Understanding the Family of Transformer Models. Part I - Language Models
Oct 26, 2020 by Shuo-Fu "Michael" Chen
Language understanding and language generation are inherently sequential processes that have been modeled by various forms of gated recurrent neural network (RNN) in the mid-2010s. The recursive compression nature of gated RNNs suffer from the lack of structural alignment ability and computational parallelizability. To address the alignment issues between input elements and output elements in sequence-to-sequence models, Bahdanau et al., 2014[1] and Chorowski et al. 2014[2] introduced attention mechanism in RNNs for machine translation and speech recognition, respectively. To develop a structure-aware general-purpose language model, Cheng et al. 2016[3] introduced self-attention mechanism in RNN to relate tokens within the entire input sequence. To address the parallelizability issue, Parikh et al. 2016[4] introduced a pure attention model, abandoning RNN, for natural language inference, which outperformed state-of-the-art RNNs with much fewer parameters. The idea of pure attention model was greatly scaled up, by increasing the number of attention layers and the number of attention functions (i.e. attention heads) per layer, in the Transformer model[5] that achieved state-of-the-art performance on machine translation. The transformer has become the de facto architecture for language modeling. There is a trend of scaling up the capacity of the transformer model and pre-training it on ever increasing amount of data, in pursuit of new state-of-the-art benchmark scores. Some of the most prominent models in this trend are reviewed here.
- The Transformer Model
- Language Models Based on the Transformer
- Codes
- References
The Transformer Model
The Transformer model is an encoder-decoder architecture that encodes an input sequence (x1, …,xn) to a concept sequence z=(z1, …,zn) for all input tokens simultaneously and then decodes z to an output sequence (y1, …,ym) one output element at a time. When generating the next output element, all the previously generated output elements are used as additional inputs to the decoder.
Model Architecture
![]()
Source of the Diagram: Vaswani et al., 2017
The Embedding layers convert input and output tokens to vectors of dimension dmodel (512 for base and 1024 for big). The two embedding layers share the same weight matrix that is also shared with the linear transformation layer before the softmax function of the decoder output. But the weights in the embedding layers are multiplied by \(\sqrt{d_{model}}\).
The positions of the input tokens in the input sequence are encoded by “positional encodings” into the same dimension dmodel as the embeddings, so that the two can be summed. Each dimension of the positional encoding corresponds to a sine or cosine functions of different frequences: \(PE_{(pos, 2i)}=sin(pos/10000^{2i/d_{model}})\) and \(PE_{(pos, 2i+1)}=cos(pos/10000^{2i/d_{model}})\), where pos is the position and i is the dimension.
The encoder has N = 6 identical layers, each with a multi-head self-attention sub-layer, followed by a fully connected feed-forward sub-layer. Both sub-layers have a residual connection, followed by layer normalization. Each attention head first linearly transforms K (keys), V (values), and Q (queries) using a set of “reading” weight matrices and then computes scaled dot-product attention. Different attention heads have different set of “reading” weight matrices and their scaled dot-product attention ressults are concatenated together, followed by a linear transformation to complete the multi-head attention. The dimensions of K, V, Q are \(d_k\), \(d_v\), and \(d_k\), respectively; and the dimensions of their corresponding “reading” weight matrices are \(d_{model}\times d_k\), \(d_{model}\times d_v\), and \(d_{model}\times d_k\), respectively. If the number of heads is h, then \(d_k = d_v = d_{model}/h\). The dimension of the weight matrix for the linear projection of the concatenated result is \(hd_v\times d_{model}\).
$$MultiHead(Q, K, V)=Concat(head_1, ..., head_h)W^O$$, where $$head_i=Attention(QW_i^Q, KW_i^K, VW_i^V)=softmax(\frac{QW_i^Q(KW_i^K)^T}{\sqrt{d_k}})VW_i^V$$.
The fully connected feed-forward sub-layer contains two linear transformations with a ReLU activation in between, \(FFN(x)=max(0, xW_1+b_1)W_2+b_2\).
The decoder also has N = 6 identical layers, but differs from the encoder with an additional multi-head encoder-decoder attention sub-layer in the middle and a “masked” multi-head self-attention sub-layer. In the encoder-decoder attention, the Q are from the previous decoder layer and the K and V are from the output of the encoder. This allows every element in the decoder to attend all elements in the input sequence. In the “masked” self-attention, each position in the decoder can only attend to left positions up to and including itself, which was implemented in scaled dot-product by setting values to \(-\infty\) in the input to softmax for right-ward attention. The masking ensures that the predictions for the next output element can only depend on previously predicted output elements.
Model Performance
The big transformer model established new state-of-the-art performance on both the WMT 2014 English-to-German and English-to-French translation tasks. The base transformer model also surpassed previous state-of-the-art performance on the WMT 2014 English-to-German translation task at a fraction of the training cost.
In this study, both input and output sentences were tokenized into subword units so that rare words could be handled deterministically. The subword tokenization was implemented with Byte Pair Encoding[6] for English-German dataset and with Wordpiece Model[7] for English-French dataset.
The number of attention heads h = 8 yielded the best performance for the base transformer model; decreasing or increasing h (corresponding to increasing or decreasing \(d_k\)) reduced performance.
Using a 4-layer transformer with \(d_{model}=1024\) for English constituency parsing task, the transformer model outperformed most of the previously reported models, except the state-of-the-art RNN models at that time.
Language Models Based on the Transformer
Because language models can be trained on unlabeled text data and large amount of text data are readily available, general-purpose language models using the transformer architecture have been built with ever-increasing capacity. The learned language knowledge in such large-scale models can then be transfered to perform a wide variety of tasks by fine-tuning with small amount of task-specific labeled data. These models can be categorized into six groups, based on their language modeling approaches.
| Type of LM | Objective Function | Definitions |
|---|---|---|
| Standard Autoregressive (AR) | \(\underset{\theta}{\max}\;\log\mathit{p}_{\theta}(\mathrm{\mathbf{x}})=\sum\limits_{t=1}^{T}\log\mathit{p}_{\theta}(x_{t}|\mathrm{\mathbf{x}}_{\lt t})\) | 1. \(\mathrm{\mathbf{x}}=[x_{1},...,x_{T}]\) is token sequence. 2. \(\theta\) is model parameters. |
| Masked Autoencoding (AE) | \(\underset{\theta}{\max}\;\log\mathit{p}_{\theta}(\mathrm{\mathbf{\bar x}}|\mathrm{\mathbf{\hat x}})\approx \sum\limits_{t=1}^{T} m_{t}\log\mathit{p}_{\theta}(x_{t}|\mathrm{\mathbf{\hat x}})\) | 1. \(\mathrm{\mathbf{\hat x}}=\mathrm{\mathbf{x}}\) with 15% of tokens replaced by [MASK]. 2. \(\mathrm{\mathbf{\bar x}}=\) masked tokens 3. \(m_{t}=1\) when \(x_{t}\) is masked, 0 otherwise. |
| Permutation Autoregressive | \(\underset{\theta}{\max}\;\mathbb{E}_{\mathrm{\mathbf{z}}\sim \mathcal{Z}_{T}}\bigg[\sum\limits_{t=1}^{T}\log\mathit{p}_{\theta}(x_{z_{t}}|\mathrm{\mathbf{x}}_{\mathrm{\mathbf{z}}_{\lt t}})\bigg]\) | 1. \(\mathcal{Z}_{T}=\) the set of all possible, \(T!\), permutations of the index sequence [1, 2,…, T]. 2. a permutation \(\mathrm{\mathbf{z}}\in \mathcal{Z}_{T}\). 3. \(z_{t}=\) the t-th element of \(\mathrm{\mathbf{z}}\). 4. \(\theta\) is shared across all permutations. |
| Denoising Autoencoding | \(\underset{\theta}{\max}\;\log\mathit{p}_{\theta}(\mathrm{\mathbf{y}}|\mathrm{\mathbf{x}})=\sum\limits_{t=1}^{T_{y}}\log\mathit{p}_{\theta}(y_{t}|\mathrm{\mathbf{x}},\mathrm{\mathbf{y_{\lt t}}})\) | 1. \(\mathrm{\mathbf{x}}=[x_{1},...,x_{T_{x}}]\) is the noisy source sequence. 2. \(\mathrm{\mathbf{y}}=[y_{1},...,y_{T_{y}}]\) is the corresponding clean sequence. 3. sequence-to-sequence on encoder-decoder architecture. |
| Retrieval-Augmented LMs (AE or AR) | \(\underset{\theta,\phi}{\max}\;\log\mathit{p}_{\theta,\phi}(\mathrm{\mathbf{y}}|\mathrm{\mathbf{x}})=\log(\sum\limits_{z\in\mathcal{Z}}\mathit{p}_{\phi}(\mathrm{\mathbf{y}}|z,\mathrm{\mathbf{x}})\mathit{p}_{\theta}(z|\mathrm{\mathbf{x}}))\) | 1. \(\mathrm{\mathbf{x}},\mathrm{\mathbf{y}},\theta,\phi\) are input, output, parameters of Knowledge Retriever, and parameters of Knowledge-Augmented Encoder/Generator, respectively. 2. \(z\) is a document in a knowledge corpus \(\mathcal{Z}\). |
| Combined AE and AR LMs | Two-stage Pre-training: Stage 1 - AE on Encoder Only Stage 2 - AR on Encoder-Decoder |
1. The Stage 1 is identical to the Masked LM above. 2. The Stage 2 is similar to the denoising AE above, but instead of having \(\mathrm{\mathbf{y}}\) being a noised \(\mathrm{\mathbf{x}}\), now having \(\mathrm{\mathbf{y}}\) being subsequent span to \(\mathrm{\mathbf{x}}\). |
Standard Language Models
Standard language model’s objective is to maximize the conditional probability of generating a token given all the k previously generated tokens, where k is the size of the context window. This type of language modeling is referred to as Causal Language Modeling or Autoregressive Language Modeling by some authors. The decoder part of the transformer model, without the encoder-decoder attention sub-layer, is a natural fit for a language model. The groups at OpenAI adopted the decoder portion of the transformer model to build a series of high-capacity language models in a process named Generative Pre-Training (GPT).
GPT
Radford et al., 2018[8] introduced the GPT model, as illustrated below. The Transformer blocks shown in the right figure are the GPT variant decoder-only stack (the left figure) of the Transformer.
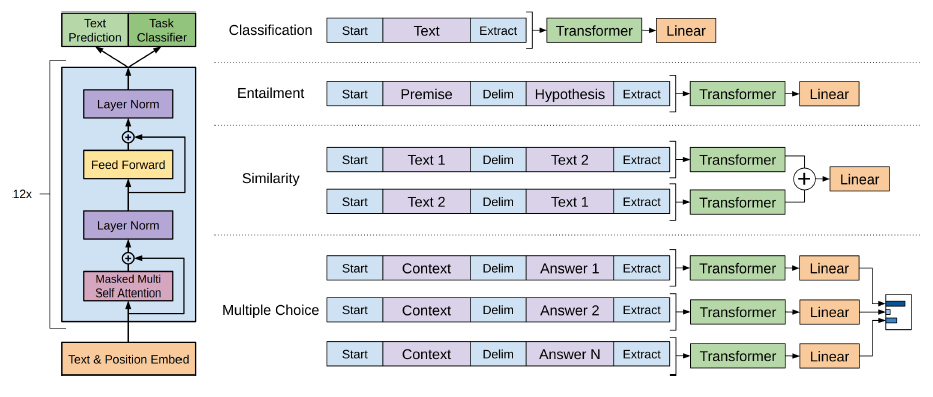
The total number of parameters of GPT are between TransformerBase and TransformerBig, with the number of layers N = 12, the number of heads h = 12, and the dimension of the embedding dmodel = 768. Learned positional embeddings were used, instead of the original sinusoidal positional encoding. The BooksCorpus dataset of 11,038 books in 16 different genres, tokenized with a bytepair encoding vocabulary of 40,000, was used to train the language model.
The parameters of the pre-trained language model were then used for supervised fine-tuning tasks. In a labeled dataset, each instance contains a sequence of input tokens and a label. A new layer consisted of a linear transformation and a softmax function is added to convert the final output element (the Extract token in the diagram) of the decoder to the probability of the corresponding label. The objective of the fine-tuning is to maximize the probability of the given label, conditional to the given sequence of tokens. To improve generalization and accelerate convergence, language model objective is added, as an auxiliary objective, to the fine-tuning objective.
For text classification task, the fine-tuning model above can be used directly. But for some other tasks, structured inputs have to be converted into an ordered sequence with a delimiter token in between. For textual entailment or natural language inference (NLI) tasks, each premise-hypothesis statements pair is concatenated into an ordered sequence with three possible labels: entailing, contradictory, or neutral. For semantic similarity or paraphrase detection tasks, both orders of the two sentences are processed independently and their final element outputs from the decoder are added element-wise before being fed into the linear output layer that predicts whether the two sentences are equivalent or not. For multiple-choice problems, such as Question Answering or Commonsense Reasoning, given context document z, question q, and a set of k possible answers are concatenated into [z, q, delimiter token, \(a_i\)], each of which is processed independently to predict whether the answer is correct. The k predictions are then normalized via a softmax layer to produce an output distribution. Fine-tuning could be done quickly and 3 epochs of training was sufficient for most cases.
In NLI tasks, the GPT model significantly outperformed previous best models in four of the five datasets examined. In Question Answering using RACE dataset and Commonsense Reasoning using Story Cloze, the GPT model significantly outperformed previous best models. In semantic similarity tasks, the GPT model outperformed the previous best on two of the three datasets examined. In classification tasks, the GPT model significantly outperformed the previous best model on one of the two datasets examined. The GPT model achieved a new state-of-the-art overall score on the GLUE benchmark, a 9-task benchmark for natural language understanding[9].
Analyses of zero-shot (performing downstream tasks without fine-tuning) behaviors demonstrated that the language model acquired useful linguistic knowledge for downstream tasks, including linguistic acceptability (grammatical correctness), sentiment binary classification, question answering, and commonsense reasoning (winograd schemas challenge).
GPT-2
To test the hypothesis that language model with sufficient capacity can perform well on multiple tasks without transfer learning, Radford et al., 2019[10] introduced GPT-2 model that has the same architecture as GPT, but with drastically increased capacity (number of layers N = 48 and dimension of the embedding dmodel = 1600). Other modifications to GPT included moving layer normalization from the output to the input of each sub-layer, adding layer normalization to the output of the final self-attention block, and scaling the weights of residual layers at initialization by a factor of 1/\(\sqrt{N}\) where N is the number of residual layers. The context size was increased from 512 to 1024. The training dataset, WebText, was 40GB of text from over 8 million web pages that were outbound links from Reddit with at least 3 karma (proportional to user upvotes), excluding Wikipedia pages. Byte Pair Encoding vocabulary size was 50,257.
