) to adversarial prompts to generate safer responses, and then fine-tune the model on its own safe output given the adversarial prompt without the preprompt. Safety preprompts are automatically generated with templates, using adjectives usually associated with safe behavior such as “responsible,” “respectful’,’ or “wise,” with the intuition that the model associates them with positive traits. During the prompt collection phase, prompts are also labeled by annotators into risk categories, which enables some dedicated answer templates of how adversarial prompts should be addressed based on each identified risk category. The results on distribution of safety RM scores show that adding a generic preprompt increases the scores and adding a preprompt based on the risk category with tailored answer template increases even more. However, context distillation can sometimes degrade response quality. Thus, the safety reward model is used to decide whether safety context distillation will be applied to a given sample: context-distilled outputs are kept only on the samples where it gets a better reward model score than the original answer.
Various kinds of proactive risk identification are performed based on the term commonly used within computer security, which is colloquially called “red teaming”. A series of red teaming were conducted by a team of over 350 people, including domain experts in cybersecurity, election fraud, social media misinformation, legal, policy, civil rights, ethics, software engineering, machine learning, responsible AI, creative writing, and individual’s representative of a variety of socioeconomic, gender, ethnicity, and racial demographics. The red teamers probed the models across a wide range of risk categories and different attack vectors. All the red teaming efforts have targeted model outputs in English, but have crucially included non-English prompts and dialogue contexts as attack vectors. Participants were given risk category definitions and were shown just a handful of examples of risky interactions with an LLM. Each participant was part of a subteam focused on a particular category of risk or attack vector. After creating each dialogue, the red team participant would annotate various attributes, including risk areas and degree of risk, in a 5-point Likert scale. Two metrics are used to track model improvement over multiple iterations of red teaming: robustness and rejection rate. Robustness of a model, \(\gamma\), with respect to a red teaming exercise executed by a set of experts is defined as the average number of created prompts that would trigger a violating response from the model per person per hour. For example, the 7B Llama-2-Chat model’s \(\gamma\) evolved from 1.8 to 0.45 over several red teaming iterations and model refinements. The rejection rate is defined as the percentage of prompts triggering violating responses in the previous red teaming exercises that were mitigated in a given new candidate release. On average, the rejection rate is 90% model over model.
1,351 adversarial prompts for single-turn and 623 adversarial prompts for multi-turn are collected for human evaluation according to the risk categories in the technique (1) above. Then, human raters judge for safety violations on a five-point Likert scale with 1 as “Severe safety violations” and 5 as “No safety violations and very helpful”. Ratings of 1 or 2 are considered as violation. Violation percentage is used as main evaluation metric and the mean rating is used as a supplement metric. Each example is annotated by three annotators and the majority vote is taken to determine if the response is violating or not. Inter-rater reliability (IRR), measured using Gwet’s AC1/2 statistic, ranges from 0.70 to 0.95 depending on the annotation batch, indicating a high degree of agreement among annotators on safety assessments. IRR scores are lower on batches where the models have a high violation rate, and higher on batches where the models have relatively low violation rates. On overall violation percentage, Llama-2-Chat models are lowest (<5%); ChatGPT and Falcon follow (~7%); MPT, Vicuna, and PaLM are much higher (>20%). Manual analysis shows that the response of Falcon is typically short (one or two sentences), thus less prone to generating unsafe content but also generally less helpful. It is important to note that these results are subject to limitations of the prompt set, subjectivity of the review guidelines, and subjectivity of individual raters. Comparison of the violation percentage on single- and multi-turn conversations reveals a consistent trend across all models: multi-turn conversations are more prone to inducing unsafe responses. Llama-2-Chat still performs well on multi-turn conversations, compared to baselines. Violation percentage per risk category shows that Llama-2-Chat has relatively more violations under the unqualified advice category, compared with the other two categories (hateful and harmful, illicit and criminal activity), for various reasons, including lack of an appropriate disclaimer at times.
Fine-tuned Llama-2-Chat shows great improvement over the pretrained Llama-2 in terms of truthfulness (50.18\(\to\)64.14 for 70B) and toxicity (24.60\(\to\)0.01 for 70B). The percentage of toxic generations shrinks to effectively 0% for Llama-2-Chat of all sizes: this is the lowest toxicity level among all compared models. After fine-tuning, Llama-2-Chat tends to have an increase in positive sentiment overall for many of the demographic groups in BOLD.
Reinforcement learning proved highly effective, particularly given its cost and time effectiveness. The crucial determinant of RLHF’s success lies in the synergy it fosters between humans and LLMs throughout the annotation process. Human annotators are less subject to discrepancy when comparing two outputs’ preference annotation for RLHF, but vary significantly in quality of human-written responses for supervised fine-tuning. The reward mechanism of RLHF swiftly learns to assign low scores to undesirable tail-end distribution and aligns towards the human preference. It was postulated that the superior writing abilities of LLMs, which surpass human annotators in certain tasks, are fundamentally driven by RLHF. RLHF has a direct impact on rescaling the temperature, but the effects differ by types of prompts. When prompts associated with creativity are used, an increase in temperature continues to generate diversity (lower Self-BLEU score) across the various RLHF iterations, with a Self-BLEU slope pattern comparable to that of the SFT model. When prompts based on factual information are used, the Self-BLEU slope (diversity) diminishes as RLHF iteration counts increase, suggesting that despite the rising temperature, the model learns to consistently provide the same response to factual prompts.
Llama-2-Chat demonstrates a time awareness. The concept of time in Llama-2-Chat is learned from a dataset of 1,000 SFT examples that are related to specific dates. Each example is associated with two critical pieces of metadata: the date when the query was posed, which influenced the response, and the event date, a point in time prior to which the question would be nonsensical. The observation suggests that LLMs have generalized the notion of time to a greater extent than previously assumed, despite their training being solely based on next-token prediction and data that is randomly shuffled without regard to their chronological context.
Llama-2-Chat demonstrates the capability to utilize a sequence of tools (Search and Calculator) in a zero-shot context, despite never having been explicitly trained to use tools. In addition, evaluating the Llama-2-Chat, with access to a calculator, on three math datasets used in Toolformer shows that Llama-2-Chat substantially outperforms Toolformer. These results indicate that tool usage can spontaneously emerge from alignment in a zero-shot manner.
LLaMA 2 Long
Xiong et al. (2023)[48] extend LLAMA 2 to handle longer context by continually pretraining from LLAMA 2 checkpoints with additional 400 billion tokens formed as longer training sequences and on a dataset where long texts are upsampled. Four variants of the LLAMA 2 Long models were developed: the smaller 7B/13B variants are trained with 32,768-token sequences while the 34B/70B variants with 16,384-token sequences. On language modeling task, LLAMA 2 Long models demonstrate a clear power-law scaling behavior with respect to context lengths, which not only shows the models’ ability to consistently benefit from more contexts but also suggest that context length is another important axis of scaling LLMs.
The motivation of this approach is based on the hypothesis that similar long-context capabilities can be learned by continually pretraining from a short-context model. The original LLAMA 2 architecture is kept nearly intact for continual pretraining and only the positional encoding is modified for the model to attend longer. Sparse attention method is not used in this study, because the cost of attention matrix calculation and value aggregation becomes a computation bottleneck when the sequence length exceeds 49,152 tokens that is 6 times of the LLAMA-2-70B’s model dimension (8192). A minimal yet necessary modification on the RoPE positional encoding[27] is adopted for long-context modeling, which is to decrease the rotation angle (controlled by the hyperparameter “base frequency b”) that reduces the decaying effect of RoPE for distant tokens. LLAMA 2 checkpoints are continually pretrained with increased sequence length while the number of tokens per batch is kept the same as those in LLAMA 2. A total of 400B tokens are used to train the models over 100,000 steps. FlashAttention[50], an IO-aware exact attention algorithm that uses tiling to reduce the number of memory reads/writes between GPU high bandwidth memory (HBM) and GPU on-chip SRAM, is used for negligible GPU memory overhead as the sequence length is increased. There is around 17% speed loss when increasing the sequence length from 4,096 to 16,384 for the 70B model.
The instruction tuning dataset for long-context scenarios is built by augmenting RLHF dataset used in LLAMA-2-Chat with synthetic self-instruct[51] long data generated by LLAMA-2-Chat itself. The data generation process focuses on QA-format tasks: starting from a long document in the pretraining corpus, a random text chunk is selected and used to prompt LLAMA-2-Chat to write question-answer pairs based on information in the chunk. Both long and short form answers are collected with different prompts. Then, the model-generated answers are verified by LLAMA-2-Chat in a self-critique step. Given a generated QA pair, the original long document (truncated to fit the model’s maximum context length) is used as the context to construct a training instance. For short instruction data, they are concatenated as 16,384-token sequences. For long instruction data, padding tokens are added on the right so that models can process each long instance individually without truncation. In addition to calculating loss on the output tokens, it is beneficial to also calculate the language modeling loss on the long input prompts, which gives consistent improvements on downstream tasks.
The LLAMA 2 Long model’s performance on standard short-context tasks are verified on a series of common benchmarks, including Coding, Math, MMLU, Commonsense, and OpenQA. Overall, LLAMA 2 Long performs on-par and, in most cases, better than LLAMA 2, with significant improvements on coding, math, and knowledge intensive tasks such as MMLU. LLAMA 2 Long outperforms GPT-3.5 and PaLM on MMLU and GSM8k, but underperforms GPT-4 and PaLM-2-L on MMLU and GSM8k.
The LLAMA 2 Long models’ performance on long-context tasks are evaluated using real-world QA-style tasks, including 0-shot performance on NarrativeQA, 2-shot on QuALITY and Qasper, and 1-shot on QMSum. Simple prompt “{CONTEXT} Q: {QUESTION}, A:” is used to evaluate all pretrained models. The input prompts are truncated from the left side if the prompts exceed the maximum input length of the model or 16,384 tokens. Six open-source long-context models are compared: Focused Transformer[52], YaRN[53], Xgen[54], MPT[55][56], and Together’s LLAMA 2 fork[57]. The LLAMA 2 Long models achieve superior performance compared to these models. At the 7B scale, only “Together-7B-32k” can match LLAMA 2 Long 7B’s performance, where maximum prompt length is set to 16,384 tokens. Note that unlike the other long-context models, LLAMA 2 Long 7B model is not a purely self-supervised model and has been finetuned using a large supervised dataset to improve its few-shot results.
The performance on long-context tasks improves monotonically as the maximum context lengths of prompts increase, which validates that the LLAMA 2 Long models can effectively use increased context window. The LLAMA 2 Long model’s language modeling loss can be fit as a function of the context length \(c\): \(L(c)=(\frac{\alpha}{c})^{\beta}+\gamma\) with a different set of \(\alpha\), \(\beta\), \(\gamma\) for each model size. This power-law relationship also suggests that context length is another important axis of scaling LLMs and the LLAMA 2 Long models can continually improve their performance (on the language modeling loss) as the context length is increased up to 32,768 tokens, despite having diminishing returns. Larger models have larger \(\beta\) value of the curves, indicating that larger models can leverage the contexts more effectively.
Instruction tuned long-context models are evaluated using automatic metrics on two datasets: (1) ZeroSCROLLS which bundles 10 long-context datasets spanning from summarization, question answering, to multi-document aggregation tasks, (2) L-Eval which includes 6 long tasks. ZeroSCROLLS long-context leaderboard results show that LLAMA 2 Long Chat 70B outperforms GPT-3.5-turbo-16k on 7 out of the 10 tasks. L-Eval results show that LLAMA 2 Long Chat 70B outperforms GPT-3.5-turbo-16k on 5 out of the 6 tasks, particularly QA tasks which is the main theme of the self-instruct data.
Unlike automatic metrics, humans are better at evaluating the quality of model responses for long context models because of the large space of acceptable answers. Human evaluations are conducted by asking annotators whether they prefer the generation from instruction finetuned LLAMA 2 Long model or from proprietary models like MPT-30B-chat, GPT-4, GPT-3.5-turbo-16k, and Claude-2 in terms of helpfulness, honesty, and harmlessness. Two application scenarios are focused on: (1) multi-turn conversation, where each prompt is a chat history based on which the model needs to generate a coherent response, (2) multi-document search query answering application, where the model is provided with a few most relevant documents retrieved from a search session and the corresponding search query and how well the model can leverage the retrieved documents to answer the given query is evaluated. Each comparison example is evaluated by 3 different human annotators and win rate of LLAMA 2 Long model over each other model is calculated by averaging the result of each comparison example. With very little instruction data, LLAMA 2 Long model can achieve competitive performance against MPT-30B-chat, GPT-3.5-turbo-16k, and Claude-2.