The GPT-2 language model (LM) was evaluated for LM accuracy or perplexity in zero-shot setting on 8 different datasets and it outperformed the state-of-the-art models on 7 out of the 8 datasets. The GPT-2 also matched or exceeded some supervised baseline models on commonsense reasoning (Winograd Schema challenge) and reading comprehension (CoQA) tasks, but performed far worse than some supervised or fine-tuned models on other tasks, including summarization, translation, and question answering. The GPT-2 may still underfit the WebText, because the perplexity of the test set continued to go down.
GPT-3
Moving further along the same path, Brown et al., 2020[11] introduced GPT-3 model that has the same architecture as GPT-2, but with drastically increased capacity (number of layers N = 96, dimension of the embedding dmodel = 12288, number of heads h=96, and context window size 2048). Another modification was to use factorized self-attention heads with alternating dense and locally banded sparse attention patterns, similar to the Sparse Transformer[12], for faster attention operations. The training dataset were from 4 sources: WebText2 (similar to WebText of GPT-2, but over longer period), Wikipedia, two internet-based books corpora (Books1 and Books2), and Common Crawl. Fuzzy deduplication at document level was performed within and across datasets. Low quality documents in Common Crawl dataset were removed using a classifier trained with high quality examples from WebText2. The final total byte-pair-encoded tokens were about 500 billion. During training, higher-quality datasets were sampled more frequently. Data overlaps between LM training dataset and test datasets of benchmarks studies were reduced, but not completely removed.
The GPT-3 LM model was evaluated on over two dozen benchmarks datasets and several novel tasks for three conditions, “few-shot learning”, “one-shot learning”, and “zero-shot learning”. The “K-shot learning” refers to the number of examples included in the input sequence, in the form of \((task description, (prompt, answer)\times K, prompt)\), at inference time without any weight updates. The K in “few-shot learning” was typically in the range of 10 and 100. Overall, increasing K increased task performance and such increase was steeper for larger models.
The GPT-3 achieved new state-of-the-art performance on some datasets, including zero-shot perplexity on the Penn Tree Bank (PTB) dataset (a traditional language modeling dataset), few-shot accuracy on LAMBDA dataset (reading a paragraph and predicting the last word of sentences), one-shot and few-shot results on TriviaQA dataset (closed-book question answering), few-shot results on WMT’14 Fr->En and WMT’16 De->En translation, zero-, one-, and few-shot results on PIQA dataset (common sense questions about how the physical world works).
The GPT-3 still performed worse, by a large margin in some cases, than fine-tuned state-of-the-art models on many other datasets, including HellaSwag dataset (selecting the best ending to a story or set of instructions) and StoryCloze dataset (selecting the correct ending sentence for five-sentence long stories), Natural Question and WebQuestions datasets (closed-book question answering), WMT’14 En->Fr, WMT’16 En->De, and WMT’16 En<->Ro translation, Winograd Schema Challenge and adversarially-mined Winogrande datasets (determining which word a gramatically ambiguous pronoun refers to), ARC (Easy) and ARC (Challenge) datasets (multiple-choice questions from 3rd to 9th grade science exams), OpenBookQA dataset (multi-hop reasoning with partial context provided by elementary level science facts), 5 reading comprehesion datasets of different formats (CoQA, QuAC, DROP, SQuADv2, RACE), the standardized collection of datasets of the SuperGLUE benchmark, Adversarial Natural Language Inference (ANLI) dataset.
Few-shot settings of the GTP-3 also demonstrated some abilities in many synthetic and qualitative tasks, including simple arithmetic operations on integers with 3 or less digits, character manipulation and word unscrambling tasks (cycle letters in words, anagrams of all but first and last/last 2 characters, random insertion in word, reversed words), SAT Analogies (multiple choice questions from the college entrance exam for selecting the same type of word pair relationship), correcting English grammar, learning and using novel words. The GPT-3 can generate samples of news articles which human evaluators have difficult distinguishing from articles written by humans.
Contextual Calibration of Few-Shot Learning
Although GPT-3 has displayed competitive or even state-of-the-art performance in few-shot learning on a wide range of tasks[11], Zhao et al., 2021[20] have shown that the performance of few-shot learning in GPT-3 is very unstable on some text classification, fact retrieval, and information extraction tasks. They show that GPT-3’s accuracy depends highly on the prompt format, where a prompt contains three components: a format, a set of training examples, and a permutation (ordering) of those examples. The accuracy also depends highly on both the selection and the ordering of training examples and the variance of accuracy persists even with more training examples or larger models. Furthermore, they show that the variances are caused by three types biases: (1) majority label bias, where more frequent label in the prompt is predicted more, (2) recency bias, where labels near the end of the prompt is predicted more, and (3) common token bias, where more frequent tokens in the pre-training dataset are predicted more.
To correct the biases, Zhao et al., 2021[20] introduce the contextual calibration procedure that estimates the model’s bias towards certain answers by feeding in a content-free input, such as “N/A”, assuming that content-free inputs should give uniform probabilities to all answers. The actual context-dependent output probability from content-free input, denoted as \(\mathrm{\hat p}_{cf}\), is an average of those from “N/A”, “[MASK]”, and empty string. Then, a weight matrix \(\mathrm{\mathbf{W}}\) is set as \(\mathrm{\mathbf{W}}=\mathrm{diag}(\mathrm{\hat p}_{cf})^{-1}\). The calibrated probability is defined as \(\mathrm{\mathbf{W}}\mathrm{\hat p}+\mathrm{b}\), where \(\mathrm{\hat p}\) is the original probability and \(\mathrm{b}\) is set to all-zero vector. This contextual calibration procedure is data-free and adds trivial amounts of computational overhead.
The experimental results of the contextual calibration show that it dramatically improves GPT-3’s average and worst-case accuracy, by up to 30.0% absolute; it sometimes allows GPT-3 2.7B to outperform the GPT-3 175B baseline—by up to 19.3%; it reduces the variance considerably in a majority of cases; and it also improves the mean accuracy and reduces variance for most tasks in GPT-2. However, contextual calibration does not eliminate the need to engineer prompts.
Masked Language Models
In addition to the unidirectional generative approach, as applied in building the GPT models, language models can also be built using bidirectional masked approach, where some tokens from the input are randomly masked and the objective is to predict the original token of the masked position based on its context on both sides. The BERT (Bidirectional Encoder Representations from Transformers) subfamily of models are masked language models based on the encoder portion of the transformer model.
BERT
Devlin et al., 2019[13] introduced the BERT model, as illustrated below. Similar to GPT, BERT consists of two stages: pre-training and fine-tuning. The model is first pre-trained on unlabeled data over two different tasks; then, each downstream task has a separate fine-tuned model, initialized with the same pre-trained parameters and trained with task-specific labeled data.
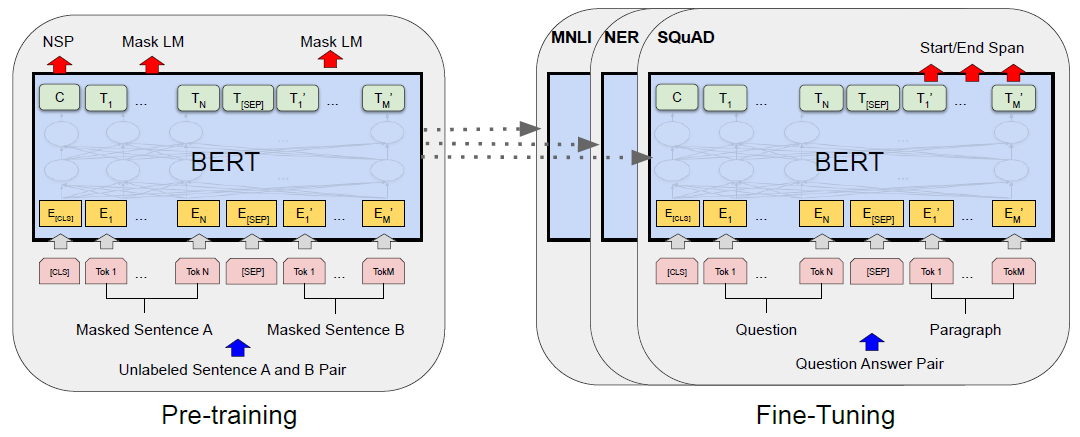
The model architecture of BERT is almost identical to the encoder portion of the transformer. The number of layers N, the number of heads h, and the dimension of the embedding dmodel are (N=12, h=12, dmodel=768) for BERTBASE and (N=24, h=16, dmodel=1024) for BERTLARGE. Text are tokenized with WordPiece Model of 30,000 token vocabulary. Input can represent a single text segment or a pair of text segments with a special token [SEP] in between. Learnable segment embeddings are added to indicate segment A or segment B. Final input representation for each token is the sum of token embedding, segment embedding, and positional embedding. The first token of every input sequence is always a special classification token [CLS], whose corresponding hidden vector in the output of the final layer is used as the aggregate representation for the output of classification tasks.
The pre-training datasets include BooksCorpus (800M words) and English Wikipedia (2,500M words). Two unsupervised tasks are included in the pre-training: Masked Language Modeling (MLM, also known as Auto-Encoding) and Next Sentence Prediction (NSP). In the MLM, 15% of all tokens in each input sequence are masked at random for prediction by softmax of the corresponding final hidden vectors over the vocabulary. The NSP is to pre-train the model to predict sentence relationships as binary classification (B IsNext/NotNext of A) for paired sentence inputs (A, B). For each fine-tuning task, just one additional classification layer is added and task-specific inputs and outputs are fed into BERT and all the weights are updated end-to-end.
BERTLARGE achieved new state-of-the-art results on eleven natural language processing datasets, including the GLUE score of 80.5 (7.7 point absolute improvement), MultiNLI accuracy of 86.7 (4.6 point absolute improvement), SQuAD v1.1 question answering Test F1 of 93.2 (1.5 point absolute improvement), SQuAD v2.0 Test F1 of 83.1 (5.1 point absolute improvement), and SWAG sentence-pair completion accuracy of 86.3 (8.3 point absolute improvement).
BERTBASE has the same model size as GPT, but gained 4.5 point improvement on GLUE score. Abalation studies show that both the bidirectionality of the MLM and the NSP task of the pre-training are significant contributors to GLUE score. In addition to fine-tuning pre-trained large model, transfer learning can also be done with feature-based approach, where contextual embeddings of tokens are extracted from the pre-trained large model to represent inputs for training small models of downstream tasks. In a Named Entity Recognition task, concatenation of the token representations from the top four hidden layers of the pre-trained BERTBASE achieved comparable performance to the fine-tuned BERTBASE.
RoBERTa
Liu et al., 2019[14] investigated the effect of larger training dataset size and alternative training hyperparameters of the BERT, without any change to the model architecture. The new training configuration of the BERT is called Robustly optimized BERT approach (RoBERTa). The new training dataset is collected from more diverse sources, with total size of 160GB, 10 times of the size used by BERT. The new batch size is 8K, more than 30 times of the batch size of BERT. The training steps are 0.5M and 1M for RoBERTa and BERT, respectively; thus, total instances of training are 4B and 256M for RoBERTa and BERT, respectively. Larger training dataset, larger batch size, and longer training have been shown to be substantially beneficial; but other hyperparameter changes included in the new configuration have been shown to have little benefit, including larger BPE vocabulary size, dynamic token masking, training on longer sequence, and removal of NSP pre-training task.
RoBERTa achieved new state-of-the-art GLUE score of 88.5, far above the 80.5 by BERTLARGE. It also set new state-of-the-art results on two question answering tasks, RACE and SQuAD, with large margin over corresponding scores by BERTLARGE. These results showed that the original BERT model was significantly underfit.
Extensions to BERT
Numerous efforts have been made to reduce the computational cost of BERT and, at the same time, to improve its performance on downstream tasks. Two examples, ALBERT and ELECTRA, are reviewed here. ALBERT improves parameter efficiency and introduces sentence-order prediction to replace BERT’s next sentence prediction. ELECTRA improves sample efficiency and introduces replaced token detection objective in a generator-discriminator pre-training scheme.
ALBERT
Lan et al., 2019[22] introduced A Lite BERT (ALBERT) that drastically reduced the number of parameters of BERT by two techniques: (1) a factorized embedding parameterization, and (2) cross-layer parameter sharing. In addition, ALBERT improved the pre-training objective of BERT by modifying the definition of negative examples in the next sentence prediction task to become sentence-order prediction task.
The factorized embedding parameterization is to allow the vocabulary embedding size \(E\) to be different from the hidden layer size \(H\), as opposed to \(E=H\) in BERT, RoBERTa, and XLNet. If \(E=H\), then increasing \(H\) increases the size of the embedding matrix, \(V\times E\), where \(V\) is the vocabulary size and \(V\)=30,000 in this study, and easily results in billions of parameters. Also, token embedding and hidden-layer embedding are supposed to learn context-independent and context-dependent representations, respectively. It is desirable to have \(E\ll H\). The decoupling reduces the embedding parameters from \(O(V\times H)\) to \(O(V\times E+E\times H)\). Ablation experiments show that \(E\)=128 appears to be the best. ALBERT shares parameters across layers on both feed-forward network and attention parameters. The number of parameters are 334M and 18M in BERT-large and ALBERT-large, respectively, with 24 layers and 1024 hidden-layer size. However, the downstream task performance is reduced after applying the two parameter reduction techniques.
The next sentence prediction (NSP) task of BERT predicts whether the second segment of an input is the next segment of the first segment or not, in which the negative examples come from different documents. The effect of NSP has been shown to be unreliable. The sentence-order prediction (SOP) task of ALBERT predicts whether a pair of segments are in correct order, in which the negative examples are from swapped contiguous segments. The small change of negative example source and the learning objective consistently improves performance for multi-sentence encoding downstream tasks, even after the parameter reduction that reduced performance. Also, removing dropout significantly improves both masked language modeling accuracy and downstream tasks performance.
ALBERT significantly outperforms the then state-of-the-art models RoBERTa and DCMN+ on benchmarks GLUE, SQuAD, and RACE, respectively.
ELECTRA
Clark et al., 2020[23] took another approach ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) to improve pre-training efficiency and downstream task performance of BERT. It addresses two problems of BERT: (1) the artificial token [MASK] used in pre-training is not used in fine-tuning, and (2) only a small subset (15%) of input tokens are used (masked) for pre-training. The first, also known as mismatch, problem, is solved by replacing masked tokens with plausible alternatives sampled from a small generator network. The second problem is solved by training a discriminative model that predicts whether each token in the corrupted input was replaced by a generator sample or not. The idea is named replaced token detection pre-training, as illustrated in the figure below. By learning from all input positions, ELECTRA trains much faster than BERT.
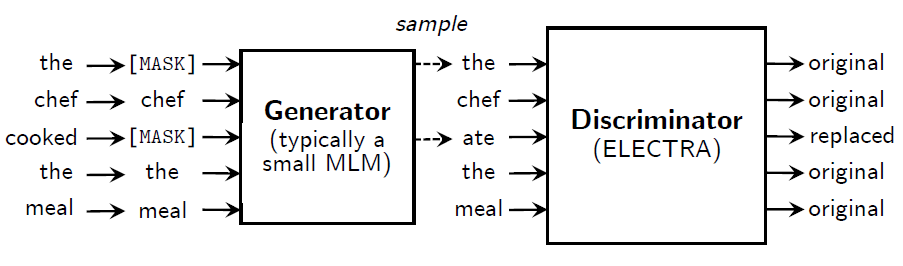
Both the generator \(G\) and the discriminator \(D\) consist of an encoder that maps a sequence of input tokens \(\mathbf{x}=[x_1,...,x_n]\) into a sequence of contextualized vector representations \(h(\mathbf{x})=[h_1,...,h_n]\). For a given masked position \(t\), the probability of generating the token \(x_t\) with a softmax layer at the generator output is
\[p_G(x_t|\mathbf{x})=\frac{\exp(e(x_t)^{\top}h_G(\mathbf{x})_t)}{\sum_{x'}\exp(e(x')^{\top}h_G(\mathbf{x})_t)}\]where \(e\) denotes token embeddings. For a given position \(t\), the discriminator predicts whether the tokens \(x_t\) is from the real data rather than the generator distribution, with a sigmoid output layer:
\[D(\mathbf{x},t)=\mathrm{sigmoid}(w^{\top}h_D(\mathbf{x})_t)\]The generator is trained to perform masked language modeling that first selects, from an input \(\mathbf{x}=[x_1,...,x_n]\), a random set of positions \(\mathbf{m}=[m_1,...,m_k]\) to mask out, where \(k=0.15n\). Then, the selected tokens are replaced with [MASK] tokens, which is denoted as \(\mathbf{x}^{\mathrm{masked}}=\mathtt{REPLACE}\)(\(\mathbf{x}\),\(\mathbf{m}\),[MASK]). Then, the generator learns to predict the original identities of the masked tokens. Then, a corrupted example \(\mathbf{x}^{\mathrm{corrupt}}\) is created by replacing the masked-out tokens with generator samples. Finally, the discriminator is trained to predict which tokens in \(\mathbf{x}^{\mathrm{corrupt}}\) match the original input \(\mathbf{x}\). Model inputs are constructed according to
\(m_i\sim\mathrm{unif}\{1,n\}\) for \(i=1\) to \(k \qquad\qquad \mathbf{x}^{\mathrm{masked}}=\mathtt{REPLACE}\)(\(\mathbf{x}\),\(\mathbf{m}\),[MASK])
\(\hat{x}_i\sim p_G(x_i\)|\(\mathbf{x}^{\mathrm{masked}})\) for \(i\in\mathbf{m} \qquad\qquad \mathbf{x}^{\mathrm{corrupt}}=\mathtt{REPLACE}\)(\(\mathbf{x}\),\(\mathbf{m}\),\(\hat{\mathbf{x}}\))
and the loss functions are
\[\mathcal{L}_{\mathrm{MLM}}(\mathbf{x},\theta_G)=\mathrm{\mathbb{E}}\bigg(\sum\limits_{i\in\mathbf{m}}-\log p_G(x_i|\mathbf{x}^{\mathrm{masked}})\bigg)\] \[\mathcal{L}_{\mathrm{Disc}}(\mathbf{x},\theta_D)=\mathrm{\mathbb{E}}\bigg(\sum\limits_{t=1}^n -\mathbb{1}(x_t^{\mathrm{corrupt}}=x_t)\log D(\mathbf{x}^{\mathrm{corrupt}},t)-\mathbb{1}(x_t^{\mathrm{corrupt}}\neq x_t)\log(1-D(\mathbf{x}^{\mathrm{corrupt}},t)) \bigg)\]The combined loss is minimized over a large corpus \(\mathcal{X}\) of raw text.
\[\underset{\theta_C,\theta_D}{\min}\;\sum\limits_{\mathbf{x}\in\mathcal{X}} \mathcal{L}_{\mathrm{MLM}}(\mathbf{x},\theta_G)+\lambda \mathcal{L}_{\mathrm{Disc}}(\mathbf{x},\theta_D)\]The expectations in the losses are approximated with a single sample. The discriminator loss cannot be back-propagated through the generator because of the sampling step. After pre-training, the generator is thrown out and only the discriminator is fine-tuned on downstream tasks.
GLUE and SQuAD benchmarks are used for evaluation. For fine-tuning on GLUE and SQuAD, simple linear classifiers and the question-answering module from XLNet, respectively, are added on top of ELECTRA. Both the token embeddings and positional embeddings are shared between the generator and the discriminator, using the size of the discriminator’s hidden states. The ELECTRA models work best with generators \(1/4\sim 1/2\) the size of the discriminator, in terms of layer sizes (number of hidden units) while keeping the other hyperparameters constant.
ELECTRA-Large models are the same size as BERT-Large but are trained for much longer. ELECTRA-400K is trained for 400k steps, roughly \(1/4\) the pre-training compute of RoBERTa. ELECTRA-1.75M is trained for 1.75M steps, similar compute to RoBERTa. ELECTRA outperforms XLNet and RoBERTa of the same size on GLUE and SQuAD benchmarks, but with less pre-training compute. ELECTRA is greatly benefitted from having a loss defined over all input tokens rather than just 15% of the tokens. A large amount of ELECTRA’s improvement can be attributed to learning from all tokens and a smaller amount can be attributed to alleviating the pre-train fine-tune mismatch. ELECTRA’s pre-training objective is more compute-efficient and results in better performance on downstream tasks.
Permutation Language Models
XLNet
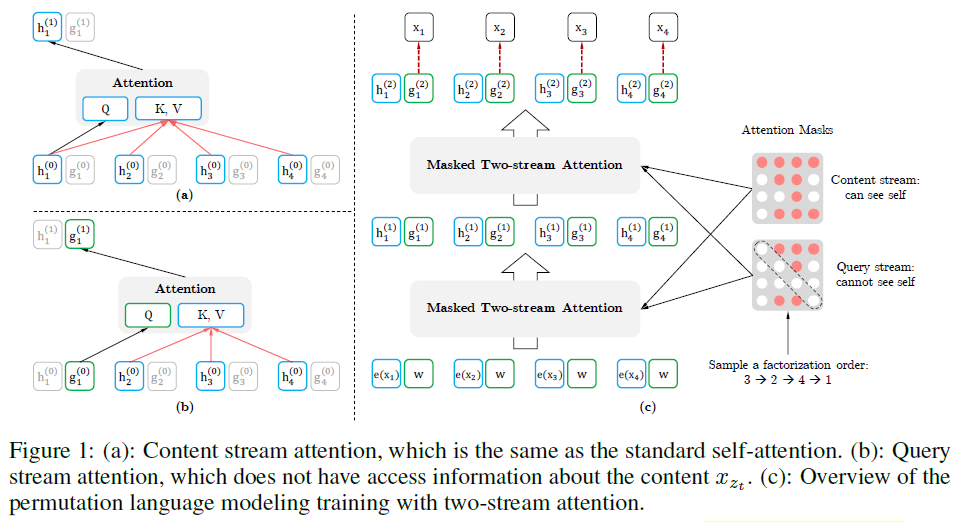
The standard language modeling in GPT cannot capture relationship to right-hand side tokens, which may be required by downstream tasks. On the other hand, the masked language modeling in BERT cannot capture relationship between masked tokens in the same input sequence during pre-training and does not have the artificial token [MASK] in the input data of fine-tuning tasks. To overcome the drawbacks in both approaches, Yang et al., 2019[16] introduced XLNet, a permutation language modeling method with two-stream self-attention architecture. The objective functions of the three types of language modeling are compared below. With all possible permutations of a token sequence, the relationship to right-hand side tokens in the original sequence can be learned by autoregressive approach. The original sequence order is preserved by positional encodings.
There are two sets of hidden representations used in this model, dependent on whether the content \(x_{z_{t}}\) at the position \(z_{t}\) is used or not. The content representation \(h_{z_{t}}=h_{\theta}(\mathrm{\mathbf{x}}_{\leq t})\) encodes both the left context and \(x_{z_{t}}\) itself, similar to the standard hidden states in Transformer. The query representation \(g_{z_{t}}=g_{\theta}(\mathrm{\mathbf{x}}_{\lt t}, z_{t})\) encodes the left context and the position \(z_{t}\), but not \(x_{z_{t}}\). The next token distribution \(\mathit{p}_{\theta}(x_{z_{t}} |\mathrm{\mathbf{x}}_{\mathrm{\mathbf{z}}_{\lt t}})=\frac{exp(e(x_{z_{t}})^{\top}g_{z_{t}})}{\sum_{x'} exp(e(x')^{\top}g_{z_{t}})}\), where \(e(x)\) is the embedding of \(x\). For each attention layer \(m=1,..., M\), the two streams of representations are schematically updated with a shared set of parameters as follows: query stream \(g_{z_{t}}^{(m)}\leftarrow Attention(Q=g_{z_{t}}^{(m-1)}, KV=h_{\mathrm{\mathbf{z}}_{\lt t}}^{(m-1)};\theta)\), content stream \(h_{z_{t}}^{(m)}\leftarrow Attention(Q=h_{z_{t}}^{(m-1)}, KV=h_{\mathrm{\mathbf{z}}_{\leq t}}^{(m-1)};\theta)\), as illustrated in the figure below.
To reduce time to convergence, only the right-most tokens (\(t\gt c\)) of a permutation \(\mathrm{\mathbf{z}}\) are used as targets for prediction. A hyperparameter \(K\approx \left\lvert{\mathrm{\mathbf{z}}}\right\rvert/(\left\lvert{\mathrm{\mathbf{z}}}\right\rvert-c)\) is used to determine the target subsequence. For non-target tokens, their query representations do not need to be computed. The \(K=6\) is used in the experiments of this study.
To enable capturing longer-term dependency, two techniques from Transformer-XL[17] are integrated: the relative positional encoding scheme and the segment recurrence mechanism. The relative positional encoding is done by relative distance between two positions, which is required for the segment recurrence mechanism. The input is divided into multiple equal length segments. During training, the hidden state sequence computed for the previous segment is fixed (stop-gradient) and cached to be reused (concatenated with the next segment’s hidden state) as an extended context when the model processes the next new segment. This segment-level recurrence avoids context fragmentation problem and speeds up training and evaluation. Unlike the same-layer recurrence in RNN, the segment recurrence here feeds to the next layer. Therefore, the largest possible dependency length grows with the number of layers as well as the segment length.
The XLNet has the same architecture hyperparameters as BERTLarge. Trained on the same datasets and hyperparameters with an almost identical training recipe, XLNet outperforms BERTLarge by a considerable margin on all the tested tasks, including GLUE, text classification, reading comprehension (RACE), document ranking (ClueWeb09-B), and question answering (SQuAD) tasks. Trained on the same full data and the hyperparameters of RoBERTa, XLNet generally outperforms RoBERTa on RACE, ClueWeb09-B, SQuAD, and GLUE tasks.
Denoising Language Models
All the models mentioned above use either encoder-only or decoder-only Transformers, which limit the applicable mappings from inputs to outputs. By contrast, using sequence-to-sequence models on encoder-decoder Transformers allows arbitrary mappings from noisy to clean sequences, such as deletion, infilling, rotation, and permutation. Denoising language models are trained by corrupting documents and then optimizing a reconstruction loss, the cross-entropy between the decoder’s output and the original document.
T5
Raffel et al., 2020[18] introduce Text-to-Text Transfer Transformer (T5) model that uses encoder-decoder architecture of the transformer and unifies the input and output format of all the downstream tasks, as illustrated below, so that multi-task learning can be done easily for all tasks at once. They also systematically compare different architectures, unsupervised objectives, pre-training dataset sizes, task training strategies, and scaling to gain insight on optimal modeling choices.
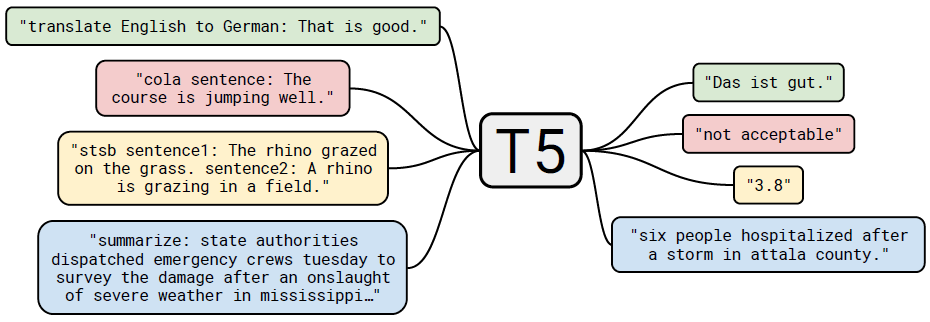
The T5 encoder-decoder architecture is largely the same as the transformer, with the exception of removing the bias term in layer normalization, placing the layer normalization outside of residual path, and using a simplified form of positional embedding. The pre-training dataset is named Colossal Clean Crawled Corpus (C4) that is 750GB of web extracted text, derived from one month of Common Crawl dataset with a series of cleaning, filtering, and deduplication. Every task is treated as a text-to-text problem where some text for context or conditioning is fed into the encoder and some output text is generated by the decoder. The text-to-text framework provides consistent model, objective, training procedure, and decoding process, regardless of the task. A task-specific prefix (as in the figure above) is added to the original input sequence to indicate which task the model should perform. There are 18 tasks in this study.
The T5 baseline model’s encoder and decoder are each similar in size and configuration to the BERTBASE that consists of 12 layers, 12 heads per layer, dmodel=768, dKV=64, dff=3072, and about 220 million parameters (twice the number of parameters of BERTBASE). The pre-training uses a vocabulary of 32,000 wordpieces. The pre-training objective (named denoising objective in this study) is to predict dropped-out tokens in the input sequence. 15% of tokens are randomly dropped out and replaced by special sentinel tokens. The target is the combination of all the dropped-out spans of tokens, delimited by the corresponding sentinel tokens. Training always uses standard maximum likelihood and a cross-entropy loss; and testing uses greedy decoding. Pre-training runs for \(2^{19}\) steps on C4, with batch size of 128 and maximum length of 512, which results in pre-training on \(2^{35}\approx 34B\) tokens, a fraction of the C4 dataset. Fine-tuning runs for \(2^{18}\) steps on all tasks and validation is done every 5000 steps. Results are reported based on highest validation performance per task. Overall, the performance of T5 baseline model is comparable to existing models of similar size, such as BERTBASE.
Five architectural variants are compared: (1) the T5 baseline encoder-decoder, (2) equivalent encoder-decoder but with shared parameters, (3) encoder-decoder but with only 6 layers each, (4) decoder-only language model, (5) decoder-only prefix language model. The prefix language model uses fully-visible masking on the prefix portion of the sequence and causal masking for target portion. For example, during training for input sequence “translate English to German: That is good. target:” and target sequence “Das ist gut.”, fully-visible masking is applied to the former and causal masking is applied to the latter. Also, for each of the five architectural variants, two objectives are compared: (1) the baseline model’s denoising objective and (2) standard language model objective. In the latter case, the input and target are concatenated and the entire span is predicted from beginning to end. The results show that models using a denoising objective always perform better than the corresponding ones using a language model objective. For all tasks, the T5 baseline encoder-decoder with the denoising objective performed the best, and sharing parameters across encoder and decoder performed nearly as well. The two decoder-only variants performed significantly worse than encoder-decoder variants, suggesting that the addition of an explicit encoder-decoder attention is beneficial.