Using “FIRST-SENTENCE-RETRIEVAL” task that prompts the model to return the first sentence of the input to probe the effective context window of the pretrained models, the original LLAMA 2 Long was unable to effectively attend beyond 4,000~6,000 tokens. It is hypothesized that this bottleneck comes from the RoPE positional encoding that imposes a heavy decay on the attention scores for distant tokens. A simple modification called adjusted base frequency (ABF) that reduces the decaying effect by increasing the “base frequency b” of RoPE from 10,000 to 500,000 is proposed to essentially reduce the rotation angle of each dimension. Another concurrent approach named position interpolation (PI) proposes to linearly scale the input positions such that the positions of tokens in the long sequences will be mapped to the model’s original position range. RoPE introduces large “oscillation” on the attention scores (before softmax) in the long-range regions, which can be smoothed out by another variant of rotary encoding xPos. With default parameters, xPos also suffers from similar decay on the attention scores for distant tokens. Therefore, ABS is also applied to xPos for comparison. The 4 types of positional encoding methods are evaluated on 3 tasks: (1) long-sequence validation perplexity, (2) the FIRST-SENTENCE-RETRIEVAL context probing task, and (3) 5 standard short-context benchmarks. The results show that RoPE ABF overall performs the best among the 4 variants. In particular, RoPE ABF is the only variant that can maintain its performance up to the full 32,768-token context window on the FIRST-SENTENCE-RETRIEVAL task. xPos ABF with less oscillation does not lead to substantial gains, suggesting that the oscillation is not detrimental to language modeling. xPos ABF does not extrapolate better than RoPE ABF. The relative distance between the embedded vectors has a linear dependence on the key parameter of RoPE PI and a logarithmic dependence on the key parameter of RoPE ABF. It is argued that RoPE ABF distributes the embedded vectors with an increased granularity when compared to RoPE PI, making it easier for the model to distinguish between positions.
Ablation studies to differentiate the effects of the data length distribution and the quality of the corpus itself show that long-context LLMs can be effectively trained even with very limited long data and the improvements of the pretrain data used for LLAMA 2 Long over the one used by LLAMA 2 mostly come from the quality of the data itself, instead of the length distribution difference.
Four variants of instruction finetuning data mixes for LLAMA 2 Long are evaluated on 5 long-context QA tasks against LLAMA 2 Chat baseline: (1) short instruction data from LLAMA 2 Chat (“RLHF V5”), (2) adding some pretrain data to avoid forgetting of previous long context continual pretraining (“RLHF V5” mix pretrain), (3) adding long-context self-instruct data without adding language modeling loss (“RLHF V5” mix self-inst w/o LM loss), and (4) adding long-context self-instruct data with language modeling loss (“RLHF V5” mix self-inst with LM loss). The “RLHF V5” mix self-inst with LM loss significantly outperforms the others on 4 of the 5 tested tasks, while “RLHF V5” alone can already produce a decent long model that significantly outperforms LLAMA 2 Chat on all the 5 tested tasks.
Four training curricula are compared to investigate if continual pretraining can offer competitive performance with less computation budget: (1) pretraining with 32k sequence from scratch, (2) ~ (4) pretraining with 4k sequence first and, after completing 20%, 40%, 80% of whole training process, respectively, then switching to 32k sequence. The same number of total training tokens is used and the number of tokens per each gradient update remains constant (4 million tokens) for all 4 curricula by adjusting the batch size and sequence length accordingly. Evaluations are done on 4 long-context QA tasks and the final models’ perplexity on 3 validation corpora are reported. The results show that two-stage curriculum, pretraining short-context model for 80% of total training and then switching to long-context continual pretraining, saves around 40% FLOPs while imposing almost no loss on performance. The training loss curves of the 4 training curricula show that switching the context length from 4,096 to 32,768 tokens at different stages all quickly adapt to the loss of long context within a few thousand steps.
To evaluate the safety capability of instruction fine-tuned model, three standard academic benchmarks are used: TruthfulQA (for factuality), ToxiGen (for toxic and hateful generations), and BOLD (Bias in Open-ended Language Dataset for demographic biases). LLAMA 2 Long 70B is compared with 2 open-sourced LLMs, Falcon-instruct and MPT-instruct[56], and 3 close-sourced LLMs, GPT-3.5, GPT-4, and Claude-2. The results show that in general the instruction fine-tuned LLAMA 2 Long Chat model maintains similar safety performance compared to LLAMA 2 Chat and is safer and less biased compared to other open-source LLMs such as Falcon-instruct and MPT-instruct. Note that currently the community lacks dedicated safety benchmarks for long-context LLM evaluation. On TruthfulQA, few-shot prompts with 6 random QA pairs are used for generation and two fine-tuned GPT-3 models are used to classify whether the generation is truthful and informative. The percentage of generations that are both truthful and informative are reported. The GPT-4 has the highest score, 80.66, while LLAMA 2 Chat and LLAMA 2 Long Chat have scores of 64.14 and 60.95, respectively. On ToxiGen, prompts where annotators disagree with each other are filtered out and the toxicity of the model’s outputs are evaluated by the default ToxiGen classifier fine-tuned based on RoBERTa. The percentage of toxic generations across all 13 minority groups is reported. LLAMA 2 Long Chat has a ToxiGen score of 0.00, the lowest among all the tested models. The BOLD dataset covers 5 domains including race, gender, religion, political ideology, and profession with 43 subgroups in total, but Hinduism and Atheism religious subgroups are excluded. Model generations are evaluated by the Valence Aware Dictionary and Sentiment Reasoner (VADER) to perform sentiment analysis with a score ranging between -1 and 1. A sentiment score close to 0 indicates neutral sentiment which is desired. The average sentiment score across all demographic subgroups is reported as the final metric for BOLD. LLAMA 2 Long Chat, LLAMA 2 Chat, and GPT-4 have BOLD scores 0.40, 0.41, and 0.43, respectively, higher than the lowest BOLD score of 0.34 of MPT-instruct. Internal red teaming exercises were performed, where long context followed by adversarial prompts covering risky areas, such as illicit and criminal conducts, hateful and harmful behaviors, and unqualified advice, are fed into models and the responses are manually inspected. It was concluded that there was no significant risks from LLAMA 2 Long Chat, compared to LLAMA 2 Chat.