Using the encoder-decoder architecture, three disparate objectives are compared: (1) BERT-style Masked LM (10% of masked tokens replaced by random tokens), (2) Prefix LM, and (3) Deshuffling (input sequence is shuffled and deshuffled original sequence is used as target). The BERT-style objective performs best. Three additional variants of BERT-style objectives are further compared: (1) MASS-style (all masked tokens replaced by <MASK>), (2) consecutive masked tokens (span) replaced with single sentinel token (used by T5 baseline above), and (3) the masked tokens are dropped without replacements. The targets of both BERT-style and MASS-style are the entire original text; the targets of the latter two are the masked tokens only. All the three variants perform similarly to BERT-style objective. The span replacement variant is chosen for the rest of study, due to shorter target length and less processing. The token masking rates of 10%, 15%, 25%, and 50% are compared; but they had limited effect on model performance. 15% is used for the rest of the study. The average span lengths of 2, 3, 5, 10 are compared with the baseline model’s random masking approach. Overall, the differences are limited and the baseline model’s objective is chosen for the rest of study, due to shorter target length and less processing.
The cleaning, filtering, and deduplication steps in producing C4 dataset reduced size from 6.1TB to 745GB and improved performance of downstream tasks uniformly. Some domain-specific subsets of C4 or other corpora much smaller than C4 outperformed C4 in some downstream tasks, when the smaller pre-training datasets contain in-domain data of the tasks. When C4 is artificially truncated to various smaller sizes, corresponding to repeating data during pre-training for 64, 256, 1,024, and 4,096 times, the performance degrades as the dataset size shrinks, due to overfitting. Therefore, the authors suggest using large pre-training datasets whenever possible.
In the baseline model, the fine-tuning stage updates all parameters. Two partial parameter update strategies are compared: (1) adding an adapter layer (dense-ReLU-dense) after each feed-forward network in each block of the transformer and only updating parameters in the adapter layers and layer normalization, (2) gradual unfreezing that unfreezes layers for parameter update from the last layer to the first layer gradually. Both of the partial update strategies caused performance degradation. Also, multi-task training is examined, where both unlabeled dataset and supervised downstream task dataset are mixed in a single stage training. Three different data mixing strategies are compared: (1) examples-proportional mixing (sampling in proportion to the size of each task’s dataset, sampling rate of the mth task \(r_{m}=\min(e_{m},K)/\sum \min(e_{n},K)\), where e is the number of examples and K is an artificial dataset size limit), (2) temperature-scaled mixing (sampling rate of the mth task = \(r_{m}^{\frac{1}{T}}/\sum r_{n}^{\frac{1}{T}}\), where \(r_{m}\) is the same as in the (1)), and (3) equal mixing (sampling from each task with equal probability). In general, multi-tasking training underperforms pre-training followed by fine-tuning on most tasks. To close the gap between multi-tasking training and pre-training followed by fine-tuning, three different strategies of multi-task pre-training followed by fine-tuning are compared: (1) examples-proportional multi-task pre-training (with \(K=2^{19}\)) followed by task-specific fine-tuning, (2) same multi-task pre-training as in (1) except that one downstream task is excluded in the pre-training but used for fine-tuning (leave-one-out multi-task training), and (3) same multi-task pre-training as in (1) except that unsupervised task is excluded (supervised multi-task pre-training). The (1) strategy, multi-task pre-training followed by fine-tuning, results in comparable performance to the T5 baseline, but the (2) and (3) strategies perform slightly and significantly, respectively, worse than the baseline.
Finally, different ways of scaling up the baseline model are compared: (1) \(4\times\) training steps, (2) \(2\times\) training steps and \(2\times\) bigger (by number of parameters), (3) \(4\times\) bigger, (4) \(4\times\) larger batch sizes, (5) ensemble of 4 separately pre-trained and fine-tuned models, and (6) single pre-trained model and 4 separately fine-tuned models for ensemble. All the 6 ways of scaling up improved performance over the baseline on all the tasks, except the 2 ensemble methods on SuperGLUE task. There was no clear winner between training for \(4\times\) as many steps or using a \(4\times\) larger batch size. The \(4\times\) bigger model appeared to slightly outperform the \(4\times\) training steps model. However, using a larger model can make downstream fine-tuning and inference more expensive.
Combining the insights above, the authors put together their best model named T5-11B with the configuration: 24-layer encoder-decoder, 128 heads per layer, dmodel=1,024, dKV=128, dff=65,536, and about 11 billion parameters. The span-corruption objective is used with 15% corruption rate and mean span length of 3. The pre-training is run for 1 million steps with a batch size of \(2^{11}\) sequences of length 512, corresponding to a total of about 1 trillion pre-training tokens. The pre-training is run on a multi-task examples-proportional mixing. During fine-tuning, a smaller batch size of 8 and length of 512 are used. Overall, T5-11B achieved state-of-the-art performance on 18 out of the 24 tasks.
BART
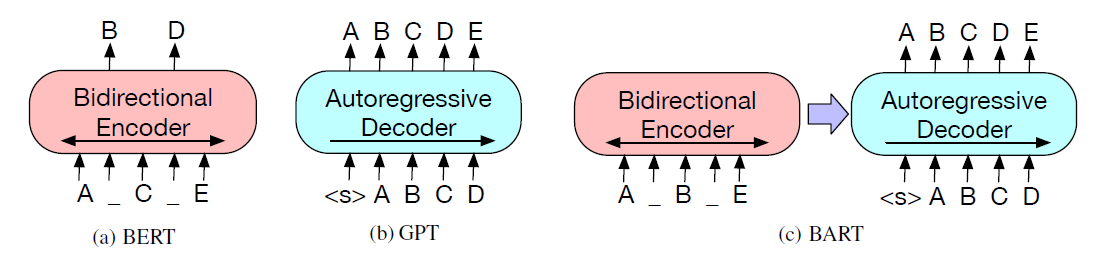
Lewis et al., 2020[19] introduce Bidirectional and Auto-Regressive Transformers (BART) model that is a denoising autoencoder built with the encoder-decoder architecture of the transformer. The bidirectional encoder takes in a corrupted text and the left-to-right autoregressive decoder generates the corresponding clean text. The figure below illustrates the main difference between BERT, a masked LM, GPT, a standard autoregressive LM, and BART, a denoising LM.
The pre-training optimizes the negative log likelihood of the original document. BART-base and BART-large use 6 and 12 layers, respectively, in each of the encoder and decoder. BART differs from BERT in two ways: (1) each layer of the decoder performs additional cross-attention over the final hidden layer of the encoder; and (2) BART does not have an additional feed-forward network before word prediction. BART contains roughly 10% more parameters than the equivalently sized BERT model.
BART allows any type of document corruption. Five types of noising approaches, as illustrated below, are experimented: (1) token masking, where random tokens are sampled and replaced with [MASK] elements; (2) token deletion, where random tokens are deleted from the input and the model must decide which positions are missing inputs; (3) text infilling, where a number of text spans are sampled with length drawn from a Poisson distribution and each span is replaced with a single [MASK] token; (4) sentence permutation, where sentences are shuffled in a random order; (5) document rotation, where a token is chosen uniformly at random and the document is rotated so that it begins with that token.
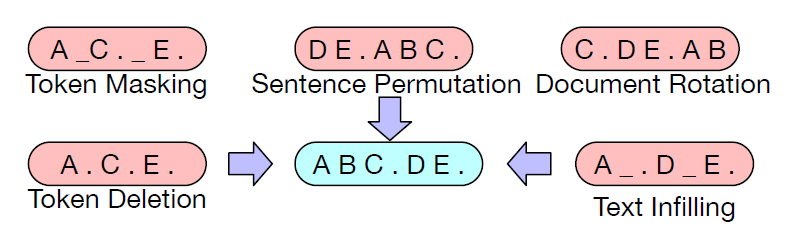
The sentence permutation and document rotation approaches perform poorly. Token masking and token deletion perform next to the best, with token deletion better than token masking on generation tasks. The text infilling approach shows the most consistenly strong performance.
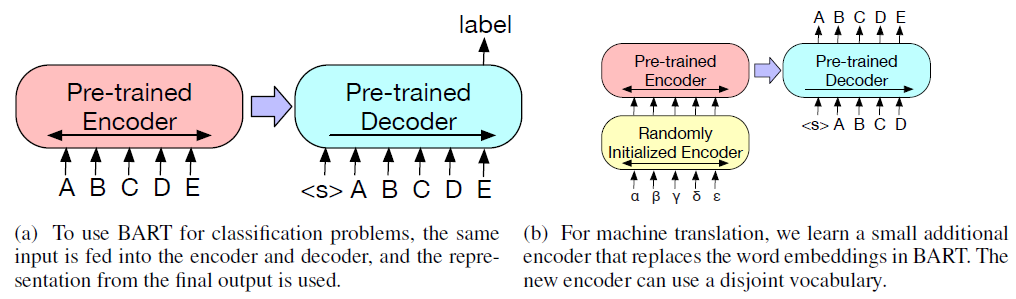
BART can be fine-tuned for 4 types of downstream tasks: (1) sequence classification (Figure (a) below), where the final hidden state of the final decoder token is fed into a multi-class linear classifier; (2) token classification, where the top hidden state of the decoder is used as a representation for each word and the representation is used to classify the token; (3) sequence generation, such as abstractive question answering and summarization, where the decoder generates output autoregressively; (4) machine translation, where BART’s encoder embedding layer is replaced with a new randomly initialized encoder (Figure (b) below) that translates a foreign language to noised target language that in turn serves as inputs to the entire BART as a single pre-trained decoder.
For large-scale pre-training experiments, BART-large model with 12 layers, hidden size of 1024, and batch size of 8000 is trained for 500K steps. Documents are tokenized with the same byte-pair encoding as GPT-2. Document noising is done with a combination of text infilling and sentence permutation. The pre-training data consist of 160GB of news, books, stories, and web text.
On classification tasks, SQuAD and GLUE tasks, BART performs similarly to RoBERTa and XLNet. On two standard summarization tasks, CNN/DailyMail and XSum, BART outperforms all previous work, but does not reach human performance on XSum. For dialogue response generation on CONVAI2, with response conditioned on both the previous context and a textually-specified persona, BART outperforms previous work. For abstractive QA task on the EL15 dataset that expects long free-form answers, BART outperforms the best previous work by 1.2 ROUGE-L. For translation using WMT16 Romanian-English dataset, BART outperforms Transformer only if it is pre-trained in English.
BART and T5 use slightly different training objective for masked spans in the inputs: BART reconstructs the complete input, but T5 only predicts the sequence of corrupted tokens. This may give BART some advantage on text generation task. BART achieves higher performance than T5 with similar model sizes, particularly on summarization tasks.
Multilingual Extensions
All the transformer-based language models are first developed only for English language. Many single non-English language models have been developed by pre-training the same model architectures with a non-English corpus. Some studies have extended these models to handle multiple languages simultaneously. Three examples, mBART, MARGE, and mT5, are reviewed here. mBART and mT5 are multilingual variants of BART and T5, respectively. mBART is evaluated by machine translation tasks, while mT5 is evaluated by language understanding tasks. MARGE introduces a novel multilingual paraphrases-based denoising language model for both language generation and classification tasks.
mBART
Liu et al., 2020[24] introduce mBART that is trained by applying the BART to 25 large-scale monolingual corpora. The pre-training dataset CC25 is a subset of 25 languages extracted from the Common Crawl (CC). The amount of text from each of the 25 languages in CC25 varies widely, which are re-balanced by up/down-sampling from each language \(i\) with a ratio \(\lambda_i\):
\[\lambda_i=\frac{1}{p_i}\cdot\frac{p_i^{\alpha}}{\sum_{i}p_i^{\alpha}},\]where \(p_i\) is the percentage of each language in CC25 and the smoothing parameter \(\alpha=0.7\). Tokenization is done using language independent SentencePiece model learned on the full CC data that includes 250,000 subword tokens. mBART models follow BART’s architecture, with 12 layers of encoder, 12 layers of decoder, model dimension of 1024, and 16 heads. An additional layer-normalization layer is added on top of both the encoder and decoder to help stabilizing training. The learning objective is to maximize \(\mathcal{L}_{\theta}\) for all training documents in all languages:
\[\mathcal{L}_{\theta}=\sum\limits_{\mathcal{D}_i\in\mathcal{D}}\sum\limits_{X\in\mathcal{D}_i}\log P(X|g(X);\theta),\]where \(\mathcal{D}_i\) is a collection of monolingual documents in language \(i\), \(\mathcal{D}\) is the collection of \(\mathcal{D}_i\) in CC25, \(g\) is a noising function, and \(P\) is the distribution of the original text \(X\) given \(g(X)\), defined by the Seq2Seq model. There are two types of noise in \(g\): (1) 35% of the words in each document is masked by random sampling a span length according to a Poisson distribution (\(\lambda=3.5\)), and (2) the order of sentences within each document are permuted. The decoder input starts with a language ID symbol <LID> followed by the original text. The format for each instance of a batch is <LID>\(sentence_1\)</S>…\(sentence_n\)</S><LID>, where \(n\) is limited by document boundary or the 512 max token length.
Five types of pre-trained models are built in this study: (1) mBART25 is pre-trained on all 25 languages; (2) mBART06 is pre-trained on six European languages, Ro, It, Cs, Fr, Es, and En; (3) mBART02 is pretrained on two languages, En-De, En-Ro, En-It; (4) monolingual BART models as baseline, BART-En and BART-Ro; (5) an additional baseline, Random, model that is randomly initialized without pre-training. All models use the same vocabulary. Three types of downstream tasks are conducted in this study: (1) sentence-level machine translation, (2) document-level machine translation, and (3) unsupervised machine translation. The figure below illustrates the pre-training and fine-tuning scheme with simple examples.
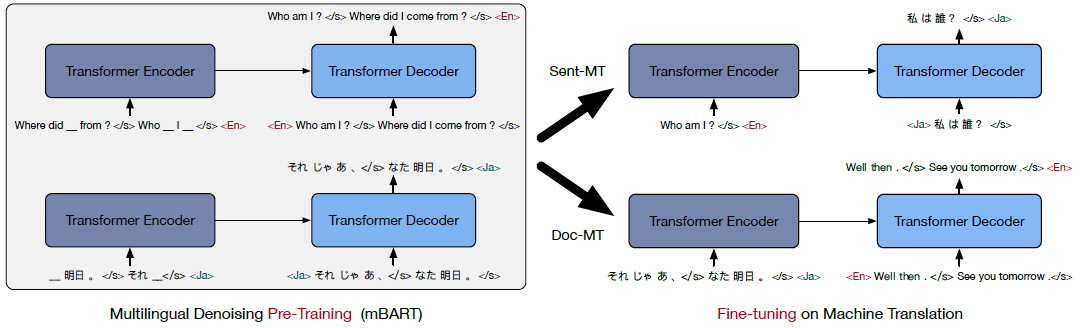
Sentence-level machine translation dataset contains 24 pairs of En\(\leftrightarrow\)X bilingual sentence pairs, covering all 25 languages in CC25. They are divided into three categories, based on the number of sentence pairs: low resource (\(<1M\)), medium resource (\(>1M\) and \(<10M\)), and high resource (\(>10M\)). Models initialized with the pre-trained mBART25 weights show gains on all the low and medium resource pairs when compared with randomly initialized baselines. However, there is no consistent gains for high resource cases. Back-translation is to translate the target monolingual data to generate source data as additional training data. mBART25 pre-trained parameters improve performance at each iteration of back-translation, resulting in new state-of-the-art results. When pre-training dataset contains languages other than the targeted language pair used in fine-tuning, the performance improves most when the target language monolingual data is limited and hurts slightly when monolingual data is plentiful. mBART25 is consistently slightly worse than mBART02. mBART can improve performance even with fine tuning for languages that did not appear in the pre-training corpora, suggesting that the pre-training has language universal aspects.
Document-level machine translation task is to translate segments of text that contain more than one sentence, up to an entire document, allowing the models to learn dependencies between sentences. During pre-training, document fragments of up to 512 tokens are used. Two common document-level machine translation datasets, WMT19 En-De and TED15 Zh-En, are used to evaluate performance. The model does not know how many sentences to generate in advance and decoding stops when <LID> is predicted. Beam size 5 is used by default. Corresponding sentence-level translation model is used as baseline. The machine translation models initialized with pre-trained weights outperform randomly initialized models by large margins for both sentence-level and document-level training. With pre-trained weights initialized, mBART25 Doc-MT models outperform Sent-MT models by a margin. With random initialization, Doc-MT models fail to work, resulting in much worse performance than the Sent-MT models. These opposite results indicate that pre-training is critical for document-level performance.
An unsupervised machine translation task is when no bi-text is available for the target language pair. Two types of unsupervised machine translation tasks, as illustrated in the figure below, are investigated in this study: (1) learning from on-the-fly back-translation, (2) language transfer where models fine-tuned on \(X\rightarrow En\) are used to evaluate \(Y\rightarrow En\). For both cases, the models are initialized from multilingual pre-training (e.g. mBART25).
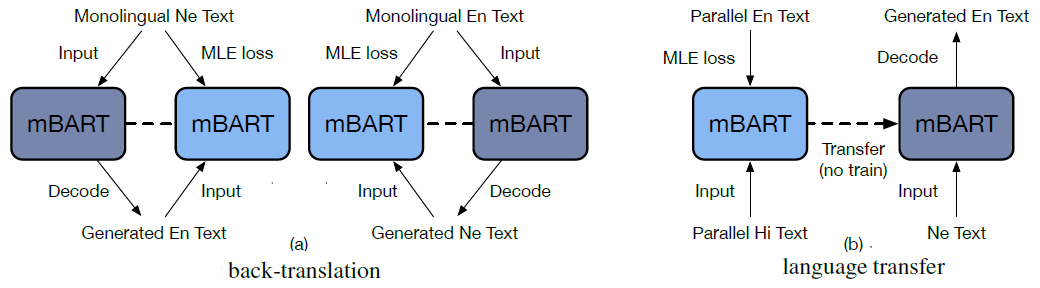
Language pairs are divided into similar pairs, such as En-De and En-Ro, and dissimilar pairs, such as En-Ne and En-Si, based on the subword units that are shared between the source and target languages. For unsupervised machine translation via back-translation, mBART models achieve large gains over XLM on dissimilar pairs and perform competitively against XLM and MASS on similar pairs. For unsupervised machine translation via language transfer, mBART achieves similar or even much better results in some pairs, compared to the supervised results. This indicates that multilingual pre-training is essential and produces universal representations across languages, so that once the model learns to translate one language to En, it learns to translate all languages with similar representations. Language transfer works better when fine-tuning is also conducted in the same language family. However, significant vocabulary sharing is not required for effective transfer. None of the two unsupervised approaches performs better than the other in all cases, while combining the two approaches achieves consistent improvement over each of them.
MARGE
Lewis et al., 2020[25] introduce MARGE (Multilingual Autoencoder that Retrieves and Generates) that is a sequence-to-sequence model pre-trained with a self-supervised multilingual multi-document paraphrasing objective. The training involves reconstruction of target text by first retrieving a set of related texts in many languages and then conditioning on them to maximize the likelihood of generating the original. The retrieval model scores are used to bias the cross attention to the most relevant retrieved documents, allowing the retrieval model to be trained jointly from the reconstruction loss. MARGE can be viewed as a denoising autoencoder where the noise comes from the diversity of the retrieved documents that may have little lexical overlap with the target and may be in a different language, but should contain the same underlying information. This approach emphasizes paraphrasing and reduces the amount of encyclopedic knowledge the model must memorize. An example instance of the pre-training is illustrated in the figure below.
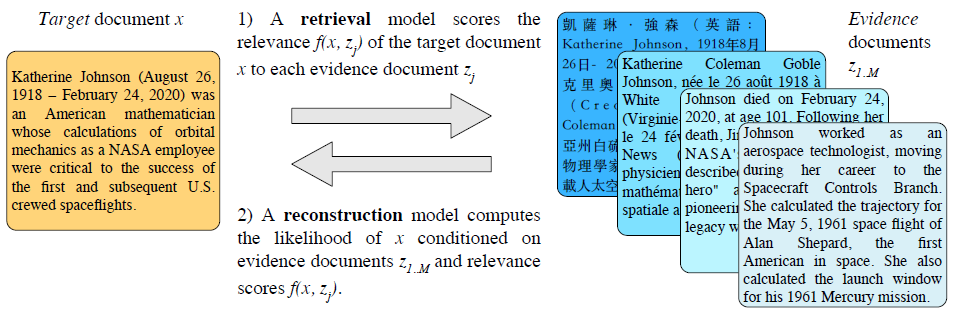
The pre-training input is a batch of evidence documents \(z_{1..M}\) and target documents \(x_{1..N}\) where a document refers to contiguous chunks of text up to maximum length of 512 tokens. The model is trained to maximize the likelihood of the targets, conditioned on the evidence documents and the relevance of each evidence document to each target.
The model first computes a relevance score \(f(x_i,z_j)\) between every pair of documents \(x_i\) and \(z_j\), as the cosine similarities of their embeddings:
\[f(x,z)=\frac{g(x)\cdot g(z)}{\|g(x)\| \|g(z)\|},\]where \(g\) is a document encoder that maps a document, i.e., a list of tokens, to a representation of a fixed size. The same encoder is applied to both target and evidence documents. In this study, documents are encoded by taking the representation of the first token from the top of a 4-layer Transformer.
The model then computes the likelihood of reconstructing each \(x_i\) conditioned on \(z_{1..M}\) and each \(f(x_i,\cdot)\), using a modified seq2seq model. The similarity score encourages the model to attend more to relevant evidence documents. Backpropagating the reconstruction loss therefore improves both the sequence-to-sequence model and the relevance model. The loss function of the construction model is
\[L_{\theta}=-\sum\limits_{i}\log p_{\theta}(x_i|z_{1..M},f(x_i,z_1),...,f(x_i,z_M))\]The similarity score is used to bias the cross-attention from the decoder to the encoder, so that the decoder will pay more attention to more relevant evidence documents. More relevant evidence documents will improve the likelihood of reconstructing \(x_i\), so gradient descent on the loss function will improve the quality of the similarity scores. Cross-attention probability over a set of evidence documents \(z_{1..M}\) is defined as
\[\alpha=softmax_{z_{1..M}}(Q^{lh}(x_i)K^{lh}(z_{1..M})+\beta f(x_i,z_j))\in\mathrm{\mathbb{R}}^{|x_i|\times\sum_j|z_j|}\]where \(Q^{lh}\) and \(K^{lh}\) compute query and key representations for layer \(l\) and head \(h\), \(softmax_{z_j}\) denotes a softmax normalized over elements of \(z_j\), and \(\beta\) is a trainable scalar parameter that weights the importance of the document similarity score.
Batches are constructed, using the relevance model for retrieval, to create evidence document sets \(z_{1..M}\) that are relevant to target documents \(x_{1..N}\). Simple heuristic constraints are used to divide documents into related shards, to improve both the accuracy and efficiency of retrieval. For news text, documents are in the same shard iff they were published on the same date. For Wikipedia, articles are split into chunks of length 512. All chunks from the same article or the equivalent article in another language are in the same shard. There are 1000 shards. Batch construction involves nearest neighbor search offline. A set of shards are sampled every 10K model updates; then, within each shard, \(f(x,z)\) is computed for every pair of target and evidence documents using the current relevance model and the top \(k\) most similar document pairs across all pairs in the shard are taken. Targets without sufficiently relevant, above a threshold, evidence documents are not used until the shard is re-indexed with an updated relevance model. The output from the thresholding step is a bipartite graph of evidence and target documents with edges between them. A small local search is done to find a subgraph maximizing the sum of the weights of all edges in the subgraph. To encourage the model to build multilingual batches, edges where the evidence and target are in different languages are given weight 100, and other edges have weight 1. The retrieval threshold is set to take on average 4 monolingual and 4 cross-lingual links per target document.
The reconstruction model uses Transformer architecture with 12-layer encoder of dimension 1024 and feedforward layers size \(d_{ff}\) = 4096. The decoder is scaled up to include \(d_{ff}\) = 16536 and 4 additional layers at the base of the decoder with only self-attention and \(d_{ff}\) = 4096, which allows words in the target to contextualize locally before the more expensive cross-attention and feed-forward layers. The relevance model uses the first 4 layers of the encoder and take the document representation from the beginning-of-sentence token.
The model pre-trained on the CC-NEWS corpus is referred to as MARGE-NEWS. The model with additional pre-training on Wikipedia data is referred to as MARGE. Documents in 26 different languages are selected and split into chunks of length 512. For the news domain, only the first chunk in each document is allowed to be used as a target and the rest as evidence. A language identifier token is prepended as the first decoder input, to control the output language. For generation downstream tasks, the task input is fed into the encoder, and the output is generated by the decoder. For classification downstream tasks, the task input is fed into both the encoder and decoder, and a representation is used from the decoder’s final layer hidden state. For zero-shot transfer learning, word embeddings and the first 4 decoder layers are frozen. This study focuses on 5 multilingual tasks.
For cross-lingual sentence retrieval task, a model must identify the correct translation of a sentence from a set of distractors. The performance is evaluated on BUCC2018 and Tatoeba datasets, without fine-tuning. Document representation is defined as the average embedding of the fifth encoder layer. On BUCC, MARGE outperforms other unsupervised models by almost 10 points. On Tatoeba, there is significant variation across languages, but overall, MARGE performs comparably to XLM-R and significantly better than other pre-trained models. These results suggest that MARGE pre-training objective learns an effective cross-lingual retrieval function.
For document level translation tasks, documents are segmented into chunks of 512 tokens for training and generation, and then translated chunks of the same document are concatenated for computing document-level BLEU scores. The performance is measured for both translation into English and out of English on WMT19 and IWSLT datasets. Zero-shot unsupervised document translation performance varies considerably by language. On supervised document translation, meaning fine-tuned by labeled bi-text, MARGE performs similarly to mBART.
For text summarization tasks, ROUGE-L scores on MLSum dataset are compared. MARGE-NEWS generates abstractive summaries that outperform an extractive mBERT model. For paraphrase detection task, PAWS-X dataset is used for models to determine whether two sentences are paraphrases. MARGE slightly outperforms the state-of-the-art model XLM-R at that time. For multilingual question answering tasks, MLQA dataset is used, in which models are trained on English SQuAD dataset and then tested in other languages. MARGE performs comparatively with the state-of-the-art model XLM-R at that time.
The reconstruction model of MARGE learned to translate and paraphrase information from its source, rather than memorize facts in its parameters. The retrieval model of MARGE learned to retrieve the highest proportion of documents within their own language, and to retrieve higher proportion of documents in geographically or linguistically related languages.
mT5
Xue et al., 2020[26] introduce mT5 that is a multilingual variant of T5, pre-trained on mC4 dataset that is a multilingual variant of C4. mC4 differs from C4 in four aspects: (1) C4 is from one month, but mC4 is from 71 months of Common Crawl web scrapes; (2) C4 keeps a page for a probability of \(\geqslant\)99% being English by langdetect, but mC4 keeps a page when the probability of its primary language by cld3 is \(\geqslant\)70%; (3) C4 filters out lines that do not end in an English terminal punctuation mark; but mC4 applied a “line length filer” that requires pages to contain at least three lines of text with 200 or more characters; (4) C4 is English only with 1 trillion tokens; but mC4 covers 101 languages (each contains \(\geqslant\)10,000 pages) with 6.3 trillion tokens.
mT5 improves upon T5 by (1) using GeGLU (Gaussian Error Gated Linear Unit)[27], instead of ReLU, as the activation function in the feed-forward network, (2) scaling \(d_{model}\) instead of \(d_{ff}\) in the larger models, and (3) pre-training on unlabeled data only without dropout. The numbers of source web pages of the 101 languages vary from > 3B of English to about 50K of Yoruba. To avoid unbalanced fitting per language in pre-training, the examples are sampled according to the probability \(p(L)\propto\) |\(L\)|\(^{\alpha}\), where \(p(L)\) is the probability of sampling text from a given language, |\(L\)| is the number of examples in the language, and \(\alpha\) is sampling exponent, a hyperparameter, chosen as \(\alpha\) = 0.3 in this study. mT5 uses SentencePiece wordpiece models that are trained with the same language sampling rates used in pre-training. The vocabulary size is 250,000 wordpieces. Otherwise, mT5 follows T5 on the pre-training objective, model architecture, scaling strategy, and many other design choices.
The 6 tasks from EXTREME multilingual benchmark are used to evaluate the mT5 models: 2 sentence-pair classification tasks (entailment on XNLI (14) and paraphrase detection on PAWS-X (7)), 3 question answering tasks (XQuAD (10), MLQA (7), and TyDiQA (11)), and a structured prediction task (named entity recognition on WikiAnn (40)), where the number following each dataset indicates the number of languages covered. All tasks are cast into text-to-text format to generate the label text for XNLI and PAWS-X, entity tags and labels for WikiAnn NER, or answer for XQuAD, MLQA, and TyDiQA. Two variants of these tasks are also considered: (1) zero-shot where the model is fine-tuned only on English, (2) translate-train where the model is fine-tuned on language machine-translated from English. Five model sizes are considered: Small (\(\approx\)300M parameters), Base (600M, close to mBART’s 680M), Large (1B, close to MARGE’s 960M), XL (4B), and XXL (13B). The models are pre-trained for 1 million steps on batches of 1024 and input length of 1024. mT5-XXL reaches new state-of-the-art on all the 6 tasks in both cross-lingual zero-shot transfer setting and translate-train setting. For the two tasks (PAWS-X, MLQA) that are evaluated by both mT5 and MARGE, mT5-XXL (89.2, 75.5) significantly outperforms MARGE (86.5, 71.0). These results highlight the importance of model capacity in cross-lingual representation learning. This study also confirms previous observation that massively multilingual models underperform on a given language when compared with a similarly-sized monolingual model of the given language.