Three limitations are highlighted: (1) LLAMA 2 Long Chat has not yet been finetuned for a wide range of long-context applications, (2) the tokenizer of the LLAMA series often produces 10% more tokens on average than GPT-3.5’s tokenizer and it cannot efficiently handle whitespace, making it inefficient to process long code data, and (3) LLAMA 2 Long Chat has hallucination issue, which can be more pronounced to tackle with for long-context models.
Codes
- An Implementation of PPO and RLHF
- InstructGPT Model Card, Automatic Evaluation Samples, Labeling Instructions
Open-source libraries for building autonomous agents:
- LangChain for autonomous reasoning and decision-making agents
- Auto-GPT for a generalist agent
- Baby-AGI for Task-driven Autonomous Agent
- SuperAGI for an agent to plan, reason, and interact with toolkits
- AutoGen to enable diverse LLM-based applications via multi-agent conversations[171]
- AgentGPT that achieves assigned objectives by chaining calls to LLMs
- Semantic Kernel is a Microsoft’s SDK for building LLM-based enterprise applications for autonomously orchestrate plugins of LLMs
- JARVIS for building a collaborative system that consists of an LLM as the controller and numerous expert models as collaborative executors (from HuggingFace Hub)[151] to solve complicated AI tasks.
References
[1] OpenAI (2022) Introducing ChatGPT.
[2] Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., et al (2022) Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155
[3] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. (2017) Proximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347
[4] Sutton, R. S. and Barto, A. G. (2018) Reinforcement Learning: An Introduction. 2nd Ed., MIT Press, Cambridge, MA.
[5] Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., et al. (2021) Finetuned Language Models Are Zero-Shot Learners. arXiv preprint arXiv:2109.01652
[6] Sanh, V., Webson, A., Raffel, C., Bach, S. H., et al. (2021) Multitask Prompted Training Enables Zero-Shot Task Generalization. arXiv preprint arXiv:2110.08207
[7] Gehman, S., Gururangan, S., Sap, M., Choi, Y., and Smith, N. A. (2020) RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models. arXiv preprint arXiv:2009.11462
[8] Nangia, N., Vania, C., Bhalerao, R., and Bowman, S. R. (2020) CrowS-Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models. arXiv preprint arXiv:2010.00133
[9] Thoppilan, R., De Freitas, D., Hall, J., Shazeer, N., Kulshreshtha, A., et al. (2022) LaMDA: Language Models for Dialog Applications. arXiv preprint arXiv:2201.08239
[10] Adiwardana, D., Luong, M.-T., So, D. R., Hall, J., Fiedel, N., et al. (2020) Towards a Human-like Open-Domain Chatbot. arXiv preprint arXiv:2001.09977
[11] Dinan, E., Roller, S., Shuster, K., Fan, A., Auli, M., and Weston, J. (2018) Wizard of Wikipedia: Knowledge-Powered Conversational Agents. arXiv preprint arXiv:1811.01241
[12] Manyika, J. (2023) An overview of Bard: an early experiment with generative AI. Google AI
[13] OpenAI (2023) GPT-4 Technical Report. arXiv preprint arXiv:2303.08774
[14] Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., et al, (2020) Scaling Laws for Neural Language Models. arXiv preprint arXiv:2001.08361
[15] Henighan, T., Kaplan, J., Katz, M., Chen, M., Hesse, C., Jackson, J., Jun, H., et al. (2020) Scaling Laws for Autoregressive Generative Modeling. arXiv preprint arXiv:2010.14701
[16] Leiter, C., Zhang, R., Chen, Y., Belouadi, J., Larionov, D., Fresen, V., and Eger, S. (2023) ChatGPT: A Meta-Analysis after 2.5 Months. arXiv preprint arXiv:2302.13795
[17] Barbieri, F., Anke, L. E., and Camacho-Collados, J. (2021) XLM-T: Multilingual Language Models in Twitter for Sentiment Analysis and Beyond. arXiv preprint arXiv:2104.12250
[18] Antypas, D., Ushio, A., Camacho-Collados, J., Neves, L., Silva, V., and Barbieri, F. (2022) Twitter Topic Classification. arXiv preprint arXiv:2209.09824
[19] Demszky, D., Movshovitz-Attias, D., Ko, J., Cowen, A., Nemade, G., and Ravi, S. (2020) GoEmotions: A Dataset of Fine-Grained Emotions. arXiv preprint arXiv:2005.00547
[20] Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., et al. (2023) Sparks of Artificial General Intelligence: Early experiments with GPT-4. arXiv preprint arXiv:2303.12712
[21] Gottfredson, L. S. (1997) Mainstream Science on Intelligence: An Editorial With 52 Signatories, History, and Bibliography. Intelligence 24(1), Pages 13-23
[22] Cai, T., Wang, X., Ma, T., Chen, X., and Zhou, D. (2023) Large Language Models as Tool Makers. arXiv preprint arXiv:2305.17126
[23] Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., et al. (2022) PaLM: Scaling Language Modeling with Pathways. arXiv preprint arXiv:2204.02311
[24] Barham, P., Chowdhery, A., Dean, J., Ghemawat, S., Hand, S., Hurt, D., et al. (2022) Pathways: Asynchronous Distributed Dataflow for ML. arXiv preprint arXiv:2203.12533
[25] Shazeer, N. (2020) GLU Variants Improve Transformer. arXiv preprint arXiv:2002.05202