Retrieval-Augmented Language Models
In all the models discussed above, the learned knowledge is stored implicitly in the parameters of the models. Alternatively, knowledge from a large corpus can be explicitly retrieved by a retriever component of a language model during pre-training, fine-tuning, and inference. Four examples, REALM, RAG, FiD, and Retriever-Enhanced FiD, are reviewed here. REALM uses BERT’s encoder as an autoencoding generator, while RAG, FiD, and Retriever-Enhanced FiD use BART’s or T5’s seq2seq model as an autoregressive generator.
REALM
Guu et al., 2020[21] introduce the first REALM (REtrieval-Augmented Language Model) that has a knowledge-retriever jointly pre-trained with a knowledge-augmented encoder. The overall idea of REALM is illustrated in the figure below. For pre-training, the task is masked language modeling, where an input sentence \(x\) from a pre-training corpus \(\mathcal{X}\) contains some masked tokens and the output \(y\) contains the tokens predicted for the masked positions by the model. For fine-tuning, the task is Open-QA, where \(x\) is a question and \(y\) is the answer.
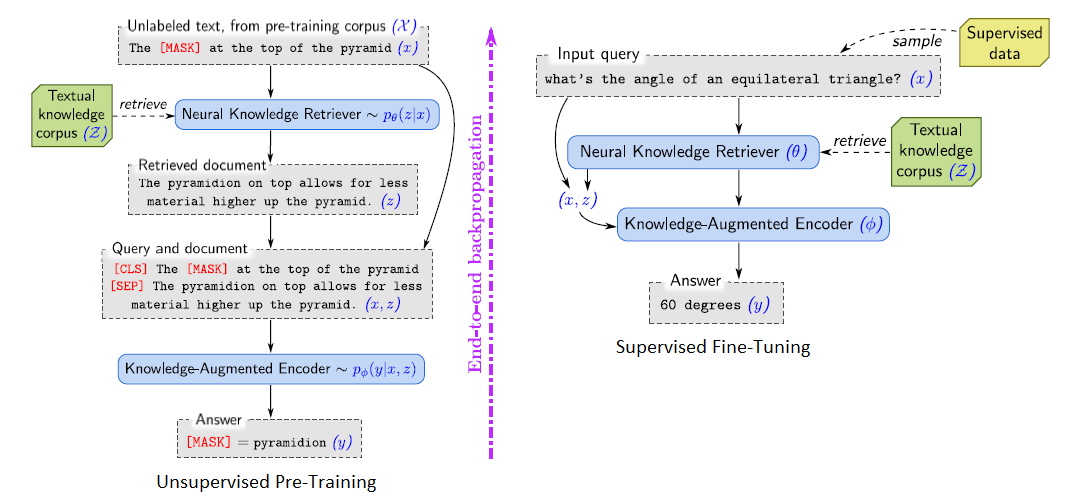
REALM is composed of two components: (1) the neural knowledge retriever that models \(p(z|x)\), the probability of retrieving document \(z\) from a knowledge corpus \(\mathcal{Z}\), and (2) the knowledge-augmented encoder that models \(p(y|z,x)\), the probability of generating \(y\) conditioned on both the retrieved \(z\) and the original input \(x\). To obtain the overall likelihood of generating \(y\), the \(z\) is treated as a latent variable and marginalized over, resulting in
\[p(y|x)=\sum\limits_{z\in\mathcal{Z}}p(y|z,x)p(z|x).\]The retriever is defined as the softmax over all relevance scores \(f(x,z)\) that is the inner product of the embeddings of \(x\) and \(z\).
\[p(z|x)=\frac{\exp f(x,z)}{\sum_{z'}\exp f(x,z')},\] \[f(x,z)=\mathrm{Embed}_{\mathrm{input}}(x)^\top\mathrm{Embed}_{\mathrm{doc}}(z).\]BERT is used to implement the embedding functions on inputs from joining spans of wordpiece tokens, including the prefix token [CLS] for pooled representation of the sequence and the separator token [SEP]. The output of BERT is linearly projected by a matrix \(\mathrm{W}\) to reduce the dimensionality of the vector.
\[\mathrm{Embed}_{\mathrm{input}}(x)=\mathrm{W}_{\mathrm{input}}\mathrm{BERT}_{\mathrm{CLS}}(\mathrm{join}_{\mathrm{BERT}}(x))\] \[\mathrm{Embed}_{\mathrm{doc}}(z)=\mathrm{W}_{\mathrm{doc}}\mathrm{BERT}_{\mathrm{CLS}}(\mathrm{join}_{\mathrm{BERT}}(z_{\mathrm{title}},z_{\mathrm{body}}))\], where \(\mathrm{join}_{\mathrm{BERT}}(x)=\)[CLS]\(x\)[SEP] and \(\mathrm{join}_{\mathrm{BERT}}(x_1,x_2)=\)[CLS]\(x_1\)[SEP]\(x_2\)[SEP]. \(\theta\) is used to denote all parameters, including the Transformer and the projection matrices, of the retriever.
The encoder behaves differently for pre-training and fine-tuning. For pre-training, the masked language modeling task is to predict the original tokens at the masked positions.
\[p(y|z,x)=\prod\limits_{j=1}^{J_x}p(y_j|z,x)\] \[p(y_j|z,x)\propto\exp(w_j^{\top}\mathrm{BERT}_{\mathrm{MASK}(j)}(\mathrm{join}_{\mathrm{BERT}}(x,z_{\mathrm{body}})))\], where \(J_x\) is the total number of [MASK] tokens in \(x\), \(w_j\) is a learned word embedding for token \(y_j\), and \(\mathrm{BERT}_{\mathrm{MASK}(j)}\) denotes the Transformer output vector corresponding to the \(j^{th}\) masked token. For Open-QA fine-tuning, it is assumed that the answer string \(y\) can be found as a contiguous sequence of tokens in a document \(z\) and \(S(z,y)\) is the set of spans matching \(y\) in \(z\). Then,
\[p(y|z,x)\propto\sum\limits_{s\in S(z,y)}\exp(\mathrm{MLP}([h_{\mathrm{START(s)}};h_{\mathrm{END(s)}}]))\] \[h_{\mathrm{START(s)}}=\mathrm{BERT}_{\mathrm{START(s)}}(\mathrm{join}_{\mathrm{BERT}}(x,z_{\mathrm{body}}))\] \[h_{\mathrm{END(s)}}=\mathrm{BERT}_{\mathrm{END(s)}}(\mathrm{join}_{\mathrm{BERT}}(x,z_{\mathrm{body}}))\], where \(\mathrm{MLP}\) denotes a feed-forward neural network and \(\mathrm{BERT}_{\mathrm{START(s)}}\) and \(\mathrm{BERT}_{\mathrm{END(s)}}\) denote the Transformer output vectors corresponding to the start and end tokens of span \(s\), respectively. \(\phi\) is used to denote all parameters of the knowledge-augmented encoder.
For both pre-training and fine-tuning, the model is trained to maximize the log-likelihood \(\log p(y\)|\(x)\) of the correct output \(y\). Both the retriever and the encoder are differentiable and the model parameters \(\theta\) and \(\phi\) can be optimized using stochastic gradient descent on the gradient of \(\log p(y\)|\(x)\) with respect to \(\theta\) and \(\phi\). To reduce the cost of retrieval and marginalization over all documents, it is approximated by only using the top \(k\) documents in descending order of \(p(z\)|\(x)\). To efficiently find the top \(k\) documents, the Maximum Inner Product Search (MIPS) algorithm is used, because the order of the relevance score \(f(x,z)=\mathrm{Embed}_{\mathrm{input}}(x)^\top\mathrm{Embed}_{\mathrm{doc}}(z)\) is equivalent to the order of \(p(z\)|\(x)\). To use MIPS, an efficient search index over pre-computed embeddings for every document must be constructed. However, during training, parameter updates on \(\theta\) will alter the embeddings and the index, making the search index “stale”. To mitigate the problem, the index is refreshed by asynchronously re-embedding and re-indexing all documents every several hundred training steps. On the other hand, the \(p(z\)|\(x)\) and its gradient are recomputed using fresh \(\theta\) for the top \(k\) documents after retrieval in every training step. The asynchronous MIPS refresh is implemented by two parallel running jobs: a primary trainer job for gradient updates and a secondary index builder job for re-embedding and re-indexing. The asynchronous refresh is used only for pre-training; for fine-tuning, the MIPS index is built only once using the pre-trained \(\theta\) and the \(\mathrm{Embed}_{\mathrm{doc}}\) is not updated, while the query side \(\mathrm{Embed}_{\mathrm{input}}\) is still fine-tuned. What the retriever learns during the pre-training is that a document \(z\) receives a positive update whenever it performs better than expected from random sampling.
Four inductive biases in pre-training are shown to be helpful to the performance of the retriever: (1) salient spans such as named entities and dates within a sentence are selected for masking, (2) an empty null document is added to the top \(k\) retrieved documents for appropriate weight to be assigned to the case when no retrieval is necessary, (3) trivial retrieval candidates, meaning documents containing the exact sentence of a masked sentence, are excluded during pre-training, (4) \(\mathrm{Embed}_{\mathrm{input}}\) and \(\mathrm{Embed}_{\mathrm{doc}}\) are warm-started using Inverse Cloze Task (ICT) where, given a sentence, the model is trained to retrieve the document where the sentence came from. The encoder is warm-started with pre-trained BERT-based models.
Open-QA task is chosen to evaluate the REALM, because the inputs do not contain hinting context and the questions reflect more realistic information-seeking needs. The evaluation is based on exact match with reference answer. Three Open-QA benchmark datasets are used: NaturalQuestions-Open, WebQuestions, and CuratedTrec. The results of REALM are compared with those from several heuristic retrieval-based approaches, ORQA, a learnable retrieval-based approach, and T5 generation-based approaches. The documents of knowledge corpus are split into chunks of up to 288 BERT wordpieces, resulting in over 13 million retrieval candidates. REALM outperforms all previous approaches by a significant margin. The largest T5-11B model outperforms the previous best Open-QA system. But REALM outperforms the largest T5-11B model while being 30 times smaller. The improvement of REALM over ORQA is purely due to better pre-training methods. Both the encoder and retriever benefit from REALM training separately, but the best result requires both components acting in unison. REALM is able to retrieve some documents with a related fact to fill in the masked word in the MLM pre-training task. REALM also offers a set of model-centric unsupervised alignments between text in the pre-training corpus \(\mathcal{X}\) and knowledge corpus \(\mathcal{Z}\).
RAG
Lewis et al., 2020[28] introduce RAG (Retrieval-Augmented Generation) model that combines a pre-trained knowledge access mechanism with a pre-trained seq2seq generator model and is fine-tuned end-to-end. The figure below illustrates the approach with 3 example tasks.
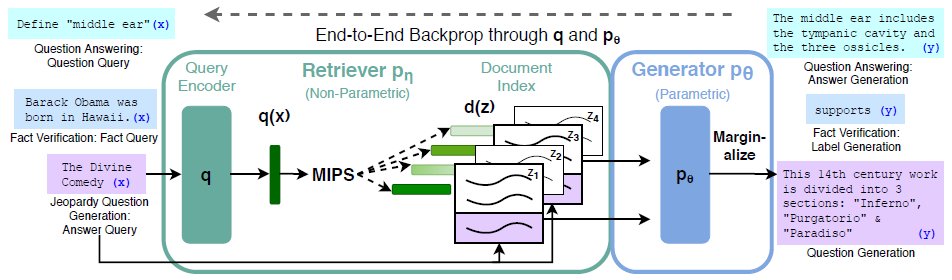
The input sequence \(x\) is used to retrieve text documents \(z\) which are then used as additional context to generate the target sequence \(y\). The model is composed of two components: (1) a retriever \(p_{\eta}(z|x)\) with parameters \(\eta\) that returns top-K truncated distributions over text passages given a query \(x\) and (2) a generator \(p_{\theta}(y_i|x,z,y_{1:i-1})\) parameterized by \(\theta\) that generates a current token based on a context of the previous \(i-1\) tokens \(y_{1:i-1}\), the original input \(x\), and a retrieved document \(z\). The retrieved document is treated as a latent variable in the end-to-end training of the retriever and generator. Two different ways of marginalizing over the latent documents are considered to produce a distribution over generated text: (1) RAG-Sequence that uses the same document to predict each target token of the complete generated sequence and (2) RAG-Token that can predict each target token based on a different latent document.
The RAG-Sequence treats the retrieved documents as a single latent variable that is marginalized to get the seq2seq probability \(p(y\)|\(x)\) via a top-K approximation. The retriever retrieves the top K documents and the generator produces the complete output sequence probability for each document, which are then marginalized.
\[p_{RAG-Sequence}(y|x)\approx\sum\limits_{z\in top-k(p(\cdot|x))}p_{\eta}(z|x)p_{\theta}(y|x,z)=\sum\limits_{z\in top-k(p(\cdot|x))}p_{\eta}(z|x)\prod\limits_{i}^{N}p_{\theta}(y_i|x,z,y_{1:i-1})\]The RAG-Token allows the generator to choose content from several documents when producing a token. The retriever retrieves the top K documents and then the generator produces a distribution for the next output token for each document before marginalizing. The process is repeated for the next output token.
\[p_{RAG-Token}(y|x)\approx\prod\limits_{i}^{N}\sum\limits_{z\in top-k(p(\cdot|x))}p_{\eta}(z|x)p_{\theta}(y_i|x,z_i,y_{1:i-1})\]RAG can be used for sequence classification tasks by considering the target class as a target sequence of length one, in which case RAG-Sequence and RAG-Token are equivalent. The retriever component follows a bi-encoder architecture of DPR[30]:
\[p_{\eta}(z|x)\propto\exp(\mathrm{d}(z)^{\top}\mathrm{q}(x))\qquad \mathrm{d}(z)=\mathrm{BERT}_d(z),\mathrm{q}(x)=\mathrm{BERT}_q(x)\]where \(\mathrm{d}(z)\) is a dense representation of a document produced by a \(\mathrm{BERT}_{\mathrm{BASE}}\) document encoder, and \(\mathrm{q}(x)\) a query representation produced by a query encoder, also based on \(\mathrm{BERT}_{\mathrm{BASE}}\). Finding \(top-k(p_{\eta}(\cdot\)|\(x))\) is a Maximum Inner Product Search (MIPS) problem that can be solved approximately in sub-linear time[29]. A pre-trained bi-encoder from DPR is used to initialize RAG’s retriever and to build the document index that is referred to as the non-parametric memory in this study. The generator component \(p_{\theta}(y_i\)|\(x,z,y_{1:i-1})\) is modelled with a pre-trained \(\mathrm{BART}_{large}\). The input \(x\) and the retrieved content \(z\) are concatenated as the input for the generator. The generator parameters \(\theta\) is referred to as parametric memory in this study. The two components are jointly fine-tuned for downstream tasks. Given a fine-tuning training corpus of input/output pairs \((x_j, y_j)\), the objective is to minimize the negative marginal log-likelihood of each target, \(\sum_j-\log p(y_j\)|\(x_j)\) using stochastic gradient descent. During fine-tuning training, document encoder \(\mathrm{BERT}_d\) and document index are fixed, only the query encoder \(\mathrm{BERT}_q\) and the \(\mathrm{BART}\) generator are fine-tuned.
At test time, RAG-Sequence and RAG-Token use different ways to approximate \(\arg\max_y p(y\)|\(x)\). The RAG-Token is a standard autoregressive seq2seq generator with the transition probability below, which can be plugged into a standard beam detector.
\[p'_{\theta}(y_i|x,y_{1:i-1})=\sum\limits_{z\in top-k(p(\cdot|x))}p_{\eta}(z|x)p_{\theta}(y_i|x,z_i,y_{1:i-1})\]The RAG-Sequence cannot solve the max likelihood with a single beam search. The set of candidate tokens of a beam search for a document may not be a candidate for other documents. For “Thorough Decoding”, an additional forward pass for each document \(z\) is run to estimate \(p_{\theta}(y\)|\(x,z_i)\) for which \(y\) does not appear in the beam, multiplied with generator probability \(p_{\eta}(z\)|\(x)\), and summed up across beams for the documents. For “Fast Decoding”, it is assumed that \(p_{\theta}(y\)|\(x,z_i)\approx 0\) for \(y\) not in the beam and no additional forward pass is run.
A single Wikipedia dump from December 2018 is used as non-parametric knowledge source. Each Wikipedia article is split into disjoint 100-word chunks (documents). Each document is encoded into an embedding and MIPS index is built using FAISS[29]. Efficient approximate nearest neighbor search is done using hierarchical navigable small world graphs[31]. For top k documents, \(k\in\{5, 10\}\) are considered.
The RAG models are evaluated with 4 types of knowledge-intensive tasks: (1) Open-domain Question Answering, (2) Abstractive Question Answering, (3) Jeopardy Question Generation, and (4) Fact Verification. Four open-domain QA datasets are used for the first task: Natural Questions (NQ), TriviaQA (TQA), WebQuestions (WQ), and CuratedTrec (CT). On all four datasets, RAG sets a new state of the art, exceeding either extractive QA paradigm (DPR, REALM) or “Closed-Book QA” (T5-11B+SSM[32]). RAG can generate correct answers even when the correct answer is not in any retrieved document. For abstractive QA, the MSMARCO NLG task v2.1 is used, which consists of questions, 10 gold passages per question, and a full sentence answer annotated from the passages. Only the questions and answers, not the passages, are used in this study. RAG outperforms BART, but significantly underperforms PALM. The third task is an open-domain question generation task where Jeopardy-style questions are generated given their answer entities as input. SearchQA dataset is used and Q-BLEU-1 score is measured. In addition, two human evaluations are used to measure factuality and specificity of the generated questions. RAG-Token performs better than RAG-Sequence on Jeopardy question generation, with both models outperforming BART on Q-BLEU-1. RAG generations are more factual and more specific than BART generations by large margins. For the 4th task, FEVER dataset is used, where a given natural language claim needs to be classified to be supported, refuted, or unverifiable from Wikipedia alone. RAG outperforms BART, but significantly underperforms current state-of-the-art models.
The generation diversity is measured by the ratio of distinct trigrams to total trigrams generated. RAG-Sequence’s generations are more diverse than RAG-Token’s, and both are significantly more diverse than BART without needing any diversity-promoting decoding. Retrieval ablation studies show that RAG’s learned retrieval improves results on all tasks, especially for Open-Domain QA, where it is crucial. An advantage of non-parametric memory models like RAG is that knowledge can be easily updated at test time, such as index hot-swapping. Retrieving more documents at test time monotonically improves Open-domain QA results for RAG-Sequence, but performance peaks for RAG-Token at 10 retrieved documents. RAG is the first model to show that a single retrieval-augmented architecture is capable of achieving strong performance across several tasks.
FiD
Izacard and Grave, 2020a[34] introduce FiD (Fusion-in-Decoder) model that modifies RAG by performing evidence fusion in the decoder. The model consists of two modules: (1) the retriever selects support passages from a large knowledge source and (2) the reader (using an encoder-decoder architecture) processes the retrieved passages, along with the question, to generate an answer. Two retrieval methods, BM25 or DPR, are used for different downstream tasks. In BM25 (a variant of TF-IDF), passages are represented as bag of words, and the ranking function is based on term and inverse document frequencies. In DPR, passages and questions are represented as dense vectors, computed using two BERT networks, and the ranking function is the dot product between the question and passage representations. Retrieval is performed using approximate nearest neighbors with the Facebook Research FAISS library. The reader is initialized from a pre-trained T5 seq2aeq network that takes as input the question and the support passages and generates the answer for open domain question answering tasks. Each retrieved passage and its title are concatenated with the question, and processed independently from other passages by the encoder. Special tokens \(\mathrm{question}\):, \(\mathrm{title}\):, and \(\mathrm{context}\): are added before the question, title, and text of each passage. The resulting representations of all the retrieved passages are concatenated into a single representation that is passed through the cross-attention mechanism of the decoder, as illustrated in the figure below.

Processing passages independently in the encoder allows to scale to large number of contexts, as it only performs self-attention over one context at a time. On the other hand, processing passages jointly in the decoder allows to better aggregate evidence from multiple passages. Two model sizes, base and large, are considered with 220M and 770M parameters, respectively.
Three open domain QA datasets, NaturalQuestions (NQ), TriviaQA, and SQuAD v1.1 are used to evaluate the models. The evidence corpus for retrieval is Wikipedia dumps of December 20, 2018 for NQ and TriviaQA and of December 21, 2016 for SQuAD. Preprocessing is applied to obtain non-overlapping passages of 100 words. Predicted answers are evaluated with the standard exact match metric (EM). The fine-tuning of the models on each dataset is done independently. For both training and testing, 100 passages are retrieved and each is truncated to 250 wordpieces. Passages are retrieved with dense representations for NQ and TriviaQA and with sparse representations for SQuAD. Greedy decoding is used for answer generation.
FiD outperforms existing work, including GPT-3, T5, REALM, and RAG on the NQ and TriviaQA benchmarks. Experiments on the number of retrieved passages at both fine-tuning training and test time show that increasing the number of passages from 10 to 100 leads to 6% improvement on TriviaQA and 3.5% improvement on NQ. On the other hand, the performance of most extractive models seems to peak around 10 to 20 passages, suggesting that sequence-to-sequence models are good at combining information from multiple passages. Reducing the number of retrieved passages at training time. but not test time (kept at 100), leads to a decreased performance.
Retriever-Enhanced FiD
Izacard and Grave, 2020b[35] further improve the FiD model by leveraging the cross-attention score of the reader as the target to train the retriever. It is hypothesized that the cross-attention score from an output (answer) to an input (retrieved passages) of the reader is a good proxy for the relevance of the retrieved passages to the question that the answer is paired with, that is, the more the tokens in a text segment are attended to, the more relevant the text segment is to answer the question. This training scheme can be seen as a student-teacher pipeline, where the reader is the teacher, the retriever is the student, and the knowledge of cross attention scores of the reader is distilled to teach the retriever to select the most relevant passages.
In the reader, the encoder independently processes \(n_p\) different inputs \((s_k)_{1\leq k\leq n_p}\) where each input \(s_k\) is the concatenation of the question \(q\) and the title and text of a support passage. The output of the encoder are then concatenated to form a global representation \(\mathrm{X}\) of dimension \((\sum_{k}l_k)\times d\), where \(l_k\) is the length of the \(k\)-th segment and \(d\) is the dimension of the embeddings and hidden representations of the model. The decoder then processes \(\mathrm{X}\) as a regular autoregressive model, alternating self-attention, cross-attention, and feed-forward layers. Only the cross-attention explicitly takes \(\mathrm{X}\) as input. Let \(\mathrm{H}\in\mathrm{\mathbb{R}}^d\) denote the output of the previous self-attention layer of the decoder, the cross-attention first applies linear transformation to compute queries \(\mathrm{Q}\), keys \(\mathrm{K}\), and values \(\mathrm{V}\): \(\mathrm{Q}=\mathrm{W}_Q\mathrm{H}\), \(\mathrm{K}=\mathrm{W}_K\mathrm{X}\), \(\mathrm{V}=\mathrm{W}_V\mathrm{X}\). For the \(i\)-th token in the query, \(\mathrm{Q}_i\), and the \(j\)-th token in the key, \(\mathrm{K}_j\), the cross-attention score \(\alpha_{i,j}\) and the cross-attention probability \(\tilde\alpha_{i,j}\) are
\[\alpha_{i,j}=\mathrm{Q}_i^{\top}\mathrm{K}_j,\quad\quad \tilde\alpha_{i,j}=\frac{\exp(\alpha_{i,j})}{\sum_m\exp(\alpha_{i,m})}.\]The values weighted by the cross-attention probability are summed up and then linearly transformed to obtain the output of cross-attention: \(\mathrm{O}_i=\mathrm{W}_O\sum_j\tilde\alpha_{i,j}\mathrm{V}_{i,j}\). The per head operations above are performed in parallel for multi-head attention, followed by layer normalization and skip connection. Given a question \(q\) and a corresponding set of support passages \(\mathcal{D}_q=(p_k)_{1\leq k\leq n}\), the relevance score \((G_{q,p_k})_{1\leq k\leq n}\) for each passage is obtained by averaging the attention scores \(\alpha_{0,:}\) from the first output token to all the tokens in the input \(s_k\) corresponding to the passage \(p_k\) over all the layers and all the heads of the decoder. The score \(G_{q,p_k}\) of the \(k\)-th passage depends on the other passages that are jointly processed by the FiD decoder.
In the retriever, an embedder function \(E\) maps any text passage to a \(d\)-dimensional vector, such that the similarity score between a question \(q\) and a passage \(p\) is defined as \(S_{\theta}(q,p)=E(q)^{\top}E(p)\). This similarity metric enables a preprocessing step to index all passages in the knowledge source. Then at runtime, passages with the highest similarity score with the input question are retrieved, by using an efficient similarity search library FAISS. BERT is used as the embedder in this study and the representation (\(d=768\) in BERT\(_{\mathrm{BASE}}\)) of the initial \(\mathrm{[CLS]}\) token is used for the encodings \(E(q)\) and \(E(p)\). The same encoding function \(E\) is used for both the questions and passages, in this study, by sharing parameters. Three training objectives of the retriever are compared: (1) to minimize the KL-divergence between the output \(S_{\theta}(q,p)\) and the score \(G_{q.p}\) after normalization:
\[\mathcal{L}_{\mathrm{KL}}(\theta,\mathcal{Q})=\sum\limits_{q\in\mathcal{Q},p\in\mathcal{D}_q}\tilde{G}_{q,p}(\log\tilde{G}_{q,p}-\log\tilde{S}_{\theta}(q,p)),\] \[where \quad\quad\tilde{G}_{q,p}=\frac{\exp(G_{q,p})}{\sum_{p'\in\mathcal{D}_q}\exp(G_{q,p'})},\quad\quad\tilde{S}_{\theta}(q,p)=\frac{\exp(S_{\theta}(q,p))}{\sum_{p'\in\mathcal{D}_q}\exp(S_{\theta}(q,p'))};\](2) to minimize the mean squared error as a regression approach:
\[\mathcal{L}_{\mathrm{MSE}}(\theta,\mathcal{Q})=\sum\limits_{q\in\mathcal{Q},p\in\mathcal{D}_q}(S_{\theta}(q,p)-G_{q,p})^2,\]and (3) to use a max-margin loss that explicitly penalizes inversions in the ranking estimated by the retriever:
\[\mathcal{L}_{\mathrm{ranking}}(\theta,\mathcal{Q})=\sum\limits_{q\in\mathcal{Q},p_1,p_2\in\mathcal{D}_q}\max(0,\gamma-\mathrm{sign}(G_{q,p_1}-G_{q,p_2})(S_{\theta}(q,p_1)-S_{\theta}(q,p_2))).\]The third approach means that if \(p_1\) is more relevant to answer the question \(q\) than \(p_2\), i.e. \(G_{q,p_1}>G_{q,p_2}\), the loss pushes the retriever score of \(p_1\) to be larger than the score of \(p_2\) by at least a margin of \(\gamma\).
The student-teacher scheme is trained in a 4-step iterative procedure: (1) train the reader using the initial set of support documents for each question \(\mathcal{D}_q^0\), (2) compute aggregated attention scores \((G_{q,p})_{q\in\mathcal{Q},p\in\mathcal{D}_q^0}\) with the reader, (3) train the retriever using the scores \((G_{q,p})_{q\in\mathcal{Q},p\in\mathcal{D}_q^0}\), (4) retrieve top-k passages with the newly trained retriever. The procedure can be repeated multiple times. A critical point of the training procedure is the initial set of documents corresponding to each question. Three different ways of retrieving the \(\mathcal{D}_q^0\) are experimented: (1) BM25, (2) BERT (without fine-tuning), (3) DPR. Three different open-domain question answering datasets, NaturalQuestions (NQ), TriviaQA, and NarrativeQuestions, are used to evaluate the models. The iterative training procedure is applied on each dataset independently. 100 passages are used in training all retrievers.
The accuracy of the system increases with the number of iterations, obtaining strong performance after a few iterations. The quality of the initial document sets plays an important role on the performance of the end system, with the performance in descending order when starting from DPR > BM25 > BERT. When starting from DPR passages, the system outperforms the state-of-the-art on NQ and TriviaQA datasets. On NarrativeQuestions, the system starting from BM25 outperforms DPR+FiD.
Ablation studies show that the performance of the three training objectives is in the order of KL-divergence \(>\) max-margin loss \(\gg\) mean squared error. The cross-attention scores \(\alpha\) are aggregated in order to obtain a single scalar value \(G_{q,p}\) used to train the retriever. In addition to the average approach described above, 5 alternative aggregation schemes are compared. The performance is in the descending order: the average approach described above > taking the max over the heads instead of the average > taking the max over the layers instead of the average \(\approx\) taking the mean over the last six (7th ~ 12th) layers instead of all the layers > taking the average over the output tokens instead of taking the score of the first token > taking the max, instead of the average, over the input tokens corresponding to the input passage.