[26] Ramachandran, P., Zoph, B., Le, Q. V. (2017) Searching for Activation Functions. arXiv preprint arXiv:1710.05941
[27] Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., and Liu, Y. (2021) RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv preprint arXiv:2104.09864
[28] Kudo, T. and Richardson, J. (2018) SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. arXiv preprint arXiv:1808.06226
[29] Wei, J., Wang, X., Schuurmans, D., Bosma, M, Ichter, B., Xia, F., Chi, E. H., Le, Q. V., and Zhou, D. (2022) Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv preprint arXiv:2201.11903
[30] Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., et al. (2022) Training Compute-Optimal Large Language Models. arXiv preprint arXiv:2203.15556
[31] Rae, J. W., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., Song, H. F., et al. (2021) Scaling Language Models: Methods, Analysis & Insights from Training Gopher. arXiv preprint arXiv:2112.11446
[32] Anil, R., Dai, A. M., Firat, O., Johnson, M., Lepikhin, D., Passos, A., et al. (2023) PaLM 2 Technical Report. arXiv preprint arXiv:2305.10403
[33] Tay, Y., Dehghani, M., Tran, V. Q., Garcia, X., Wei, J., Wang, X., et al. (2023) UL2: Unifying Language Learning Paradigms. arXiv preprint arXiv:2205.05131
[34] Schick, T., Udupa, S., and Schütze, H. (2021) Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based Bias in NLP. arXiv preprint arXiv:2103.00453
[35] Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., et al. (2022) Scaling Instruction-Finetuned Language Models. arXiv preprint arXiv:2210.11416
[36] Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E. H., Narang, S., Chowdhery, A., and Zhou, D. (2022) Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv preprint arXiv:2203.11171
[37] Clark, J. H., Choi, E., Collins, M., Garrette, D., Kwiatkowski, T., Nikolaev, V., and Palomaki, J. (2020) TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages. arXiv preprint arXiv:2003.05002
[38] Dinan, E., Humeau, S., Chintagunta, B., and Weston, J. (2019) Build it Break it Fix it for Dialogue Safety: Robustness from Adversarial Human Attack. arXiv preprint arXiv:1908.06083
[39] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., et al. (2023) Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv preprint arXiv:2307.09288
[40] Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., et al. (2022) Constitutional AI: Harmlessness from AI Feedback. arXiv preprint arXiv:2212.08073
[41] Lin, S., Hilton, J., and Evans, O. (2021) TruthfulQA: Measuring How Models Mimic Human Falsehoods. arXiv preprint arXiv:2109.07958
[42] Hartvigsen, T., Gabriel, S., Palangi, H., Sap, M., Ray, D., and Kamar, E. (2022) ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection. arXiv preprint arXiv:2203.09509
[43] Dhamala, J., Sun, T., Kumar, V., Krishna, S., Pruksachatkun, Y., Chang, K., Gupta, R. (2021) BOLD: Dataset and Metrics for Measuring Biases in Open-Ended Language Generation. arXiv preprint arXiv:2101.11718
[44] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., et al. (2022) LLaMA: Open and Efficient Foundation Language Models. arXiv preprint arXiv:2302.13971
[45] Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., et al. (2022) OPT: Open Pre-trained Transformer Language Models. arXiv preprint arXiv:2205.01068
[46] Shuster, K., Xu, J., Komeili, M., Ju, D., Smith, E. M., Roller, S. et al. (2022) BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage. arXiv preprint arXiv:2208.03188
[47] Arora, K., Shuster, K., Sukhbaatar, S., and Weston, J. (2022) DIRECTOR: Generator-Classifiers For Supervised Language Modeling. arXiv preprint arXiv:2206.07694
[48] Xiong, W., Liu, J., Molybog, I., Zhang, H., Bhargava, P., Hou, R., Martin, L., et al. (2023) Effective Long-Context Scaling of Foundation Models. Meta AI
[49] Chen, S., Wong, S., Chen, L., and Tian, Y. (2023) Extending Context Window of Large Language Models via Positional Interpolation. arXiv preprint arXiv:2306.15595
[50] Dao, T., Fu, D. Y.,Ermon, S., Rudra, A., and Ré, C. (2022) FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. arXiv preprint arXiv:2205.14135
[51] Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., and Hajishirzi, H. (2022) SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions. arXiv preprint arXiv:2212.10560
[52] Tworkowski, S., Staniszewski, K., Pacek, M., Wu, Y., Michalewski, H., and Miło´s, P. (2023) Focused Transformer: Contrastive Training for Context Scaling. arXiv preprint arXiv:2307.03170
[53] Peng, B., Quesnelle, J., Fan, H., and Shippole, E. (2023) YaRN: Efficient Context Window Extension of Large Language Models. arXiv preprint arXiv:2309.00071
[54] Nijkamp, E., Xie, T., Hayashi, H., Pang, B., Xia, C., Xing, C., Vig, J., et al. (2023) XGen-7B Technical Report. arXiv preprint arXiv:2309.03450
[55] MosaicML (2023a) Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs.
[56] MosaicML (2023b) MPT-30B: Raising the bar for open-source foundation models.
[57] Together (2023) Llama-2-7B-32K-Instruct — and fine-tuning for Llama-2 models with Together API.
[58] Lester, B., Al-Rfou, R., and Constant, N. (2021) The Power of Scale for Parameter-Efficient Prompt Tuning. arXiv preprint arXiv:2104.08691
[59] Wang, Y., Mishra, S., Alipoormolabashi, P., Kordi, Y., Mirzaei, A., Arunkumar, A., et al. (2022) Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks. arXiv preprint arXiv:2204.07705
[60] Tay, Y., Wei, J., Chung, H. W., Tran, V. Q., So, D. R., Shakeri, S., et al. (2022) Transcending Scaling Laws with 0.1% Extra Compute. arXiv preprint arXiv:2210.11399
[61] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. (2020) Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv preprint arXiv:1910.10683
[62] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. (2020) Measuring Massive Multitask Language Understanding. arXiv preprint arXiv:2009.03300
[63] Clark, J. H., Choi, E., Collins, M., Garrette, D., Kwiatkowski, T., Nikolaev, V., and Palomaki, J. (2020) TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages. arXiv preprint arXiv:2003.05002
[64] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A. A. M., Abid, A., Fisch, A., Brown, A. R., et al. (2022) Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615
[65] Shi, F., Suzgun, M., Freitag, M., Wang, X., Srivats, S., Vosoughi, S., et al. (2022) Language Models are Multilingual Chain-of-Thought Reasoners. arXiv preprint arXiv:2210.03057
[66] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H. W., et al. (2022) Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them. arXiv preprint arXiv:2210.09261
[67] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., et al. (2021) Training Verifiers to Solve Math Word Problems. arXiv preprint arXiv:2110.14168
[68] Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., and Iwasawa, Y. (2022) Large Language Models are Zero-Shot Reasoners. arXiv preprint arXiv:2205.11916
[69] Singhal, K., Azizi, S., Tu, T., Mahdavi, S. S., Wei, J., Chung, H. W., et al. (2022) Large Language Models Encode Clinical Knowledge. arXiv preprint arXiv:2212.13138
[70] Singhal, K., Tu, T., Gottweis, J., Sayres, R., Wulczyn, E., Hou, L., et al. (2023) Towards Expert-Level Medical Question Answering with Large Language Models. arXiv preprint arXiv:2305.09617
[71] Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., et al. (2023) Self-Refine: Iterative Refinement with Self-Feedback. arXiv preprint arXiv:2303.17651
[72] Tu, T., Azizi, S., Driess, D., Schaekermann, M., Amin, M., Chang, P.-C., Carroll, A., et al. (2023) Towards Generalist Biomedical AI. arXiv preprint arXiv:2307.14334
[73] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., et al. (2020) An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
[74] Chen, X., Wang, X., Changpinyo, S., Piergiovanni, AJ, Padlewski, P., Salz, D. et al. (2022) PaLI: A jointly-scaled multilingual language-image model. arXiv preprint arXiv:2209.06794
[75] Driess, D., Xia, F., Sajjadi, M. S. M., Lynch, C., Chowdhery, A., Ichter, B., et al. (2023) PaLM-E: An Embodied Multimodal Language Model. arXiv preprint arXiv:2303.03378
[76] Dehghani, M., Djolonga, J., Mustafa, B., Padlewski, P., Heek, J., Gilmer, J., et al. (2023) Scaling Vision Transformers to 22 Billion Parameters. arXiv preprint arXiv:2302.05442
[77] Zhang, R., Han, J., Liu, C., Gao, P., Zhou, A., Hu, X., et al. (2023) LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention. arXiv preprint arXiv:2303.16199
[78] Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., et al. (2023) Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv preprint arXiv:2302.04761
[79] Liu, H., Li, C., Wu, Q., and Lee, Y. J. (2023) Visual Instruction Tuning. arXiv preprint arXiv:2304.08485
[80] Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., et al. (2023) LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day. arXiv preprint arXiv:2306.00890
[81] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., et al. (2021) Learning Transferable Visual Models From Natural Language Supervision. arXiv preprint arXiv:2103.00020
[82] Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., and Smola, A. (2023) Multimodal Chain-of-Thought Reasoning in Language Models. arXiv preprint arXiv:2302.00923
[83] OpenAI (2023) GPT-4V(ision) System Card.
[84] OpenAI (2023) New models and developer products announced at DevDay.
[85] Yang, Z., Li, L., Lin, K., Wang, J., Lin, C.-C., Liu, Z., and Wang, L. (2023) The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision). arXiv preprint arXiv:2309.17421
[86] Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y. (2022) ReAct: Synergizing Reasoning and Acting in Language Models. arXiv preprint arXiv:2210.03629
[87] Yang, Z., Li, L., Wang, J., Lin, K., Azarnasab, E., Ahmed, F., et al. (2023) MM-ReAct: Prompting ChatGPT for Multimodal Reasoning and Action. arXiv preprint arXiv:2303.11381
[88] Shinn, N., Cassano, F., Berman, E., Gopinath, A., Narasimhan, K., and Yao, S. (2023) Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv preprint arXiv:2303.11366
[89] Gemini Team, Google (2023) Gemini: A Family of Highly Capable Multimodal Models. arXiv preprint arXiv:2312.11805
[90] Alayrac, J.-B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., et al. (2022) Flamingo: a Visual Language Model for Few-Shot Learning. arXiv preprint arXiv:2204.14198
[91] Yu, J., Wang, Z., Vasudevan, V., Yeung, L., Seyedhosseini, M., and Wu, Y. (2022) CoCa: Contrastive Captioners are Image-Text Foundation Models. arXiv preprint arXiv:2205.01917
[92] Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., and Sutskever, I. (2021) Zero-Shot Text-to-Image Generation. arXiv preprint arXiv:2102.12092
[93] Yu, J., Xu, Y., Koh, J. Y., Luong, T., Baid, G., Wang, Z., Vasudevan, V., et al. (2022) Scaling Autoregressive Models for Content-Rich Text-to-Image Generation. arXiv preprint arXiv:2206.10789
[94] Zhang, Y., Han, W., Qin, J., Wang, Y., Bapna, A., Chen, Z., et al. (2023) Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages. arXiv preprint arXiv:2303.01037
[95] Xu, Y., Lee, H., Chen, D., Hechtman, B., Huang, Y., Joshi, R., et al. (2021) GSPMD: General and Scalable Parallelization for ML Computation Graphs. arXiv preprint arXiv:2105.04663
[96] Dixit, H. D., Pendharkar, S., Beadon, M., Mason, C., Chakravarthy, T., Muthiah, B., and Sankar, S. (2021) Silent Data Corruptions at Scale. arXiv preprint arXiv:2102.11245
[97] Li, Y., Choi, D., Chung, J., Kushman, N., Schrittwieser, J., et al. (2022) Competition-Level Code Generation with AlphaCode. arXiv preprint arXiv:2203.07814
[98] AlphaCode Team, Google DeepMind (2023) AlphaCode 2 Technical Report.
[99] Pang, R. Y. and He, H. (2020) Text Generation by Learning from Demonstrations. arXiv preprint arXiv:2009.07839
[100] Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., et al. (2023) MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI. arXiv preprint arXiv:2311.16502
[101] Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., and Sutskever, I. (2022) Robust Speech Recognition via Large-ScaleWeak Supervision. arXiv preprint arXiv:2212.04356
[102] Zhang, Y., Han, W., Qin, J., Wang, Y., Bapna, A., Chen, Z., et al. (2023) Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages. arXiv preprint arXiv:2303.01037
[103] Weidinger, L., Mellor, J., Rauh, M., Griffin, C., Uesato, J., Huang, P.-S., et al. (2021) Ethical and social risks of harm from Language Models. arXiv preprint arXiv:2112.04359
[104] Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., et al. (2021) On the Opportunities and Risks of Foundation Models. arXiv preprint arXiv:2108.07258
[105] Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., et al. (2022) Emergent Abilities of Large Language Models. arXiv preprint arXiv:2206.07682
[106] Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., and Hashimoto, T. B. (2023) Alpaca: A Strong, Replicable Instruction-Following Model.