Combined Autoencoding and Autoregressive Language Models
The autoregressive models of GPT-subfamily lack an encoder to condition generation on context. The masked autoencoding models of BERT-subfamily lacks an autoregressive decoder for generation tasks. The denoising encoder-decoder models of BART has a learning objective mismatch between pre-training and fine-tuning on comprehension-based generation tasks like abstractive summarization, generative question answering, question generation, and conversational response generation. Some studies have tried to combine the merits of autoencoding and autoregression in a single model.
PALM
Bi et al., 2020[33] introduce PALM (Pre-training an Autoencoding&autoregressive Language Model) that improves pre-training for comprehension-based generation tasks by (1) joint modeling of autoencoding and autoregression, (2) minimizing the input/output representation discrepancy between self-supervised pre-training and supervised fine-tuning, and (3) incorporating mechanism of copying tokens from context.
Given a pair of text pieces \((x,y)\in(\mathcal{X},\mathcal{Y})\), where \(x=(x_1,x_2,...,x_m)\) is the source text with \(m\) tokens, \(y=(y_1,y_2,...,y_n)\) is the target text with \(n\) tokens, and \(\mathcal{X}\) and \(\mathcal{Y}\) are the sets of source and target text, respectively. PALM uses the standard Transformer encoder-decoder as the base architecture that maximizes the log-likelihood objective: \(\mathcal{L}(\theta;(\mathcal{X},\mathcal{Y}))=\sum_{(x,y)\in(\mathcal{X},\mathcal{Y})}\log P(y\)|\(x;\theta)\). PALM delegates autoencoding-based comprehension to the encoder and autoregressive generation to the decoder. The encoder and decoder are jointly pre-trained in two stages: in the first stage, the encoder is trained exactly like BERT; and in the second stage, the encoder and decoder are jointly trained to autoregressively generate text output with the context representations from the encoder, which maximizes the log-likelihood of the target token being the decoder’s output:
\[\mathcal{L}(\theta)=\sum\limits_{(x,y)\in(\mathcal{X},\mathcal{Y})}\log\prod\limits_{t=1}^{n}P(y_t|y_{<t},x;\theta).\]In a typical downstream comprehension-based generation task, context length is much longer than the output length. To mimic this, PALM uses the consecutive span of length \(80\%\cdot L\) from the beginning of the fragment of length \(L\) (composed of a few sentences) as context input to the encoder, and uses the remainder of text span of length \(20\%\cdot L\) as text output to be generated by the decoder. In this study, \(L\leq500\); the context input consists of at most 400 tokens and the text output consists of at most 100 tokens. The figure below compares PALM with GPT, MASS, and BART. In MASS and BART, the inputs to the encoder and the decoder come from the same text segment and the outputs are expected to be from the same text sequence. In PALM, the inputs to the encoder and the decoder are different.
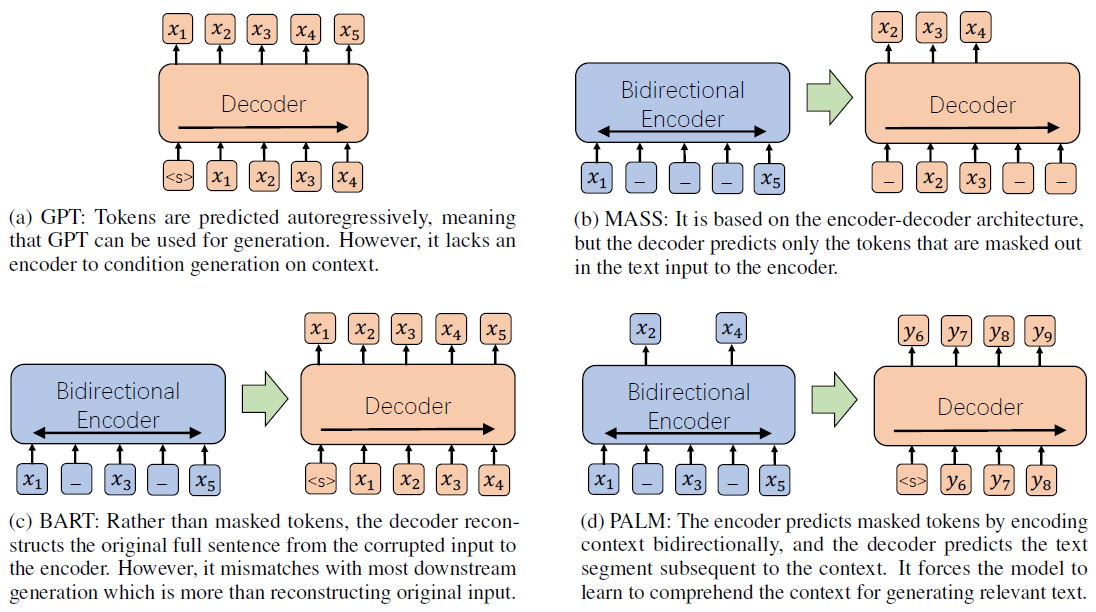
To increase coherence between generated text and context text, PALM incorporates a copy mechanism in pre-training by plugging in the pointer-generator network on top of the decoder. As illustrated in the figure below, the pointer-generator network allows every token to be either generated from the vocabulary or copied from context. The two distributions are summed in a weighted manner to obtain the final distribution.
The probability distribution of the \(t\)-th word token \(y_t\) over the vocabulary \(V\) is defined as \(P^v(y_t)=\mathrm{softmax}(W^e(W^vs_t+b^v)),\) where \(s_t\) denotes the output representation of \(t\)-th token from the decoder. The output embedding \(W^e\) is tied with the corresponding part of the input embedding, and \(W^v\) and \(b^v\) are learnable parameters. PALM uses an additional attention layer for the copy distribution on top of the decoder, which takes \(s_t\) as the query, outputs \(\alpha_t\) as the attention weights and \(z_t^c\) as the context vector: \(e_{tl}^c=w^{c\top}\tanh(W^mh_l^c+W^ss_t+b^c)\), \(\alpha_t^c=\mathrm{softmax}(e_t^c)\), \(z_t^c=\sum\limits_{l=1}^m\alpha_{tl}^ch_l^c\), where \(h_l^c\) is the representation of \(l\)-th token in context from the encoder. \(w^c\), \(b^c\), \(W^m\), and \(W^s\) are learnable parameters. The copy distribution over the vocabulary is defined as \(P^c(y_t)=\sum\limits_{l:x_l=y_t}\alpha_{tl}^c\). The final probability of generating \(y_t\) is defined as \(P(y_t)=\lambda P^v(y_t)+(1-\lambda)P^c(y_t)\), \(\lambda=\mathrm{sigmoid}(w^zz_t^c+w^ss_t+b^m)\), where \(w^z\), \(w^s\), and \(b^m\) are learnable parameters. The parameters in pointer-generator learned in pre-training are all kept and passed downstream for fine-tuning on labeled data.
PALM consists of 12-layer encoder and 12-layer decoder with embedding/hidden size \(d_h\)=768, feed-forward filter size \(d_{ff}\)=3072, and number of attention heads \(H\)=12. A larger model PALM\(_{\mathrm{LARGE}}\) consists of 24-layer encoder and 6-layer decoder with \(d_h\)=1024 and \(H\)=16. The parameters of PALM’s encoder are initialized by the pre-trained RoBERTa model. English Wikipedia and BookCorpus are used as pre-training corpus and tokenized using WordPiece. Multiple consecutive sentences up to 400 tokens are used as the source text input to the encoder and subsequent consecutive sentences up to 100 tokens as the target text to the decoder. The pre-training dataset \((\mathcal{X},\mathcal{Y})\) is constructed from the documents by a sliding window with the stride of one sentence, resulting in 50M \((x,y)\) pre-training pairs. The text generation quality of pre-trained models of PALM and MASS are evaluated by perplexity of the continuation of the input sentences by beam search with a beam of size 5 on CNN news dataset. The overall perplexity of PALM is 17.22, which is much better than MASS’s perplexity of 170.32.
Fine-tuning on generative QA is evaluated on the MARCO dataset that consists of questions, contextual passages, and answers. The answers are human-generated and not necessarily sub-spans of the contextual passages. A contextual passage concatenated with a question at the end is used as input to PALM encoder; the corresponding answer is used as input to PALM decoder. The ROUGE-L is used as metric to measure the quality of generated answers against the ground truth. During decoding, beam search with a beam of size 5 is used. PALM achieves the first place on the official MARCO leaderboard as of December 9, 2019. Fine-tuning on abstractive summarization is evaluated on both the CNN/DailyMail and the Gigaword datasets. Articles are used as input to the encoder and the corresponding summaries are used as input to the decoder. The F1 scores of Rouge-1, Rouge-2 and Rouge-L are reported on the test set of both datasets for evaluation. PALM\(_{\mathrm{LARGE}}\) achieves better performance than all strong summarization models, including UniLM\(_{\mathrm{LARGE}}\), T5\(_{\mathrm{LARGE}}\), BART\(_{\mathrm{LARGE}}\), PEGASUS, and ERNIE-GEN\(_{\mathrm{LARGE}}\). Answer-aware question generation task is to generate a question, given an input passage and an answer span. Fine-tuning on question generation is evaluated on SQuAD 1.1 dataset and the BLEU-4, METEOR, and ROUGE-L metrics are used for evaluation. PALM\(_{\mathrm{LARGE}}\) outperforms all previous question generation systems and achieves a new state-of-the-art result on BLEU-4 and ROUGE-L for question generation on the SQuAD 1.1 dataset. Conversational response generation task is to produce a flexible response to a conversation. Fine-tuning on response generation is evaluated on Cornell Movie Dialog corpus that contains 140K conversation pairs. The perplexity of the results is used as the metric. PALM significantly outperforms all the competitors by a large margin.
Ablation studies show that the pointer-generator network contributes insignificantly to the downstream task performance, but both the autoencoding and autoregression components are critical to the downstream task performance.
Codes
- Transformers or Transformers
- Transformer-XL
- minGPT
- GPT-2
- GPT-3
- Calibration of Few-Shot Learning
- BERT
- RoBERTa
- ALBERT
- ELECTRA
- XLNet
- T5
- BART or BART
- mBART
- MARGE
- mT5
- RAG
References
[1] Bahdanau, D., Cho, K., and Bengio, Y. (2014) Neural machine translation by jointly learning to align and translate. arXiv:1409.0473.
[2] Chorowski, J., Bahdanau, D., Cho, K., and Bengio, Y. (2014) End-to-end continuous speech recognition using attention-based recurrent NN: First results. CoRR, vol. abs/1412.1602.
[3] Cheng, J., Dong, L., and Lapata, M. (2016) Long short-term memory-networks for machine reading. In: Proc. EMNLP, 551–561.
[4] Parikh, A., Täckström, D., Das, D., and Uszkoreit, J. (2016) A decomposable attention model for natural language inference. In: Proc. EMNLP, 2249–2255.
[5] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., and Polosukhin, I. (2017) Attention is all you need. In: Advances in Neural Information Processing Systems, 6000–6010.
[6] Sennrich, R., Haddow, B., Birch, A. (2016) Neural Machine Translation of Rare Words with Subword Units. arXiv preprint arXiv:1508.07909
[7] Wu, Y., Schuster, M., Chen, Z., Le, Q., Norouzi, M., Macherey, W., Krikun, M., Cao, Y., Gao, Q., Macherey, K., et al. (2016) Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144
[8] Radford, A., Narasimhan, K., Salimans, T., Sutskever, I. (2018) Improving Language Understanding by Generative Pre-Training.
[9] Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. R. (2018) GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461
[10] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I. (2019) Language Models are Unsupervised Multitask Learners.
[11] Brown, T. B., et al. (2020) Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165
[12] Child, R., Gray, S., Radford, A., and Sutskever, I. (2019) Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509
[13] Devlin, J., Chang, M., Lee, K., Toutanova, K. (2019) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805v2
[14] Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., et al. (2019) RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692
[16] Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R., and Le, Q. (2019) XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv preprint arXiv:1906.08237
[17] Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q., and Salakhutdinov, R. (2019) Transformer-XL: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860
[18] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. (2020) Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research 21:1-67
[19] Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O. (2020) BART: Denoising sequence-to-sequence pretraining for natural language generation, translation, and comprehension. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 7871–7880.
[20] Zhao, T., Wallace, E., Feng, S., Klein, D., Singh, S. (2021) Calibrate Before Use: Improving Few-Shot Performance of Language Models. arXiv preprint arXiv:2102.09690
[21] Guu, K., Lee, K., Tung, Z., Pasupat, P., Chang, M. (2020) REALM: Retrieval-Augmented Language Model Pre-Training. arXiv preprint arXiv:2002.08909
[22] Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., Soricut, R. (2019) ALBERT: A Lite BERT for Self-supervised Learning of Language Representations arXiv preprint arXiv:1909.11942
[23] Clark, K., Luong, M., Le, Q., Manning, C. (2020) ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators arXiv preprint arXiv:2003.10555
[24] Liu, Y., Gu, J., Goyal, N., Li, X., Edunov, S., Ghazvininejad, M., Lewis, M., Zettlemoyer, L. (2020) Multilingual Denoising Pre-training for Neural Machine Translation arXiv preprint arXiv:2001.08210
[25] Lewis, M., Ghazvininejad, M., Ghosh, G., Aghajanyan, A., Wang, S., Zettlemoyer, L. (2020) Pre-training via Paraphrasing arXiv preprint arXiv:2006.15020
[26] Xue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., Barua, A., Raffel, C. (2020) mT5: A massively multilingual pre-trained text-to-text transformer arXiv preprint arXiv:2010.11934
[27] Shazeer, N. (2020) GLU Variants Improve Transformer arXiv preprint arXiv:2002.05202
[28] Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., et al. (2020) Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks arXiv preprint arXiv:2005.11401
[29] Johnson, J., Douze, M., and Jégou, H. (2017) Billion-scale similarity search with GPUs arXiv preprint arXiv:1702.08734
[30] Karpukhin, V., Oguz, B., Min, S., Wu, L., Edunov, S., Chen, D., and Yih, W. (2020) Dense Passage Retrieval for Open-Domain Question Answering arXiv preprint arXiv:2004.04906
[31] Malkov, Y. A., Yashunin, D. A. (2016) Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs IEEE Transactions on Pattern Analysis and Machine Intelligence, 42:824–836, arXiv preprint arXiv:1603.09320
[32] Roberts, A., Raffel, C., and Shazeer, N. (2020) How Much Knowledge Can You Pack Into the Parameters of a Language Model? arXiv preprint arXiv:2002.08910
[33] Bi, B., Li, C., Wu, C., Yan, M., Wang, W., Huang, S., Huang, F., Si, L. (2020) PALM: Pre-training an Autoencoding&Autoregressive Language Model for Context-conditioned Generation arXiv preprint arXiv:2004.07159
[34] Izacard, G., Grave, E. (2020a) Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering arXiv preprint arXiv:2007.01282
[35] Izacard, G., Grave, E. (2020b) Distilling Knowledge from Reader to Retriever for Question Answering arXiv preprint arXiv:2012.04584