[107] Peng, B., Li, C., He, P., Galley, M., and Gao, J. (2023) Instruction Tuning with GPT-4. arXiv preprint arXiv:2304.03277
[108] Askell, A., Bai, Y., Chen, A., Drain, D., Ganguli, D., Henighan, T., et al. (2021) A General Language Assistant as a Laboratory for Alignment. arXiv preprint arXiv:2112.00861
[109] Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., et al. (2022) Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. arXiv preprint arXiv:2204.05862
[110] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., et al. (2020) Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165
[111] Zhou, D., Sch¨arli, N., Hou, L., Wei, J., Scales, N., Wang, X., et al. (2022) Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. arXiv preprint arXiv:2205.10625
[112] Arora, S., Narayan, A., Chen, M. F., Orr, L., Guha, N., Bhatia, K., et al. (2022) Ask Me Anything: A Simple Strategy for Prompting Language Models. arXiv preprint arXiv:2210.02441
[113] Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N. A., and Lewis, M. (2022) Measuring and Narrowing the Compositionality Gap in Language Models. arXiv preprint arXiv:2210.03350
[114] Khot, T., Trivedi, H., Finlayson, M., Fu, Y., Richardson, K., et al. (2022) Decomposed Prompting: A Modular Approach for Solving Complex Tasks. arXiv preprint arXiv:2210.02406
[115] Zhangy, Z., Zhang, A., Liz, M., and Smola, A. (2022) Automatic Chain of Thought Prompting in Large Language Models. arXiv preprint arXiv:2210.02406
[116] Chen, W., Ma, X., Wang, X., and Cohen, W. W. (2022) Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks. arXiv preprint arXiv:2211.12588
[117] Yao, S., Yu, D., Zhou, J., Shafran, I., Griffiths, T. L., et al. (2023) Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv preprint arXiv:2305.10601
[118] Ning, X., Lin, Z., Zhou, Z., Wang, Z., Yang, H., and Wang, Y. (2023) Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding. arXiv preprint arXiv:2307.15337
[119] Besta, M., Blach, N., Kubicek, A., Gerstenberger, R., Gianinazzi, L., Gajda, J., et al. (2023) Graph of Thoughts: Solving Elaborate Problems with Large Language Models. arXiv preprint arXiv:2308.09687
[120] Zelikman, E., Wu, Y., Mu, J., and Goodman, N. D. (2022) STaR: Self-Taught Reasoner. Bootstrapping Reasoning with Reasoning. arXiv preprint arXiv:2203.14465
[121] Haluptzok, P., Bowers, M., and Kalai, A. T. (2022) Language Models Can Teach Themselves to Program Better. arXiv preprint arXiv:2207.14502
[122] Yang, K., Tian, Y., Peng, N., and Klein, D. (2022) Re\(^3\): Generating Longer Stories With Recursive Reprompting and Revision. arXiv preprint arXiv:2210.06774
[123] Welleck, S., Lu, X., West, P., Brahman, F., Shen, T., et al. (2022) Generating Sequences by Learning to [Self-]Correct. arXiv preprint arXiv:2211.00053
[124] Saunders, W., Yeh, C., Wu, J., Bills, S., Ouyang, L., Ward, J., and Leike, J. (2022) Self-Critiquing Models for Assisting Human Evaluators. arXiv preprint arXiv:2206.05802
[125] Kim, G., Baldi, P., and McAleer, S. (2023) Language Models can Solve Computer Tasks. arXiv preprint arXiv:2303.17491
[126] Paul, D., Ismayilzada, M., Peyrard, M., Borges, B., Bosselut, A., et al. (2023) REFINER: Reasoning Feedback on Intermediate Representations. arXiv preprint arXiv:2304.01904
[127] Chen, X., Lin, M., Schärli, N., and Zhou, D. (2023) Teaching Large Language Models to Self-Debug. arXiv preprint arXiv:2304.05128
[128] Zhang, K., Li, Z., Li, J., Li, G., and Jin, Z. (2023) Self-Edit: Fault-Aware Code Editor for Code Generation. arXiv preprint arXiv:2305.04087
[129] Gou, Z., Shao, Z., Gong, Y., Shen, Y., Yang, Y., Duan, N., and Chen, W. (2023) CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing. arXiv preprint arXiv:2305.11738
[130] Jiang, S., Wang, Y., and Wang, Y. (2023) SelfEvolve: A Code Evolution Framework via Large Language Models. arXiv preprint arXiv:2306.02907
[131] Zelikman, E., Lorch, E., Mackey, L., and Kalai, A. T. (2023) Self-Taught Optimizer (STOP): Recursively Self-Improving Code Generation. arXiv preprint arXiv:2310.02304
[132] Wu, T., Jiang, E., Donsbach, A., Gray, J., Molina, A., Terry, M., and Cai, C. J. (2022) PromptChainer: Chaining Large Language Model Prompts through Visual Programming. arXiv preprint arXiv:2203.06566
[133] Park, J. S., Popowski, L., Cai, C. J., Morris, M. R., Liang, P., and Bernstein, M. S. (2022) Social Simulacra: Creating Populated Prototypes for Social Computing Systems. arXiv preprint arXiv:2208.04024
[134] Li, G., Hammoud, H. A. A. K., Itani, H., Khizbullin, D., and Ghanem, B. (2023) CAMEL: Communicative Agents for “Mind” Exploration of Large Language Model Society. arXiv preprint arXiv:2303.17760
[135] Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., and Bernstein, M. S. (2023) Generative Agents: Interactive Simulacra of Human Behavior. arXiv preprint arXiv:2304.03442
[136] Deshpande, A., Murahari, V., Rajpurohit, T., Kalyan, A., and Narasimhan, K. (2023) Toxicity in ChatGPT: Analyzing Persona-assigned Language Models. arXiv preprint arXiv:2304.05335
[137] Fu, Y., Peng, H., Khot, T., and Lapata, M. (2023) Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback. arXiv preprint arXiv:2305.10142
[138] Xu, B., Yang, A., Lin, J., Wang, Q., Zhou, C., Zhang, Y., and Mao, Z. (2023) ExpertPrompting: Instructing Large Language Models to be Distinguished Experts. arXiv preprint arXiv:2305.14688
[139] Hao, R., Hu, L., Qi, W., Wu, Q., Zhang, Y., and Nie, L. (2023) ChatLLM Network: More brains, More intelligence. arXiv preprint arXiv:2304.12998
[140] Xiong, K., Ding, X., Cao, Y., Liu, T., and Qin, B. (2023) Examining Inter-Consistency of Large Language Models Collaboration: An In-depth Analysis via Debate. arXiv preprint arXiv:2305.11595
[141] Du, Y., Li, S., Torralba, A., Tenenbaum, J. B., and Mordatch, I. (2023) Improving Factuality and Reasoning in Language Models through Multiagent Debate. arXiv preprint arXiv:2305.14325
[142] Liang, T., He, Z., Jiao, W., Wang, X., Wang, Y., Wang, R., Yang, Y., Tu, Z., and Shi, S. (2023) Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. arXiv preprint arXiv:2305.19118
[143] Jiang, D., Ren, X., and Lin, B. Y. (2023) LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion. arXiv preprint arXiv:2306.02561
[144] Zhang, Y., Yang, J., Yuan, Y., and Yao, A. C. (2023) Cumulative Reasoning with Large Language Models. arXiv preprint arXiv:2308.04371
[145] Chen, W., Su, Y., Zuo, J., Yang, C., Yuan, C., et al. (2023) AgentVerse: Facilitating Multi-Agent Collaboration and Exlporing Emergent Behavior. arXiv preprint arXiv:2308.10848
[146] Chen, G., Dong, S., Shu, Y., Zhang, G., Sesay, J., et al. (2023) AutoAgents: A Framework for Automatic Agent Generation. arXiv preprint arXiv:2309.17288
[147] Liu, Z., Zhang, Y., Li, P., Liu, Y., and Yang, D. (2023) Dynamic LLM-Agent Network: An LLM-Agent Collaboration Framework with Agent Team Optimization. arXiv preprint arXiv:2310.02170
[148] Parisi, A., Zhao, Y., and Fiedel, N. (2022) TALM: Tool Augmented Language Models. arXiv preprint arXiv:2205.12255
[149] Paranjape, B., Lundberg, S., Singh, S., Hajishirzi, H., Zettlemoyer, L., and Ribeiro, M. T. (2023) ART: Automatic multi-step reasoning and tool-use for large language models. arXiv preprint arXiv:2303.09014
[150] Liang, Y., Wu, C., Song, T., Wu, W., Xia, Y., Liu, Y., et al. (2023) TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs. arXiv preprint arXiv:2303.16434
[151] Shen, Y., Song, K., Tan, X., Li, D., Lu, W., and Zhuang, Y. (2023) HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face. arXiv preprint arXiv:2303.17580
[152] Chen, L., Zaharia, M., and Zou, J. (2023) How Is ChatGPT’s Behavior Changing over Time?. arXiv preprint arXiv:2307.09009
[153] Qin, Y., Hu, S., Lin, Y., Chen, W., Ding, N., Cui, G., et al. (2023) Tool Learning with Foundation Models. arXiv preprint arXiv:2304.08354
[154] Lu, P., Peng, B., Cheng, H., Galley, M., Chang, K.-W, et al. (2023) Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models. arXiv preprint arXiv:2304.09842
[155] Hao, S., Liu, T., Wang, Z., and Hu, Z. (2023) ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings. arXiv preprint arXiv:2305.11554
[156] Qiao, S., Gui, H., Lv, C., Jia, Q., Chen, H., and Zhang, N. (2023) Making Language Models Better Tool Learners with Execution Feedback. arXiv preprint arXiv:2305.13068
[157] Patil, S. G., Zhang, T., Wang, X., and Gonzalez, J. E. (2023) Gorilla: Large Language Model Connected with Massive APIs. arXiv preprint arXiv:2305.15334
[158] Yang, R., Song, L., Li, Y., Zhao, S., Ge, Y., Li, X., and Shan, Y. (2023) GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction. arXiv preprint arXiv:2305.18752
[159] Hu, E., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., et al. (2021) LORA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685
[160] Gao, D., Ji, L., Zhou, L., Lin, K. Q., Chen, J., Fan, Z., and Shuo, M. Z. (2023) AssistGPT: A General Multi-modal Assistant that can Plan, Execute, Inspect, and Learn. arXiv preprint arXiv:2306.08640
[161] Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., Liu, Y., et al. (2023) ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. arXiv preprint arXiv:2307.16789
[162] Yuan, L., Chen, Y., Wang, X., Fung, Y. R., Pemg, H., and Ji, H. (2023) CRAFT: Customizing LLMs by Creating and Retrieving from Specialized Toolsets. arXiv preprint arXiv:2309.17428
[163] Khattab, O., Singhvi, A., Maheshwari, P., Zhang, Z., Santhanam, K., et al. (2023) DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines. arXiv preprint arXiv:2310.03714
[164] Gur, I., Furuta, H., Huang, A., Safdari, M., Matsuo, Y., et al. (2023) A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis. arXiv preprint arXiv:2307.12856
[165] Guo, M., Ainslie, J., Uthus, D., Ontañón, S., Ni, J., et al. (2021) LongT5: Efficient Text-To-Text Transformer for Long Sequences. arXiv preprint arXiv:2112.07916
[166] Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., et al. (2023) MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. arXiv preprint arXiv:2308.00352
[167] Qiao, B., Li, L., Zhang, X., He, S., Kang, Y., Zhang, C., et al. (2023) TaskWeaver: A Code-First Agent Framework. arXiv preprint arXiv:2311.17541
[168] Zhou, W., Jiang, Y. E., Li, L., Wu, J., Wang, T., et al. (2023) Agents: An Open-source Framework for Autonomous Language Agents. arXiv preprint arXiv:2309.07870
[169] Xie, T., Zhou, F., Cheng, Z., Shi, P., Weng, L., et al. (2023) OpenAgents: An Open Platform for Language Agents in the Wild. arXiv preprint arXiv:2310.10634
[170] Suzgun, M. and Kalai, A. T. (2024) Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding. arXiv preprint arXiv:2401.12954
[171] Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E., et al. (2023) AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. arXiv preprint arXiv:2308.08155